Python抓取第一网贷中国网贷理财每日收益率指数
链接:http://www.p2p001.com/licai/index/id/147.html
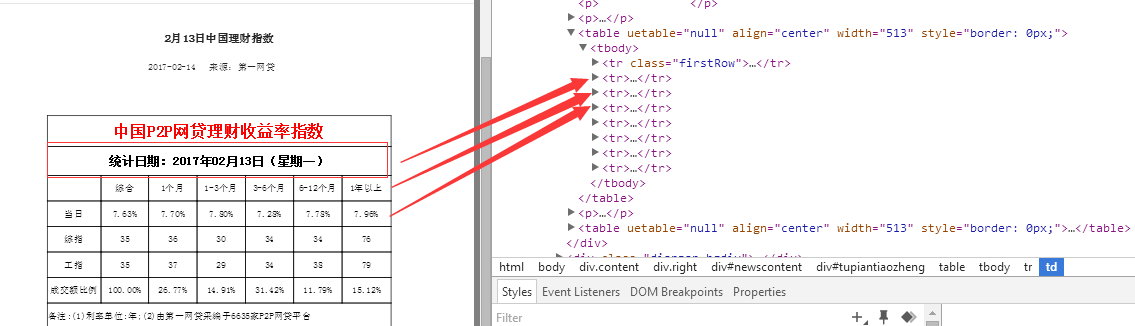
所需获取数据链接类似于:http://www.p2p001.com/licai/shownews/id/454.html:
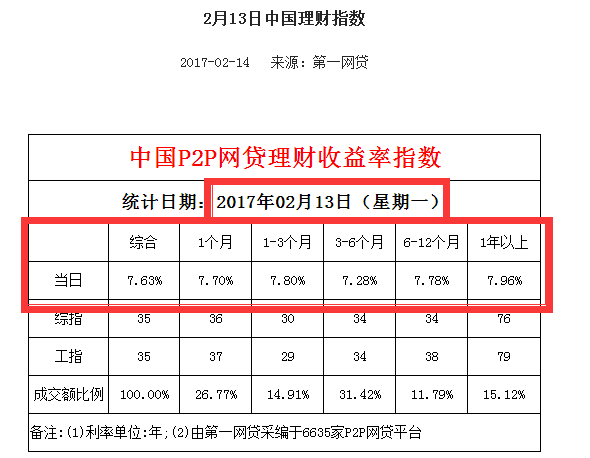
库:
#coding utf-8
import requests
import re
import pandas
from bs4 import BeautifulSoup
user_agent = 'User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)'
headers = {'User-Agent':user_agent}
#定义函数,得到每日报的链接,并以列表形式返回
def get_newsurl():
newsurl=[]
url1='http://www.p2p001.com/licai/index/id/147/p/'
num=1
url2='.html'
while num<=22:
url=url1+str(num)+url2
try:
r1=requests.get(url,headers=headers)
except:
print ('wrong %s' % url)
else:
s1=BeautifulSoup(r1.text,'lxml')
for x in s1.find_all(href=re.compile('licai/shownews')):
newsurl.append(x['href'])
num=num+1
return newsurl
#定义函数,得到的数据,以字典形式返回
def get_info():
url='http://www.p2p001.com'
date=[]
zonghe=[]
one=[]
one_three=[]
three_six=[]
six_twelve=[]
twelve_most=[]
for y in get_newsurl():
try:
main_url=url+y
r2=requests.get(main_url,headers=headers)
except:
print ('wrong %s' % main_url)
else:
s2=BeautifulSoup(r2.text,'lxml')
date.append(s2.find(text=re.compile('统计日期'))[5:])
rate=s2.find_all('td')
zonghe.append(rate[10].string)
one.append(rate[11].string)
one_three.append(rate[12].string)
three_six.append(rate[13].string)
six_twelve.append(rate[14].string)
twelve_most.append(rate[15].string)
p={'Date':date,
'综合':zonghe,
'1个月':one,
'1-3个月':one_three,
'3-6个月':three_six,
'6-12个月':six_twelve,
'12个月及以上':twelve_most}
return p
#pandas存储数据
p=pd.DataFrame(get_info())
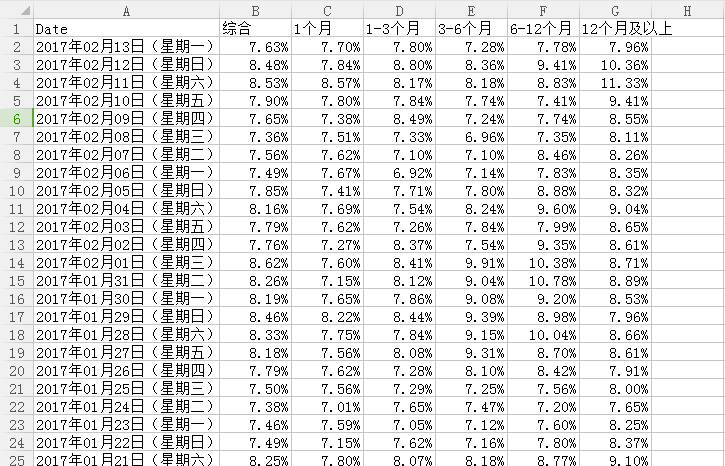
此次学习总结及反思:
1.为了方便处理,并没有使用数据库来存储数据,而是使用pandas将数据以csv格式保存在本地硬盘F
2.定义第一个函数对象get_newsurl,以列表形式返回理财指数日报链接,第二个函数遍历第一个函数的返回值,进行数据的采集
3.为什么不将pandas的一系列操作放在函数对象get_info中,从而直接完成一系列的操作呢?
