spark基本概念整理
app
基于spark的用户程序,包含了一个driver program和集群中多个executor
driver和executor存在心跳机制确保存活
3 --conf spark.executor.instances=5 --conf spark.executor.cores=8 --conf spark.executor.memory=80G
rdd
弹性分布式数据集
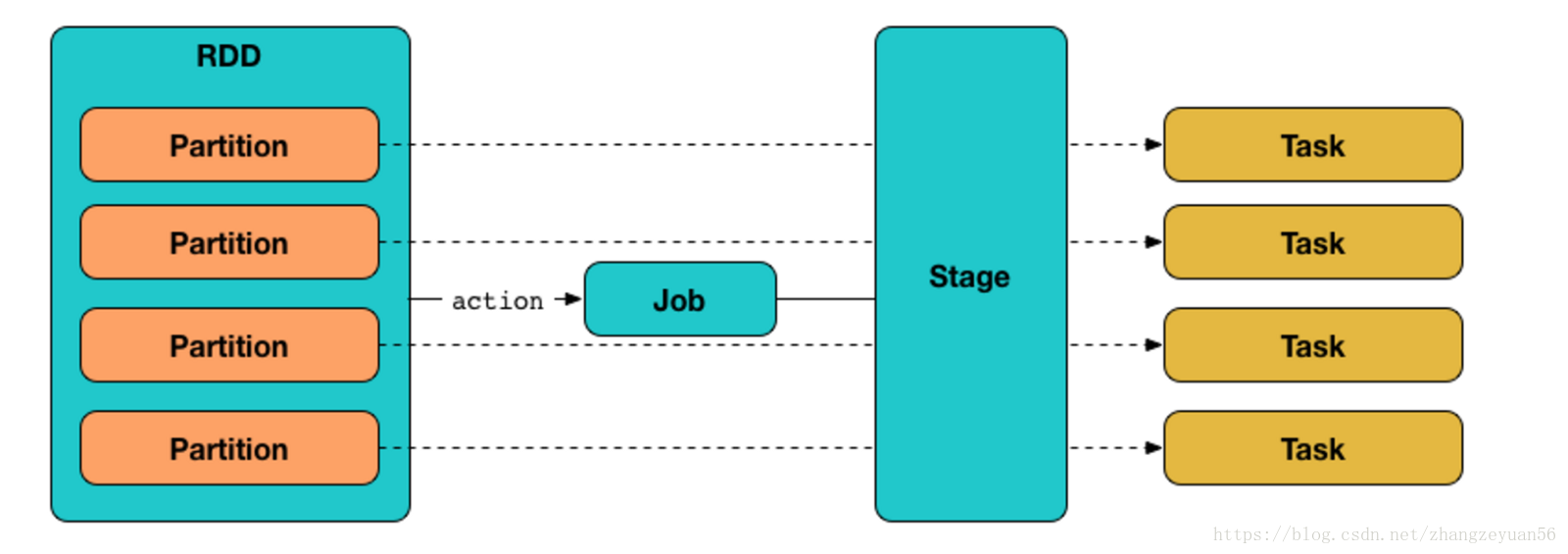
只读的、分区(partition)记录的集合
初代rdd处于血统的顶层,记录任务所需的数据的分区信息,每个分区数据的读取方法
子代rdd不真正的存储信息,只记录血统信息
真正的数据读取,应该是task具体被执行的时候,触发action操作的时候才发生的
算子
分为transformation和action
transformation: map filter flatMap union groupByKey reduceByKey sortByKey join
action: reduce collect count first saveAsTextFile countByKey foreach
partition
rdd存储机制类似hdfs,分布式存储
hdfs被切分成多个block(默认128M)进行存储,rdd被切分为多个partition进行存储
不同的partition可能在不同的节点上
再spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition
将RDD持久化到hdfs上,RDD的每个partition就会存成一个文件,如果文件小于128M,就可以理解为一个partition对应hdfs的一个block。反之,如果大于128M,就会被且分为多个block,这样,一个partition就会对应多个block。
job
一个action算子触发一个job
一个job中有好多的task,task是执行job的逻辑单元(猜测是根据partition划分任务)
一个job根据是否有shuffle发生可以分为好多的stage
stage
rdd中的依赖关系(血统)分为宽依赖和窄依赖
窄依赖:父RDD的一个分区只被一个子RDD的分区使用,不产生shuffle,即父子关系为“一对一”或者“多对一”
宽依赖:产生shuffle,父子关系为“一对多”或者“多对多”
spark根据rdd之间的依赖关系形成DAG有向无环图,DAG提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是rdd之间的宽窄依赖
遇到宽依赖就划分stage
每个stage包含一个或多个task任务
这些task以taskSet的形式提交给TaskScheduler运行
stage是由一组并行的task组成
stage切割规则:从后往前,遇到宽依赖就切割stage。
10 一个stage以外部文件或者shuffle结果作为开始,以产生shuffle或者生成最终结果时结束
11 猜测stage与TaskSet为一一对应的关系
task
分为两种:shuffleMapTask和resultTask
2 默认按照partition进行拆分task
--conf spark.default.parallelism=1000 设置task并行的数量
个人理解以上各种概念都是抽象概念,即简单的理解为全部发生在driver端,只有task相关的信息会被序列化发送到executor去执行
参考链接:
https://www.cnblogs.com/jechedo/p/5732951.html
https://www.2cto.com/net/201802/719956.html
https://blog.csdn.net/fortuna_i/article/details/81170565
https://www.2cto.com/net/201712/703261.html
https://blog.csdn.net/zhangzeyuan56/article/details/80935034
https://www.jianshu.com/p/3e79db80c43c?from=timeline&isappinstalled=0
spark基本概念整理的更多相关文章
- 【知识点】业务连接服务(BCS)认证概念整理
业务连接服务(BCS)认证概念整理 I. BDC认证模型 BDC服务支持两种认证模型:信任的子系统,模拟和代理. 在信任的子系统模型中,中间层(通常是Web服务器)通过一个固定的身份来向后端服务器取得 ...
