transformer模型解读
最近在关注谷歌发布关于BERT模型,它是以Transformer的双向编码器表示。顺便回顾了《Attention is all you need》这篇文章主要讲解Transformer编码器。使用该模型在神经机器翻译及其他语言理解任务上的表现远远超越了现有算法。
在 Transformer 之前,多数基于神经网络的机器翻译方法依赖于循环神经网络(RNN),后者利用循环(即每一步的输出馈入下一步)进行顺序操作(例如,逐词地翻译句子)。尽管 RNN 在建模序列方面非常强大,但其序列性意味着该网络在训练时非常缓慢,因为长句需要的训练步骤更多,其循环结构也加大了训练难度。与基于 RNN 的方法相比,Transformer 不需要循环,而是并行处理序列中的所有单词或符号,同时利用自注意力机制将上下文与较远的单词结合起来。通过并行处理所有单词,并让每个单词在多个处理步骤中注意到句子中的其他单词,Transformer 的训练速度比 RNN 快很多,而且其翻译结果也比 RNN 好得多。
模型结构
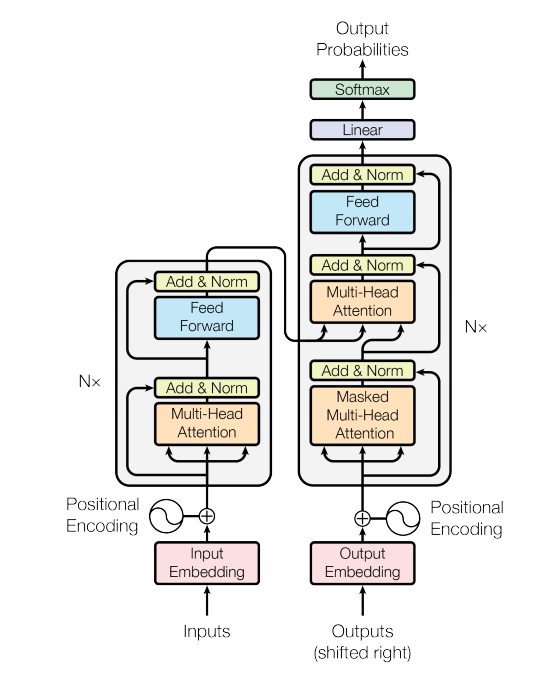
图一、The Transformer Architecture
如图一所示是谷歌提出的transformer 的架构。这其中左半部分是 encoder 右半部分是 decoder。
- Encoder: 由N=6个相同的layers组成, 每一层包含两个sub-layers. 第一个sub-layer 就是多头注意力层(multi-head attention layer)然后是一个简单的全连接层。 其中每个sub-layer都加了residual connection(残差连接)和normalisation(归一化)。
- Decoder: 由N=6个相同的Layer组成,但这里的layer和encoder不一样, 这里的layer包含了三个sub-layers, 其中有一个self-attention layer, encoder-decoder attention layer 最后是一个全连接层。前两个sub-layer 都是基于multi-head attention layer。这里有个特别点就是masking, masking 的作用就是防止在训练的时候 使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的。Masking就会把这个信息变成0,用来保证预测位置 i 的信息只能基于比 i 小的输出。
Attention
Scaled dot-product attention
“Scaled dot-product attention”如下图二所示,其输入由维度为d的查询(Q)和键(K)以及维度为d的值(V)组成,所有键计算查询的点积,并应用softmax函数获得值的权重。
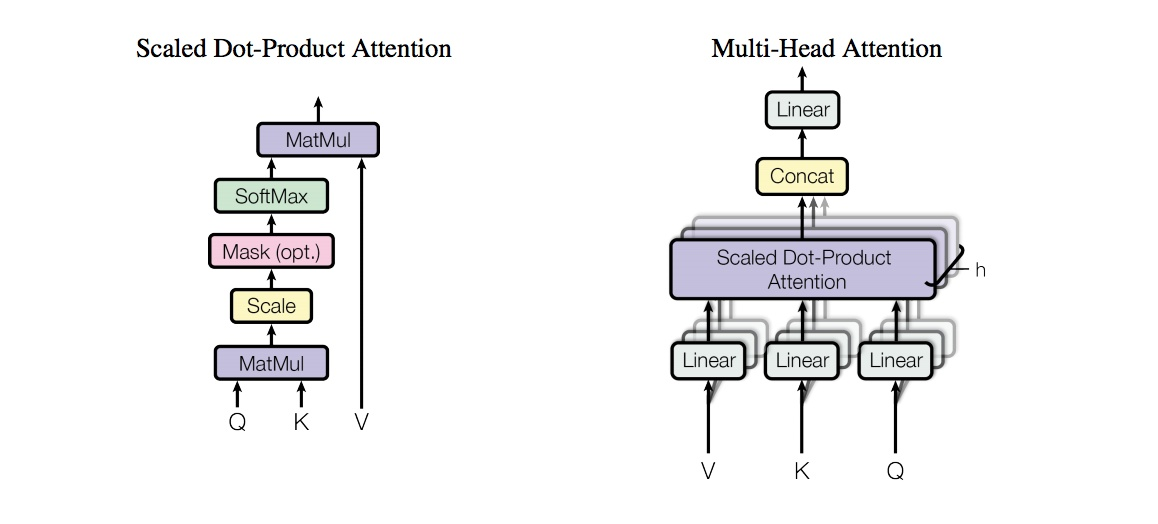
图二、两种Attention实现框图
“Scaled dot-product attention”具体的操作有三个步骤:
- 每个query-key 会做出一个点乘的运算过程,同时为了防止值过大除以维度的常数
- 最后会使用softmax 把他们归一化
- 再到最后会乘以V (values) 用来当做attention vector
数学公式表示如下:
