教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点:
之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以我决定自己动手搞一搞.
爬取已经完成,文末有 python的源码和妹子图片的百度云地址
二.准备:
爬虫还是要用python(之前用过一个国人大牛写的java爬虫框架 webmagic),所以花了点时间看了下网上python的教程,语法什么的(当然什么都没记住~),然后看了看scrapy这个爬虫框架,大概了解了其中各个组件的作用,每个组件的作用和爬取数据的几个步骤.
三.思路分析:
知乎二胖哥的思路大致如下:
- 1 手动找到部分宅男, 抓取他们关注的女性用户 和 部分问题的女性回答者
作为 "初始美女"群体 - 2 抓取 "初始美女" 所有的粉丝, 作为 "宅男群体"
- 3 再抓取 "宅男群体" 关注的人里面取top 1000, 得到知乎最受欢迎的美女.
我和二胖哥的目的有所不同,
二胖是要找到最受欢迎的妹子,
而我的目的是: - 1 学习使用python 的 scrapy框架
- 2 爬取精彩又性感的文章和图片.
所以我通过两个方面开始爬取: - 某些女生回答的多的问题, 比如: 拥有大长腿是怎样的感觉?
- 收藏夹. 知乎有收藏夹功能,把不同问题下的答案放到一个收藏加下.我关注了一个叫做
知乎妹子爆照合集的收藏夹
我大概爬取了12G的图片资源(因为我的服务器只有12G的剩余空间了...)
我存储图片的目录是按照 问题id/回答id的格式存放的.
四.收藏夹里的问题很多,大致目录如下:

五.手动指定了几个问题如下:
指定的问题:
基本上这些问题都是妹子爆照多的话题,有不少妹子照片.

目录结构:

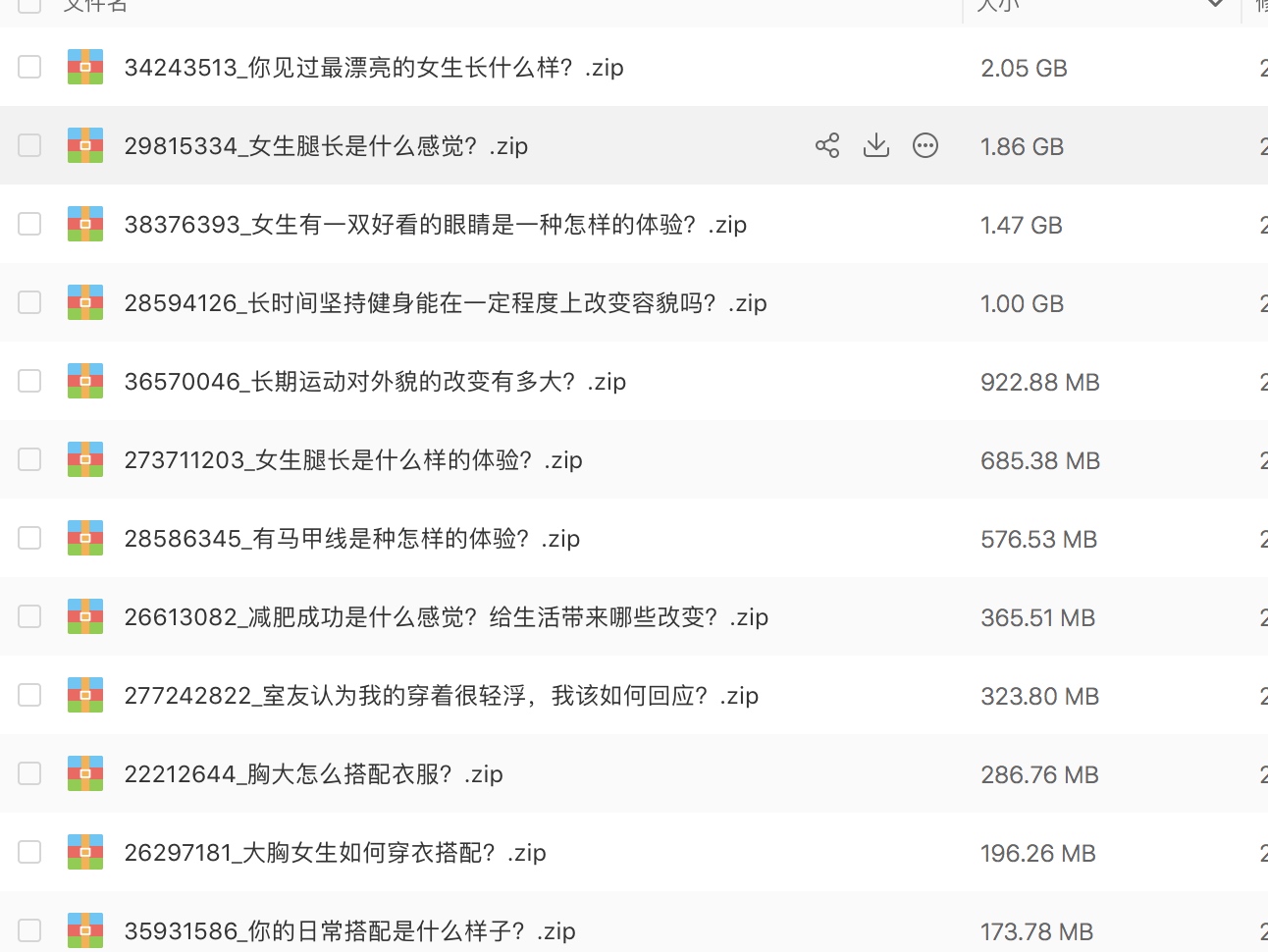
六.成果展示:

