sklearn神经网络分类
sklearn神经网络分类
神经网络学习能力强大,在数据量足够,隐藏层足够多的情况下,理论上可以拟合出任何方程。
理论部分
sklearn提供的神经网络算法有三个:
neural_network.BernoulliRBM,neural_network.MLPClassifier,neural_network.MLPRgression
我们现在使用MLP(Multi-Layer Perception)做分类,回归其实也类似。该网络由三部分组成:输入层、隐藏层、输出层,其中隐藏层的个数可以人为设定。神经网络学习之后的知识都存在每一层的权重矩阵中,学习的过程也就是不断训练权重达到拟合的效果。权重训练比较常用的方法是反向传递(Backpropagation)

分类代码
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
import numpy as np
from sklearn.preprocessing import StandardScaler
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类
data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
scaler = StandardScaler()
X = data[['sepal length (cm)','sepal width (cm)']]
scaler.fit(X)
#标准化数据集
X = scaler.transform(X)
Y = data[['class']]
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
mpl = MLPClassifier(solver='lbfgs',activation='logistic')
mpl.fit(X_train, Y_train)
print 'Score:\n',mpl.score(X_test, Y_test) #score是指分类的正确率
#区域划分
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X[Y['class']==0,0]
class1_y = X[Y['class']==0,1]
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class2_x = X[Y['class']==1,0]
class2_y = X[Y['class']==1,1]
l2 = plt.scatter(class2_x,class2_y,color='r',label=iris.target_names[1])
class3_x = X[Y['class']==2,0]
class3_y = X[Y['class']==2,1]
l3 = plt.scatter(class3_x,class3_y,color='g',label=iris.target_names[2])
plt.legend(handles = [l1, l2,l3], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
测试结果
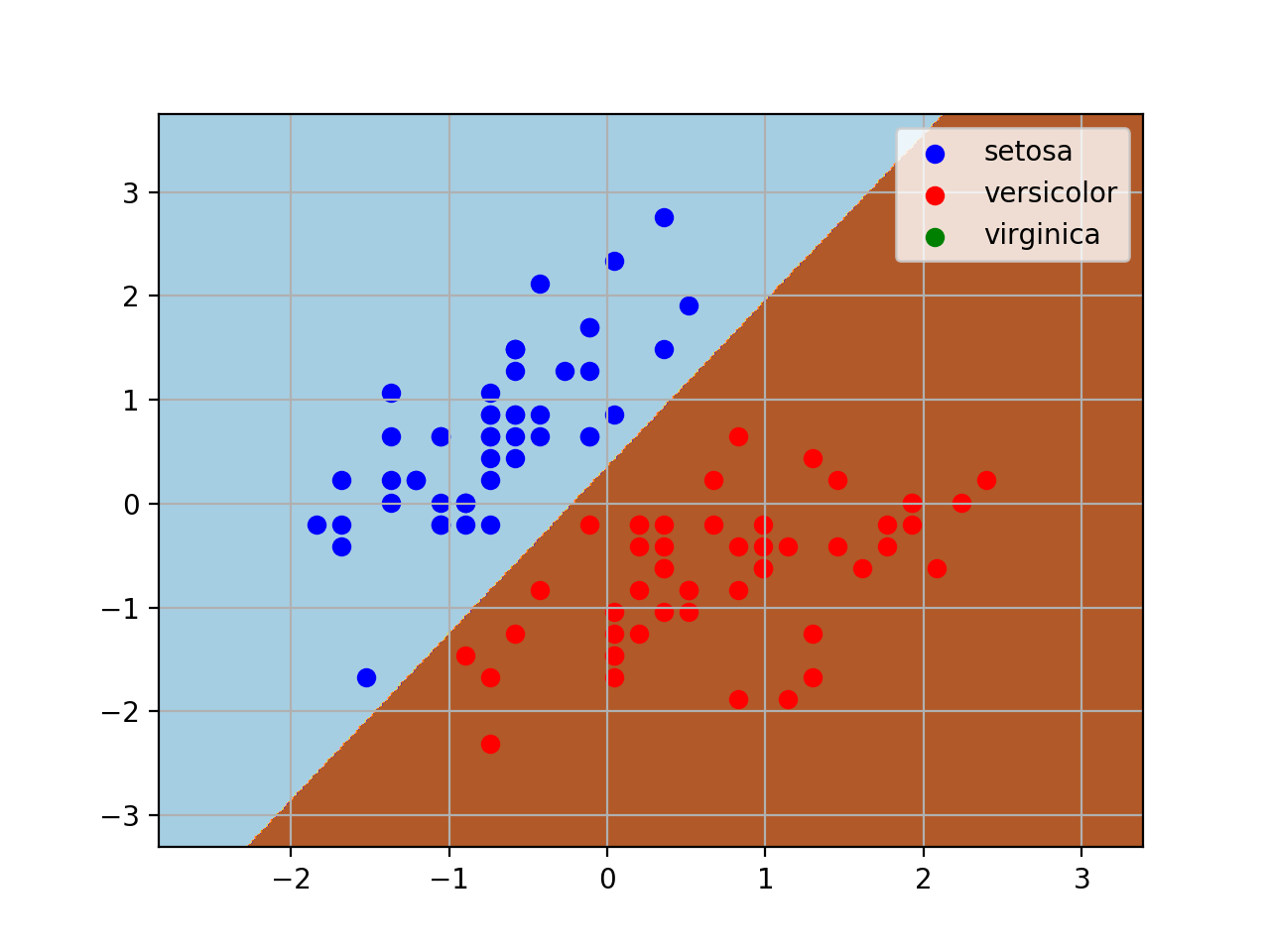
sklearn神经网络分类的更多相关文章
- [转载]sklearn多分类模型
[转载]sklearn多分类模型 这篇文章很好地说明了利用sklearn解决多分类问题时的implement层面的内容:https://www.jianshu.com/p/b2c95f13a9ae.我 ...