在论文中, 这个算法是通过queries, keys and values 的形式描述的,非常抽象。这里用了一张CMU NLP课里的图来进一步解释, Q(queries), K (keys) and V(Values), 其中 Key and values 一般对应同样的 vector, K=V 而Query vecotor 是对应目标句子的 word vector。如下图三所示。
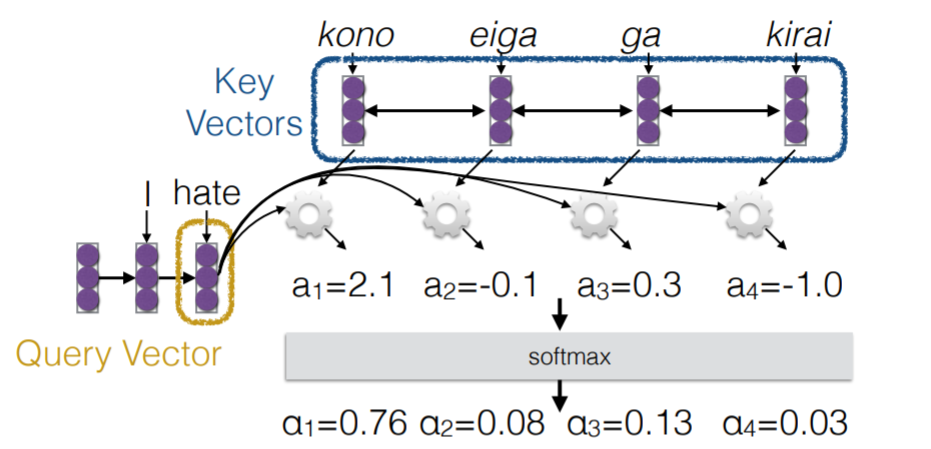
图三、Attention process (source:http://phontron.com/class/nn4nlp2017/assets/slides/nn4nlp-09-attention.pdf)
Multi-head attention
上面介绍的scaled dot-product attention, 看起来还有点简单,网络的表达能力还有一些简单所以提出了多头注意力机制(multi-head attention)。multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来,self-attention则是取Q,K,V相同。

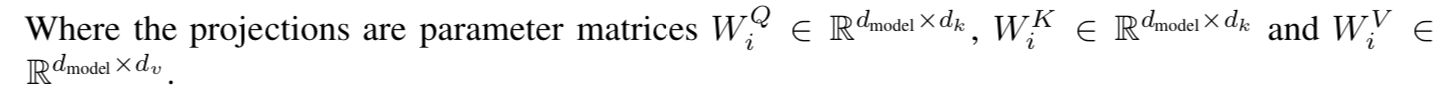
论文中使用了8个平行的注意力层或者头部。因此用的维度dk=dv=dmodel/h=64。
Position-wise feed-forward networks
第二个sub-layer是个全连接层,之所以是position-wise是因为处理的attention输出是某一个位置i的attention输出。全连接层公式如下所示:
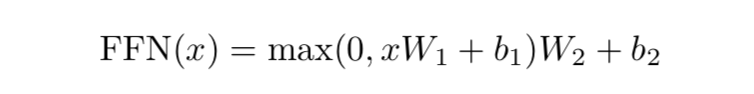
Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
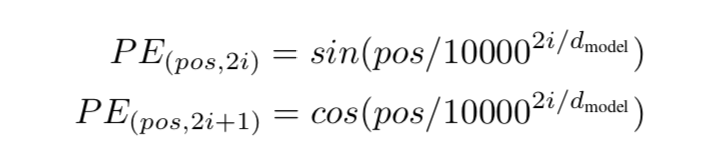
优点
作者主要讲了以下几点,复杂度分析图如下图四所示:

图四、Transformer模型与其他常用模型复杂度比较图
Transformer是第一个用纯attention搭建的模型,不仅计算速度更快,在翻译任务上也获得了更好的结果。该模型彻底抛弃了传统的神经网络单元,为我们今后的工作提供了全新的思路。
transformer模型解读的更多相关文章
- Transformer模型总结
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 它是由编码组件.解码组件和它们之间的连接组成. 编码组件部分由一堆编码器(6个 enco ...
- c++11 内存模型解读
c++11 内存模型解读 关于乱序 说到内存模型,首先需要明确一个普遍存在,但却未必人人都注意到的事实:程序通常并不是总按着照源码中的顺序一一执行,此谓之乱序,乱序产生的原因可能有好几种: 编译器出于 ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- transformer模型简介
Transformer模型由<Attention is All You Need>提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成.论文地 ...
