Spark是一种分布式的计算方案
Spark的安装基于HDFS,所以我们要设置hadoop的配置文件,所以spark的存储不是其主要的功能点,而spark作为分布式生态中的角色是一种计算模式(其他 的计算
模式,比如MR,Storm,spark,tez)。
vim spark-env.sh
export SCALA_HOME=/path/to/scala-2.10.4
export JAVA_HOME=/usr/java/jdk
export HADOOP_HOME=/usr/local/hadoop-2.7.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKER_MEMORY=7g
export SPARK_MASTER_IP=172.16.0.140
export MASTER=spark://172.16.0.140:7077
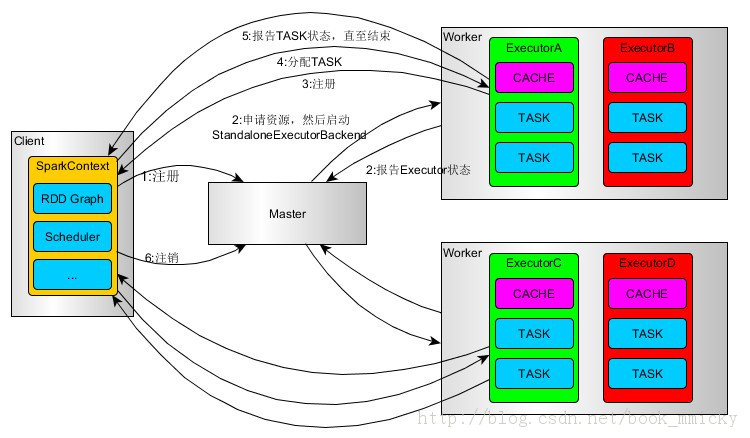
一端是构建driver,另一端就是excutor运行,而mater主要就是完成driver的调度。
运行模式:client cluster 模式
client模式: sparkContext、Driver在客户端构建
clust模式:sparkContext、Driver在不在客户端构建。
DAGScheduler与TaskScheduler全部在Driver端构建完成、最后讲Task调度到不同的Work上运行

===========================================================================
1.RDD类似于数据库中的视图,缓存RDD类似于物化视图,数据库像DSM系统一样,允许典型地读写所有记录,通过记录操作和数据的日志来实现容错,还需要花费额外的开销来维护一致性。RDD编程模型通过增加更多限制来避免这些开销。
2.RDD借鉴了DryadLINQ、Pig和FlumeJava的“并行收集”编程模型,通过允许用户显式地将未序列化的对象保存在内存中,以此来控制分区和基于key随机查找,从而有效地支持基于工作集的应用。RDD保留了那些数据流系统更高级别的编程特性,这对那些开发人员来说也比较熟悉,而且,RDD也能够支持更多类型的应用。
3.DSM通过检查点[19]实现容错,而Spark使用Lineage重建RDD分区,这些分区可以在不同的节点上重新并行处理,而不需要将整个程序回退到检查点再重新运行。RDD能够像MapReduce一样将计算推向数据[12],并通过推测执行来解决某些任务计算进度落后的问题,推测执行在一般的DSM系统上是很难实现的。
Spark是一种分布式的计算方案的更多相关文章
- 分布式ID详解(5种分布式ID生成方案)
分布式架构会涉及到分布式全局唯一ID的生成,今天我就来详解分布式全局唯一ID,以及分布式全局唯一ID的实现方案@mikechen 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消 ...
- Apache Spark支持三种分布式部署方式 standalone、spark on mesos和 spark on YARN区别
链接地址: http://dongxicheng.org/framework-on-yarn/apache-spark-comparing-three-deploying-ways/ Spark On ...
- Apache Spark探秘:三种分布式部署方式比较
转自:链接地址: http://dongxicheng.org/framework-on-yarn/apache-spark-comparing-three-deploying-ways/ 目 ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
- 分布式id生成方案总结
本文已经收录自 JavaGuide (60k+ Star[Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.) 本文授权转载自:https://juejin.im/post/ ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 分析 5种分布式事务方案,还是选了阿里的 Seata(原理 + 实战)
好长时间没发文了,最近着实是有点忙,当爹的第 43 天,身心疲惫.这又赶上年底,公司冲 KPI 强制技术部加班到十点,晚上孩子隔两三个小时一醒,基本没睡囫囵觉的机会,天天处于迷糊的状态,孩子还时不时起 ...
随机推荐
- [linux] cp: omitting directory `XXX'问题解决
在linux系统中复制文件夹时提示如下: cp: omitting directory `foldera/' 其中foldera是我要复制的文件夹名,出现该警告的原因是因为foldera目录下还存在目 ...
- mysql中的null字段值的处理及大小写问题
在MySQL中,NULL字段的处理,需要注意,当在处理查询条件中有NULL,很有可能你得到的值不是想要的,因为,在MySQL中,判断NULL值相等(=)或者不等(!=)都会返回false.主要出现在常 ...
- beeframework开发笔记1
1.商品页弹出规格去掉(null) wzmzy/shop/model/extensions/GOOD_SPEC_VALUE+TagList.m 2.
- Eclipse的中文字体设置
打开eclipse中文字体很小,简直难以辨认.在网上搜索发现这是由于Eclipse 用的字体是 Consolas,显示中文的时候默认太小了.解决方式有两种:一.把字体设置为Courier New 操 ...
- IOS开发-UIBarButtonItem系统自带图标总结
1.这四个返回的是后面的单词. UIBarButtonSystemItemDone UIBarButtonSystemItemCancel UIBarButtonSystemItemEdit UIBa ...
- Python基础教程【读书笔记】 - 2016/7/24
希望通过博客园持续的更新,分享和记录Python基础知识到高级应用的点点滴滴! 第九波:第9章 魔法方法.属性和迭代器 在Python中,有的名称会在前面和后面都加上两个下划线,这种写法很特别.已 ...
- bzoj1760 [Baltic2009]Triangulation
给定一个多边形的三角剖分(n<=1e5),且每个三角形有其颜色,问最多可以把这个三角剖分分成几个联通的部分,使任何一种颜色不出现在多个连通块中 建出三角剖分对应的树,同种颜色的点之间的路径是不能 ...
- bzoj3036: 绿豆蛙的归宿
Description 随着新版百度空间的下线,Blog宠物绿豆蛙完成了它的使命,去寻找它新的归宿. 给出一个有向无环的连通图,起点为1终点为N,每条边都有一个长度.绿豆蛙从起点出发,走向终点.到达每 ...
- Sublime text2用户自定义配置
[{ "keys": ["ctrl+d"], "command": "run_macro_file", "ar ...
- AD7190学习笔记
1 建议SCL空闲时会高电平. 2复位:上电后连续输入40个1(时钟周期)复位到已知状态,并等待500us后才能访问串行接口,用于SCLK噪音导致的同步. 3单次转换与连续转换(连续读取):每次转换是 ...