Python抓取第一网贷中国网贷理财每日收益率指数
链接:http://www.p2p001.com/licai/index/id/147.html
所需获取数据链接类似于:http://www.p2p001.com/licai/shownews/id/454.html:
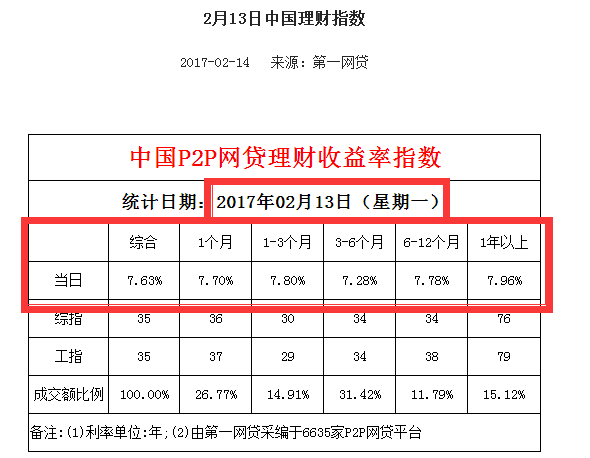
库:
#coding utf-8
import requests
import re
import pandas
from bs4 import BeautifulSoup
user_agent = 'User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)'
headers = {'User-Agent':user_agent}
#定义函数,得到每日报的链接,并以列表形式返回
def get_newsurl():
newsurl=[]
url1='http://www.p2p001.com/licai/index/id/147/p/'
num=1
url2='.html'
while num<=22:
url=url1+str(num)+url2
try:
r1=requests.get(url,headers=headers)
except:
print ('wrong %s' % url)
else:
s1=BeautifulSoup(r1.text,'lxml')
for x in s1.find_all(href=re.compile('licai/shownews')):
newsurl.append(x['href'])
num=num+1
return newsurl
#定义函数,得到的数据,以字典形式返回
def get_info():
url='http://www.p2p001.com'
date=[]
zonghe=[]
one=[]
one_three=[]
three_six=[]
six_twelve=[]
twelve_most=[]
for y in get_newsurl():
try:
main_url=url+y
r2=requests.get(main_url,headers=headers)
except:
print ('wrong %s' % main_url)
else:
s2=BeautifulSoup(r2.text,'lxml')
date.append(s2.find(text=re.compile('统计日期'))[5:])
rate=s2.find_all('td')
zonghe.append(rate[10].string)
one.append(rate[11].string)
one_three.append(rate[12].string)
three_six.append(rate[13].string)
six_twelve.append(rate[14].string)
twelve_most.append(rate[15].string)
p={'Date':date,
'综合':zonghe,
'1个月':one,
'1-3个月':one_three,
'3-6个月':three_six,
'6-12个月':six_twelve,
'12个月及以上':twelve_most}
return p
#pandas存储数据
p=pd.DataFrame(get_info())
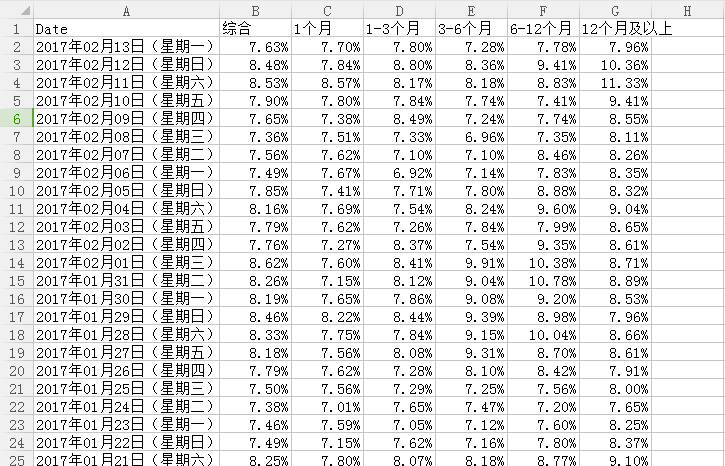
此次学习总结及反思:
1.为了方便处理,并没有使用数据库来存储数据,而是使用pandas将数据以csv格式保存在本地硬盘F
2.定义第一个函数对象get_newsurl,以列表形式返回理财指数日报链接,第二个函数遍历第一个函数的返回值,进行数据的采集
3.为什么不将pandas的一系列操作放在函数对象get_info中,从而直接完成一系列的操作呢?
③处理并存储数据(pandas)
注明:数据来源于第一网贷http://www.p2p001.com/
Python抓取第一网贷中国网贷理财每日收益率指数的更多相关文章
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python抓取中文网页乱码通用解决方法
注:转载自http://www.cnpythoner.com/ 我们经常通过python做采集网页数据的时候,会碰到一些乱码问题,今天给大家分享一个解决网页乱码,尤其是中文网页的通用方法. 首页我们需 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- python抓取链家房源信息
闲着没事就抓取了下链家网的房源信息,抓取的是北京二手房的信息情况,然后通过网址进行分析,有100页,并且每页的url都是类似的 url = 'https://bj.lianjia.com/ershou ...
- Python抓取视频内容
Python抓取视频内容 Python 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年.Python语法简洁而清晰,具 ...
- Python抓取框架:Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下 ...
随机推荐
- ZOJ 3931 Exact Compression
题目看了半小时才看懂的. 题意:首先根据给出的序列,构造出哈夫曼树,构造出来的是一棵二叉树,每个节点都有一个权值,每个节点的两个儿子只能取一个,问能否使取出来的节点权值之和刚好等于e. 这样一分析就很 ...
- 502 Bad Gateway(Nginx) 查看nginx日志有如下内容
2016/09/01 09:49:41 [error] 79464#79464: *3 user "nagios" was not found in "/usr/loca ...
- iOS开发——单例模式
一.用if语句实现单例 1.在.h文件中 #import <Foundation/Foundation.h> @interface YYTRequestTool : NSObject +( ...
- X-004 FriendlyARM tiny4412 uboot移植之点亮指路灯
<<<<<<<<<<<<<<<<<<<<<<<<< ...
- Dom编程(二)
document是window对象的一个属性,因为使用window对象成员的时候可以省略window.,所以一般直接写document document的方法: (1)write:向文档中写入内容. ...
- 微信小程序之----audio音频播放
audio audio为音频组件,我们可以轻松的在小程序中播放音频. audio组件属性如下: 属性名 类型 默认值 说明 id String video 组件的唯一标识符, src String ...
- C# Expression表达式笔记
整理了一下表达式树的一些东西,入门足够了 先从ConstantExpression 开始一步一步的来吧 它表示具有常量值的表达式 我们选建一个控制台应用程序 ConstantExpression _ ...
- php中字符串长度和截取的函数
在做PHP开发的时候,由于我国的语言环境问题,所以我们常常需要对中文进行处理. 在PHP中,我们都知道有专门的mb_substr和mb_strlen函数,可以对中文进行截取和计算长度,但是,由于这些函 ...
- Apache 代理(Proxy) 转发请求
代理分为:正向代理(Foward Proxy)和反向代理(Reverse Proxy) 1.正向代理(Foward Proxy) 正向代理(Foward Proxy)用于代理内部网络对Internet ...
- Web前端开发中的各种CSS规范
Reference: http://yusi123.com/2866.html 一.文件规范 1.文件均归档至约定的目录中(具体要求以豆瓣的CSS规范为例进行讲解): 所有的CSS分为两大类:通用类和 ...