- Transformer模型---decoder
一.结构 1.编码器 Transformer模型---encoder - nxf_rabbit75 - 博客园 2.解码器 (1)第一个子层也是一个多头自注意力multi-head self-atte ...
- Transformer模型---encoder
一.简介 论文链接:<Attention is all you need> 由google团队在2017年发表于NIPS,Transformer 是一种新的.基于 attention 机制 ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
随机推荐
- ExtWebComponents
我们很高兴地宣布Sencha ExtWebComponents的早期版本现已推出.ExtWebComponents提供了数百个预构建的UI组件,您可以轻松地将它们集成到使用任何框架构建的Web应用程序 ...
- Luogu P1607 庙会班车【线段树】By cellur925
题目传送门 据说可以用贪心做?算了算了...我都不会贪.... 开始想的是用线段树,先建出一颗空树,然后输进区间操作后就维护最大值,显然开始我忽视了班车的容量以及可以有多组奶牛坐在一起的信息. 我们肯 ...
- profile和bashrc
转自某不知名网友 /etc/profile,/etc/bashrc 是系统全局环境变量设定~/.profile,~/.bashrc用户家目录下的私有环境变量设定当登入系统时候获得一个shell进程时, ...
- java笔记1:准备工作:java历史、Java环境、java编辑器、cmd常用命令
java的历史 Java是由Sun Microsystems公司于1995年5月推出的Java面向对象程序设计语言和Java平台的总称. 由James Gosling和同事们共同研发,并在1995年正 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- iOS WKWebView 退出后停止播放音频/视频
带有<video>或者<audio>标签的H5网页在播放音频视频时,退出webview后不会自动停止播放,手动处理一下. 1.注入使网页停止音频.视频播放的JS代码(Swift ...
- 点击a标签的子元素不跳转 ,阻止默认行为
- Python实现两已知排好序的列表合并成一个排好序的列表
#方法0.5--- lst1 = [1, 3, 7, 9, 12] lst2 = [4, 8, 9, 13, 15, 19] def merge(a, b): c = [] h = j = 0 whi ...
- PHP获取今天开始和结束的时间戳、每周开始结束的时间戳、每月开始结束的时间戳
PHP获取今天内的时间 今天开始和结束的时间戳 $t = time(); $start = mktime(0,0,0,date("m",$t),date("d" ...
- tsconfig.json No inputs were found in config file
Build:No inputs were found in config file '/tsconfig.json'. Specified 'include' paths were '["* ...