sklearn调用分类算法的评价指标
sklearn分类算法的评价指标调用
#二分类问题的算法评价指标
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
d=datasets.load_digits()
x=d.data
y=d.target.copy()
print(len(y))
y[d.target==9]=1
y[d.target!=9]=0
print(y)
print(pd.value_counts(y))
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg=LogisticRegression(solver="newton-cg")
log_reg.fit(x_train,y_train)
print(log_reg.score(x_test,y_test))
y_pre=log_reg.predict(x_test)
def TN(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==0))
def FP(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==1))
def FN(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==0))
def TP(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==1))
print(TN(y_test,y_pre))
print(FP(y_test,y_pre))
print(FN(y_test,y_pre))
print(TP(y_test,y_pre))
def confusion_matrix(y_true,y_pre):
return np.array([
[TN(y_true,y_pre),FP(y_true,y_pre)],
[FN(y_true,y_pre),TP(y_true,y_pre)]
])
print(confusion_matrix(y_test,y_pre)) def precision(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FP(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
def recall(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FN(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
print(precision(y_test,y_pre))
print(recall(y_test,y_pre))
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
print((confusion_matrix(y_test,y_pre)))
print(precision_score(y_test,y_pre))
print(recall_score(y_test,y_pre))
print(log_reg.score(x_test,y_test))
def F1(pre,rec):
try:
return (2*pre*rec)/(pre+rec)
except:
return 0.0
print(F1(precision(y_test,y_pre),recall(y_test,y_pre)))
print(F1(0.1,0.9))
print(F1(0,1))
from sklearn.metrics import f1_score
print(f1_score(y_test,y_pre))
print(log_reg.decision_function(x_test))
#改变阈值,可以改变机器学习的召回率和精准率
decision_scores=log_reg.decision_function(x_test)
y_pre2=np.array(decision_scores>=5,dtype="int")
print(precision(y_test,y_pre2))
print(recall(y_test,y_pre2))
print(confusion_matrix(y_test,y_pre2))
y_pre3=np.array(decision_scores>=-5,dtype="int")
print(precision(y_test,y_pre3))
print(recall(y_test,y_pre3))
print(confusion_matrix(y_test,y_pre3))
print(y_pre3)
#绘制出决策边界阈值与精准率和召回率的变化曲线
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
