sklearn神经网络分类
sklearn神经网络分类
神经网络学习能力强大,在数据量足够,隐藏层足够多的情况下,理论上可以拟合出任何方程。
理论部分
sklearn提供的神经网络算法有三个:
neural_network.BernoulliRBM,neural_network.MLPClassifier,neural_network.MLPRgression
我们现在使用MLP(Multi-Layer Perception)做分类,回归其实也类似。该网络由三部分组成:输入层、隐藏层、输出层,其中隐藏层的个数可以人为设定。神经网络学习之后的知识都存在每一层的权重矩阵中,学习的过程也就是不断训练权重达到拟合的效果。权重训练比较常用的方法是反向传递(Backpropagation)

分类代码
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
import numpy as np
from sklearn.preprocessing import StandardScaler
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类
data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
scaler = StandardScaler()
X = data[['sepal length (cm)','sepal width (cm)']]
scaler.fit(X)
#标准化数据集
X = scaler.transform(X)
Y = data[['class']]
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
mpl = MLPClassifier(solver='lbfgs',activation='logistic')
mpl.fit(X_train, Y_train)
print 'Score:\n',mpl.score(X_test, Y_test) #score是指分类的正确率
#区域划分
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X[Y['class']==0,0]
class1_y = X[Y['class']==0,1]
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class2_x = X[Y['class']==1,0]
class2_y = X[Y['class']==1,1]
l2 = plt.scatter(class2_x,class2_y,color='r',label=iris.target_names[1])
class3_x = X[Y['class']==2,0]
class3_y = X[Y['class']==2,1]
l3 = plt.scatter(class3_x,class3_y,color='g',label=iris.target_names[2])
plt.legend(handles = [l1, l2,l3], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
测试结果
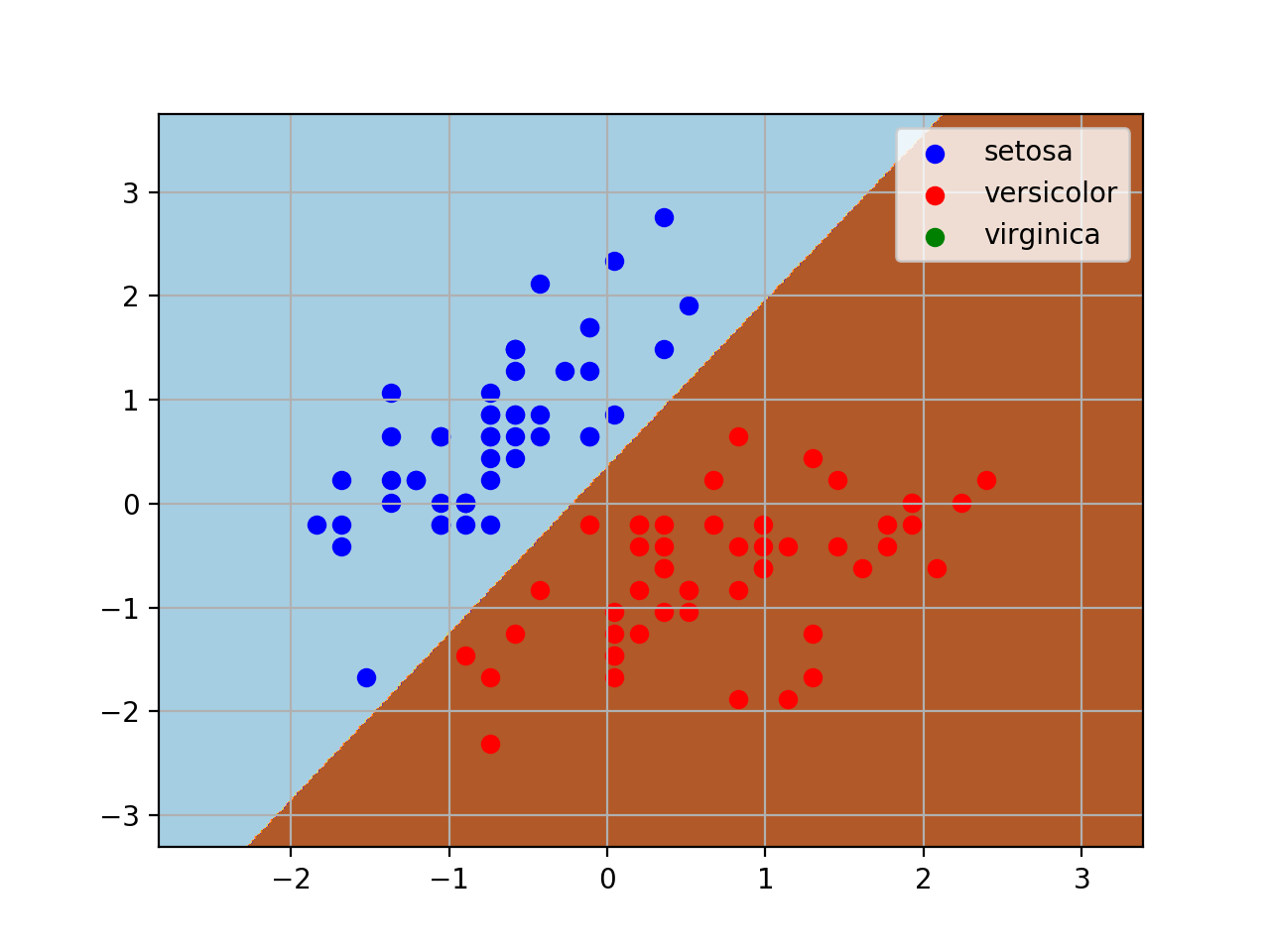
sklearn神经网络分类的更多相关文章
- [转载]sklearn多分类模型
[转载]sklearn多分类模型 这篇文章很好地说明了利用sklearn解决多分类问题时的implement层面的内容:https://www.jianshu.com/p/b2c95f13a9ae.我 ...