- DNS,TCP,IP,HTTP,socket,Servlet概念整理
DNS,TCP,IP,HTTP,socket,Servlet概念整理 常见的协议虽然很容易理解,但是看了之后过一段时间不看还是容易忘,笔记如下,比较零碎,勉强供各位复习.如有错误欢迎指正. D ...
- 【Spark深入学习-11】Spark基本概念和运行模式
----本节内容------- 1.大数据基础 1.1大数据平台基本框架 1.2学习大数据的基础 1.3学习Spark的Hadoop基础 2.Hadoop生态基本介绍 2.1Hadoop生态组件介绍 ...
- IIS Web 服务器/ASP.NET 运行原理基本知识概念整理 转
转http://www.cnblogs.com/loongsoft/p/7272830.html IIS Web 服务器/ASP.NET 运行原理基本知识概念整理 前言: 记录 IIS 相 ...
- Spark 基本概念 & 安装
1. Spark 基本概念 1.0 官网 传送门 1.1 简介 Spark 是用于大规模数据处理的快如闪电的统一分析引擎. 1.2 速度 Spark 可以获得更高的性能,针对 batch 计算和流计算 ...
- AIFramework基本概念整理
AIFramework基本概念整理 本文介绍: 对天元 MegEngine 框架中的 Tensor, Operator, GradManager 等基本概念有一定的了解: 对深度学习中的前向传播.反向 ...
- spark基本概念
Client:客户端进程,负责提交作业到Master. Application:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序, ...
- 西瓜书概念整理(chapter 1-2)
括号表示概念出现的其他页码, 如有兴趣协同整理,请到issue中认领章节 完整版见我的github:ahangchen 觉得还不错的话可以点个star ^_^ 第一章 绪论 Page2: 标记(lab ...
- IIS Web 服务器/ASP.NET 运行原理基本知识概念整理
前言: 记录 IIS 相关的笔记还是从公司笔试考核题开始的,问 Application Pool 与 AppDomain 的区别? 促使我对进程池进了知识的学习,所以记录一下学习 ...
随机推荐
- git使用中遇到的问题
1.拉取时报错:Permission denied (publickey) 先检查一下你的乌龟设置是否用的不是乌龟自己的SSH 2.TortoiseGit报错: Couldn’t load this ...
- DFS或BFS(深度优先搜索或广度优先搜索遍历无向图)-04-无向图-岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1: 输入: ...
- 小白学Java:I/O流
目录 小白学Java:I/O流 基本分类 发展史 文件字符流 输出的基本结构 流中的异常处理 异常处理新方式 读取的基本结构 运用输入与输出 文件字节流 缓冲流 字符缓冲流 装饰设计模式 转换流(适配 ...
- redis缓存数据库及Python操作redis
缓存数据库介绍 NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站, 特 ...
- 转载: Java虚拟机:运行时内存数据区域、对象内存分配与访问
转载: https://blog.csdn.net/a745233700/article/details/80291694 (虽然大部分内容都其实是深入理解jvm虚拟机这本书里的,不过整理的很牛逼 ...
- innobackupex 恢复脚本
此脚本需要与我前几天写的备份脚本配套才能使用 这里也对innobackupex吐槽下,当使用innobackupex进行恢复的时候,必须要清除所有原数据文件,但是一旦恢复失败,则连实例都将丢失,不成功 ...
- 超链接a标签的伪类选择器问题,Link标签与visited标签的失效问题(问题介绍与解决方法)。
<!DOCTYPE html>< html>< head> <meta charset="utf-8" /> < ...
- 深入分析Java反射(三)-泛型
前提 Java反射的API在JavaSE1.7的时候已经基本完善,但是本文编写的时候使用的是Oracle JDK11,因为JDK11对于sun包下的源码也上传了,可以直接通过IDE查看对应的源码和进行 ...
- Yandex Big Data Essentials Week1 Unix Command Line Interface File Content exploration
cat displays the contents of a file at the command line copies or apppend text file into a document ...
- 08-JavaScript基础
今日知识 1. JavaScript基础 2. 案例 3.总结 JavaScript介绍: * 概念:一门客户端脚本语言 * 运行在客户端浏览器中的,每一个浏览器都有JavaScript的解析引擎 * ...