thresholds=np.arange(np.min(decision_scores),np.max(decision_scores),0.1)
pre=[]
rec=[]
for threshold in thresholds:
y_pre11=np.array(decision_scores>threshold,dtype="int")
pre.append(precision_score(y_test,y_pre11))
rec.append(recall_score(y_test,y_pre11))
plt.figure()
plt.plot(thresholds,pre,"r",thresholds,rec,"g")
plt.show()
#输出精确率和召回率曲线
plt.plot(pre,rec,"g",linewidth=5)
plt.show() #直接在sklearn中调用精准率召回率曲线直接输出相应的精准率变化和召回率变化以及决策阈值
from sklearn.metrics import precision_recall_curve
decision_scores=log_reg.decision_function(x_test)
pre1,rec1,thre1=precision_recall_curve(y_test,decision_scores)
print(rec1.shape)
print(pre1.shape)
print(thre1.shape)
plt.figure()
plt.plot(thre1,pre1[:-1],"r")
plt.plot(thre1,rec1[:-1],"g")
plt.show()
plt.plot(pre1,rec1)
plt.show()
#sklearn中调用ROC(TPR与FPR曲线)
from sklearn.metrics import roc_curve
decision_scores=log_reg.decision_function(x_test)
fpr,tpr,thre2=roc_curve(y_test,decision_scores)
plt.plot(fpr,tpr,"r")
plt.show() #曲线和x轴所围成的面积越大则性能越好一点
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_test,decision_scores)) #输出ROC与x轴围成的面积大小roc_auc #多分类问题下的各个评判指标应用
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
d=datasets.load_digits()
x=d.data
y=d.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log1=LogisticRegression()
log1.fit(x_train,y_train)
print(log1.score(x_test,y_test))
y_p=log1.predict(x_test)
from sklearn.metrics import precision_score
print(precision_score(y_test,y_p,average="micro")) #输出精准率的大小(需要设定average参数)
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test,y_p)) #输出混淆矩阵
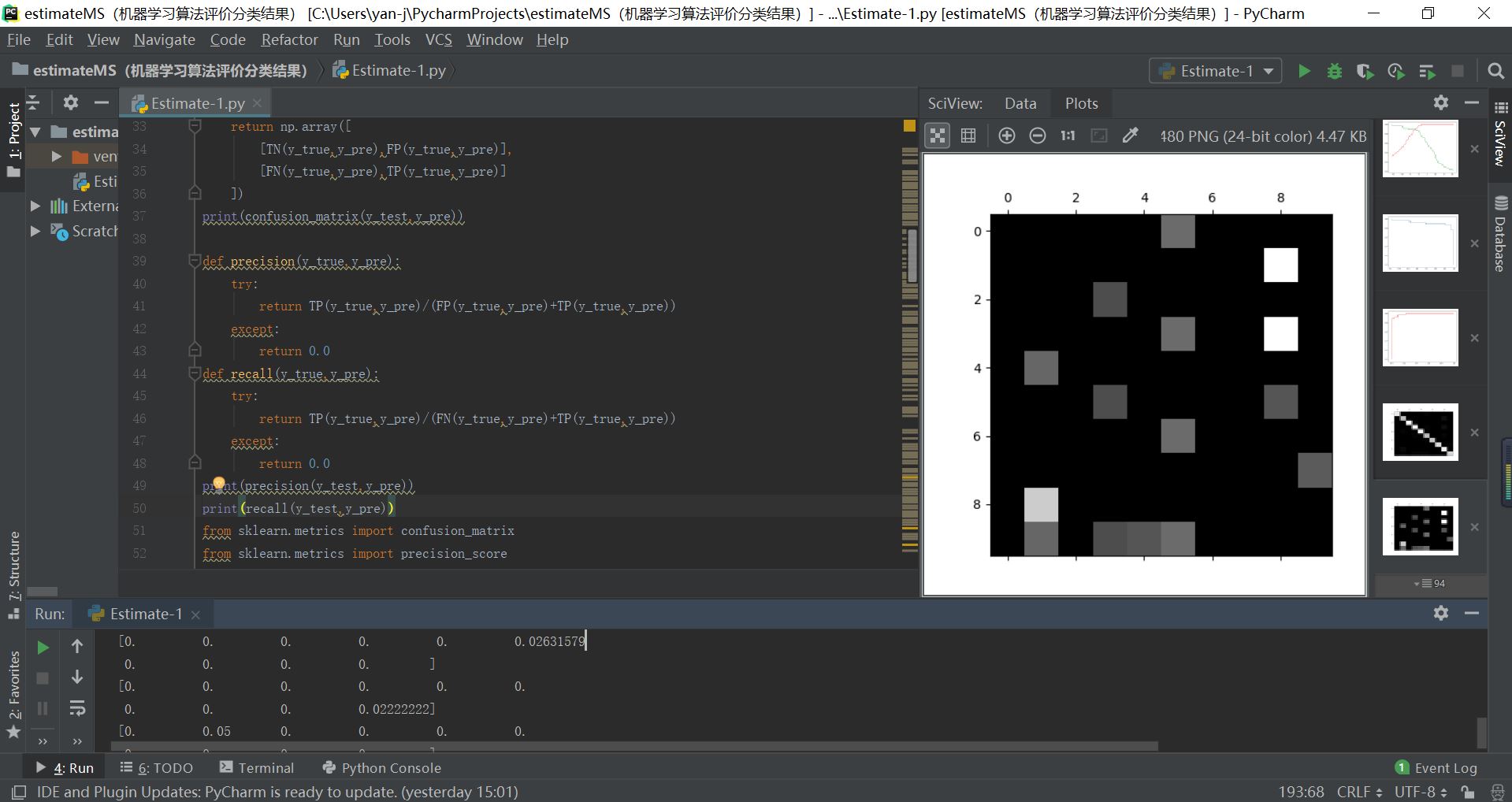
#绘制混淆矩阵通过灰度图的方法可以看出各个行列元素的相对大小
c=confusion_matrix(y_test,y_p)
plt.matshow(c,cmap=plt.cm.gray)
plt.show()
row_sum=np.sum(c,axis=1)
erro_matrix=c/row_sum
np.fill_diagonal(erro_matrix,0) #将对角线的值填充为0
print(erro_matrix)
plt.matshow(erro_matrix,cmap=plt.cm.gray) #输出多元分类结果时所输出的错误结果
plt.show()
sklearn调用分类算法的评价指标的更多相关文章
- sklearn调用SVM算法
1.支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的泛化能力尽可能地好,因此SVM对未来数据的预测也是更加准确的. 2.SVM既可以解决分类问题 ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- sklearn调用逻辑回归算法
1.逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决. 2.决策边界是指不同分类结果之间的边界 ...