③处理并存储数据(pandas)
注明:数据来源于第一网贷http://www.p2p001.com/
Python抓取第一网贷中国网贷理财每日收益率指数的更多相关文章
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python抓取中文网页乱码通用解决方法
注:转载自http://www.cnpythoner.com/ 我们经常通过python做采集网页数据的时候,会碰到一些乱码问题,今天给大家分享一个解决网页乱码,尤其是中文网页的通用方法. 首页我们需 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- python抓取链家房源信息
闲着没事就抓取了下链家网的房源信息,抓取的是北京二手房的信息情况,然后通过网址进行分析,有100页,并且每页的url都是类似的 url = 'https://bj.lianjia.com/ershou ...
- Python抓取视频内容
Python抓取视频内容 Python 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年.Python语法简洁而清晰,具 ...
- Python抓取框架:Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下 ...
随机推荐
- 一、什么是hadoop?
一.什么是hadoop 1. 背景 Hadoop为分布式文件系统和计算的基础框架系统,其中包含hadoop程序,hdfs系统等. 2. 名词解释 1.Hadoop, Apache开源的分布式框架. ...
- jQuery扩展两类函数(对象调用,静态调用)
作者:zccst 先看小例子: $(function(){ //扩展方式1-通过对新调用 $.fn.each1=function(){ console.log("hehehehe$.fn.f ...
- TCP/IP协议头部结构体(网摘小结)(转)
源:TCP/IP协议头部结构体(网摘小结) TCP/IP协议头部结构体(转) 网络协议结构体定义 // i386 is little_endian. #ifndef LITTLE_ENDIAN #de ...
- iOS所有常用证书,appID,Provisioning Profiles配置说明及制作图文教程
概述: 苹果的证书繁锁复杂,制作管理相当麻烦,今天决定重置一个游戏项目中的所有证书,做了这么多次还是感觉很纠结,索性直接记录下来,日后你我他查阅都方便: 首先得描述一下各个证书的定位,作用,这样在制作 ...
- Java 汉子转拼音
1. 引入: pinyin4j-1.1.0 包; http://pan.baidu.com/s/1eQ8a874 2. 转换; private static String ChineseToPiny ...
- 输入计算表达式,将他们存在string【】中
#include<stdio.h>#include<string>#include<string.h>#include<stdlib.h>#includ ...
- 2)Java学习笔记:匿名内部类
为什么要使用匿名内部类 ①如果以前的类有一些缺陷,只是想在某一个模块进行修复,可以在引用该类的地方使用匿名内部类,在overRide方法进行修复. ②如果一个类,需要派生出很多类,而且这些类大多只是在 ...
- [Angular Tutorial] 6-Two-way Data Binding
在这一步中,您将会添加一个新特性来使得您的用户可以控制电话列表中电话的顺序,动态改变顺序是由创建一个新的数据模型的特性实现的,将它和迭代器绑定在一起,并且让数据绑定神奇地处理下面的工作. ·除了搜索框 ...
- jQuery 动画的执行
jQuery 动画的执行 <%@ page language="java" import="java.util.*" pageEncoding=" ...
- doubango(2)--底层协议栈结构分析
tsip_stack_handle_t 实例 1. tsip_stack_handle_t的创建 在底层,真正运转的协议栈结构式tsip_stack_handle_t的一个实例,它的创建 ...