- sklearn解决分类问题(KNN,线性判别函数,二次判别函数,KMeans,MLE,人工神经网络)
代码:*******************加密中**************************************
- sklearn多分类问题
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Sklearn中二分类问题的交叉熵计算
二分类问题的交叉熵 在二分类问题中,损失函数(loss function)为交叉熵(cross entropy)损失函数.对于样本点(x,y)来说,y是真实的标签,在二分类问题中,其取值只可能为集 ...
- matlab练习程序(神经网络分类)
注:这里的练习鉴于当时理解不完全,可能会有些错误,关于神经网络的实践可以参考我的这篇博文 这里的代码只是简单的练习,不涉及代码优化,也不涉及神经网络优化,所以我用了最能体现原理的方式来写的代码. 激活 ...
- SKlearn中分类决策树的重要参数详解
学习机器学习童鞋们应该都知道决策树是一个非常好用的算法,因为它的运算速度快,准确性高,方便理解,可以处理连续或种类的字段,并且适合高维的数据而被人们喜爱,而Sklearn也是学习Python实现机器学 ...
- sklearn调用分类算法的评价指标
sklearn分类算法的评价指标调用#二分类问题的算法评价指标import numpy as npimport matplotlib.pyplot as pltimport pandas as pdf ...
- tensorflow RNN循环神经网络 (分类例子)-【老鱼学tensorflow】
之前我们学习过用CNN(卷积神经网络)来识别手写字,在CNN中是把图片看成了二维矩阵,然后在二维矩阵中堆叠高度值来进行识别. 而在RNN中增添了时间的维度,因为我们会发现有些图片或者语言或语音等会在时 ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
随机推荐
- mongodb实现自增的方法
前面操作看菜鸟教程 function getNextSequenceValue(sequenceName){ var sequenceDocument = Counter.findOneAndUpda ...
- Atcoder ARC101 Ribbons on Tree
题解: 前面牛客网的那个比赛也有一道容斥+dp 两道感觉都挺不错的 比较容易想到的是 f[i][j]表示枚举到了i点,子树中有j个未匹配 这样的话我们需要枚举儿子中匹配状态 这样是n^2的(这是个经典 ...
- python全栈开发day82-modelForm
1.jsonp内容 from django.shortcuts import render # Create your views here. def upload(request): if requ ...
- dos文件(夹)复制命令:copy和xcopy
1.copy命令 将一份或多份文件复制到另一个位置. COPY [/D] [/V] [/N] [/Y | /-Y] [/Z] [/L] [/A | /B ] source [/A | /B] [+ s ...
- Python Web开发问题收集(二)
- JMeter选择协议踩过的坑
- net core体系-web应用程序-4net core2.0大白话带你入门-8asp.net core 内置DI容器(DependencyInjection,控制翻转)的一点小理解
asp.net core 内置DI容器的一点小理解 DI容器本质上是一个工厂,负责提供向它请求的类型的实例. .net core内置了一个轻量级的DI容器,方便开发人员面向接口编程和依赖倒置(IO ...
- Python学习(二) —— 运算符
一:Python的编码 python2的默认编码是ascii码,而python3的默认编码是utf-8 ASCII(American Standard Code for Information Int ...
- Fiddler教程--简介
1.开发环境host配置 自己修改系统的host来回挺麻烦的 2.前后的接口调试 3.线上bugfix 4.性能分析和优化 5.等等... 工作原理 一个代理服务器 地址改为 127.0.0.1:88 ...
- ibatis 多种传参方式
1,在公司项目yuda遇到的传入in语句,如果直接拼接in语句:in (....),sqlmap中使用#...#输出是不行的. 为需要使用: 第三种:in后面的数据确定,使用string传入 ...