- sklearn解决分类问题(KNN,线性判别函数,二次判别函数,KMeans,MLE,人工神经网络)
代码:*******************加密中**************************************
- sklearn多分类问题
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Sklearn中二分类问题的交叉熵计算
二分类问题的交叉熵 在二分类问题中,损失函数(loss function)为交叉熵(cross entropy)损失函数.对于样本点(x,y)来说,y是真实的标签,在二分类问题中,其取值只可能为集 ...
- matlab练习程序(神经网络分类)
注:这里的练习鉴于当时理解不完全,可能会有些错误,关于神经网络的实践可以参考我的这篇博文 这里的代码只是简单的练习,不涉及代码优化,也不涉及神经网络优化,所以我用了最能体现原理的方式来写的代码. 激活 ...
- SKlearn中分类决策树的重要参数详解
学习机器学习童鞋们应该都知道决策树是一个非常好用的算法,因为它的运算速度快,准确性高,方便理解,可以处理连续或种类的字段,并且适合高维的数据而被人们喜爱,而Sklearn也是学习Python实现机器学 ...
- sklearn调用分类算法的评价指标
sklearn分类算法的评价指标调用#二分类问题的算法评价指标import numpy as npimport matplotlib.pyplot as pltimport pandas as pdf ...
- tensorflow RNN循环神经网络 (分类例子)-【老鱼学tensorflow】
之前我们学习过用CNN(卷积神经网络)来识别手写字,在CNN中是把图片看成了二维矩阵,然后在二维矩阵中堆叠高度值来进行识别. 而在RNN中增添了时间的维度,因为我们会发现有些图片或者语言或语音等会在时 ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
随机推荐
- 一条bash命令,清除指定的网络接口列表
在K8S的安装配置过程, 由于不断的测试, 会不断的生成各式各样的虚拟网络接口. 那么,不重新安装之前,清除前次产生的这些垃圾接口, 不让它们影响下次的测试,是很有必要的. 如何快速删除呢? 如下命令 ...
- 山寨版 WP8.1 Cortana 启动 PC
8.1 dev preview 发布以来 Cortana 很受关注 前一段看到有视频演示用 Cortana 来启动 PC 看视频也是启动第三方应用实现的,简单来弄其实就是个语音启动应用 + 网络唤醒么 ...
- BFC的形成和排版规则
何为bfc? BFC(Block Formatting Context)直译为“块级格式化范围”.是 W3C CSS 2.1 规范中的一个概念,它决定了元素如何对其内容进行定位,以及与其他元素的关系和 ...
- Linux 记录所有用户登录和操作的详细日志
1.起因 最近Linux服务器上一些文件呗篡改,想追查已经查不到记录了,所以得想个办法记录下所有用户的操作记录. 一般大家通常会采用history来记录,但是history有个缺陷就是默认是1000行 ...
- Python学习(二十二)—— 前端基础之BOM和DOM
转载自http://www.cnblogs.com/liwenzhou/p/8011504.html 一.前言 到目前为止,我们已经学过了JavaScript的一些简单的语法.但是这些简单的语法,并没 ...
- Python学习(十) —— 常用模块
一.collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdic ...
- python面试题之python下多线程的限制
python多线程有个全局解释器锁(global interpreter lock). 这个锁的意思是任一时间只能有一个线程使用解释器,跟单cpu跑多个程序一个意思,大家都是轮着用的,这叫“并发”,不 ...
- 数据特征分析:1.基础分析概述& 分布分析
基础分析概述 几个基础分析思路: 分布分析 对比分析 统计分析 帕累托分析 正态性检测 相关性分析 分布分析 分布分析是研究数据的分布特征和分布类型,分定量数据.定性数据区分基本统计量. import ...
- Nginx的配置安装和使用
http://blog.csdn.net/e421083458/article/details/30086413 以后继续更新
- 爬虫2 urllib3用法
import urllib3 import json # 实例化一个连接池 # http = urllib3.PoolManager() # res = http.request('get','htt ...