 

 

 

七.爬取方法介绍:
爬取网页(知乎)信息大概分为以下几个步骤:
- 确定爬取的初始页面(url地址)
- 确定要爬取哪些内容,使用xpath获取爬取内容的html文档路径获取内容.(或者能够从页面找到ajax调用后台的接口,去调接口拿到数据,一般返回的json格式,比使用xpath方便.)
- 爬取到内容的处理, 存数据库(mysql,mongo,等),落地到文件,等~
八.爬取教程分享
python scrapy爬虫框架概念介绍(个人理解总结为一张图)
python scrapy 登录知乎过程
使用python scrapy爬取知乎提问信息
python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
九.福利分享
如果有同学对python的爬虫代码和妹子图片感兴趣,
我已上传,关注微信公众号:程序员灯塔 (code12306)
回复 '知乎源码',获取python源码
回复 '知乎美女',获取12G图片资源的百度网盘地址.
程序员灯塔,关注互联网+大数据技术. 分享面试攻略+技术干货!
教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!的更多相关文章
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书
1.初衷:想在网上批量下载点听书.脱口秀之类,资源匮乏,大家可以一试 2.技术:wireshark scrapy jsonMonogoDB 3.思路:wireshark分析移动APP返回的各种连接分类 ...
- scrapy实战--爬取最新美剧
现在写一个利用scrapy爬虫框架爬取最新美剧的项目. 准备工作: 目标地址:http://www.meijutt.com/new100.html 爬取项目:美剧名称.状态.电视台.更新时间 1.创建 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
随机推荐
- google 身份验证器
谷歌身份验证器原理 就是服务器与客户端算法相同
- (转)关于CNN中平移不变性的理解
https://www.quora.com/Why-and-how-are-convolutional-neural-networks-translation-invariant https://st ...
- Semaphore 与ThreadPoolExecutor 的使用
1. Semaphore 信号量 (阻塞) 优点:可以控制线程的数量,不会超出线程范围 缺点:当线程死锁时,永远没法释放,导致一直阻塞 在java中,提供了信号量Semaphore的支持. Sema ...
- 西门子PLC-1200 SCL语言开发学习笔记 (一)
一.简介和背景 PLC一般使用梯形图开发,但是梯形图适合电工使用而不是程序员使用,对我们来说开发困难,门槛高,幸好PLC的开发标准还带了类pascal的高级语言,在西门子这里叫SCL语言,这对于我们程 ...
- php持续推送信息到客户端的方法
<?php set_time_limit(0); $i=1; while($i++) { echo $i,'<br />'; ob_flush();//冲刷出(送出)输出缓冲区中的内 ...
- xshell与xftp使用注意
1.xshell报ssh服务器拒绝了密码,请再试一次 xshell登录使用的用户名不能是root,要是服务器的用户名,否则连接时会报 ssh服务器拒绝了密码,请再试一次.将root改成服务器用户名即可 ...
- [IOI2014] 假期
Description 有\(N(N\leq 10^5)\)个排列在一条线上的城市,每个城市有\(val_i\)个景点.每天你可以选择在当前城市\(i\)游览景点,或者前往城市\(i-1\)或城市\( ...
- c# 获取当前绝对路径
/// <summary> /// 获得当前绝对路径 /// </summary> /// <param name="strPath">指定的路 ...
- JDK源码解析之Java SPI机制
1. spi 是什么 SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件. 系统设计的各个抽象,往往 ...
- Java使用foreach语句对数组成员遍历输出
/** * 本程序使用foreach语句对数组成员进行遍历输出 * @author Lei * @version 2018-7-23 */ public class ForeachDemo { pub ...