- sklearn中调用PCA算法
sklearn中调用PCA算法 PCA算法是一种数据降维的方法,它可以对于数据进行维度降低,实现提高数据计算和训练的效率,而不丢失数据的重要信息,其sklearn中调用PCA算法的具体操作和代码如下所 ...
- AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]
分类算法:对目标值进行分类的算法 1.sklearn转换器(特征工程)和预估器(机器学习) 2.KNN算法(根据邻居确定类别 + 欧氏距离 + k的确定),时间复杂度高,适合小数据 ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
- SKlearn中分类决策树的重要参数详解
学习机器学习童鞋们应该都知道决策树是一个非常好用的算法,因为它的运算速度快,准确性高,方便理解,可以处理连续或种类的字段,并且适合高维的数据而被人们喜爱,而Sklearn也是学习Python实现机器学 ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
随机推荐
- mybatis源码探索笔记-4(缓存原理)
前言 mybatis的缓存大家都知道分为一级和二级缓存,一级缓存系统默认使用,二级缓存默认开启,但具体用的时候需要我们自己手动配置.我们依旧还是先看一个demo.这儿只贴出关键代码 public in ...
- Binary Heap(二叉堆) - 堆排序
这篇的主题主要是Heapsort(堆排序),下一篇ADT数据结构随笔再谈谈 - 优先队列(堆). 首先,我们先来了解一点与堆相关的东西.堆可以实现优先队列(Priority Queue),看到队列,我 ...
- vue-cli 手脚架mock虚拟数据的运用,特别是坑!!!
1.现在基本的趋势就是前后分离,前后分离就意味着当后台接口还没完成之前,前端是没有接口可以拿来调用的 ,那么mock虚拟数据就很好的解决了这一问题,前端可以直接模拟真实的数据AJAX请求! 运用 步骤 ...
- 「CF438D The Child and Sequence」
一道CF线段树好题. 前置芝士 线段树:一个很有用数据结构. 势能分析:用来证明复杂度,其实不会也没什么关系啦. 具体做法 不难发现,对于一个数膜一个大于它的数后,这个数至少减少一半,每个数最多只能被 ...
- 手机wifi的mac地址是什么??
简单来说,每个能够接入网络的设备,无论是平板.手机.电脑.电视都有一个专门的序号,这个序号就被称为MAC,正常来说可以看做是这款设备的唯一标识,手机里的MAC其实是特指Wi-Fi无线网卡的MAC地址. ...
- 5(计算机网络)从物理层到MAC层
故事就从我的大学宿舍开始讲起吧.作为一个八零后,我要暴露年龄了. 我们宿舍四个人,大一的时候学校不让上网,不给开通网络.但是,宿舍有一个人比较有钱,率先买了一台电脑.那买了电脑干什么呢? 首先,有单机 ...
- redis服务器性能优化
1.系统内存OOM优化 vm.overcommit_memory Redis会占用非常大内存,所以通常需要关闭系统的OOM,方法为将“/proc/sys/vm/overcommit_memory”的值 ...
- JavaScript图形实例:图形的平移和对称变换
1.1 六瓣花平移变换 平移变换是指图形从一个位置到另一个位置所作的直线移动.如果要把一个位于P(x,y)的点移到新位置P’(x’,y’),如图1,则只要在原坐标上加上平移距离Tx和Ty即可. 即 ...
- java打包成可执行的jar或者exe的详细步骤
Java程序完成以后,对于Windows操作系统,习惯总是想双击某个exe文件就可以直接运行程序,现我将一步一步的实现该过程.最终结果是:不用安装JRE环境,不用安装数据库,直接双击一个exe文件,就 ...
- 【快学springboot】1.快速创建springboot项目
若图片查看异常,请前往掘金查看:https://juejin.im/post/5d00e793f265da1b614ff10b 使用spring initialize工具快速创建springboot项 ...