scrapy的使用-LinkExtractor
背景:
在爬取网站信息是需要获取特定标签下的某些内容,就需要获取这些标签下的链接,如果获取每一个,在通过这个获取它下面的信息,这样效率会很低,时间复杂度O(n^2),但如果先获取链接,再获取内容,则时间复杂度为O(n)+O(n),每次执行完深度为2,则时间复杂度为O(n).效率会明显提高,非常适合整站爬取。
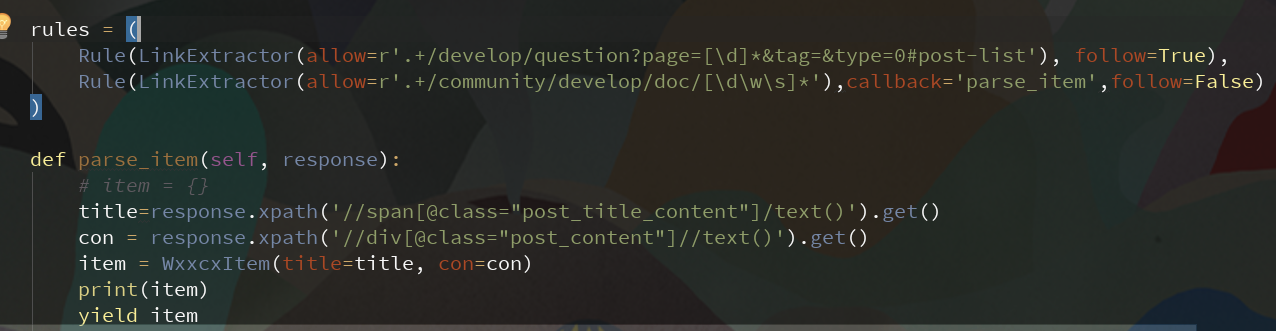
allow() #allow(正则表达式(或的列表)) - 一个单一的正则表达式(或正则表达式列表),(绝对)urls必须匹配才能提取。如果没有给出(或为空),它将匹配所有链接。
deny() #deny(正则表达式或正则表达式列表) - 一个正则表达式(或正则表达式列表),(绝对)urls必须匹配才能排除(即不提取)。它优先于allow参数。如果没有给出(或为空),它不会排除任何链接。
allow_domains() #allow_domains(str或list) - 单个值或包含将被考虑用于提取链接的域的字符串列表
deny_domains() #deny_domains(str或list) - 单个值或包含不会被考虑用于提取链接的域的字符串列表
deny_extensions() #deny_extensions(list) - 包含在提取链接时应该忽略的扩展的单个值或字符串列表。如果没有给出,它将默认为IGNORED_EXTENSIONS在scrapy.linkextractors包中定义的 列表 。
restrict_xpaths() # restrict_xpaths(str或list) - 是一个XPath(或XPath的列表),它定义响应中应从中提取链接的区域。如果给出,只有那些XPath选择的文本将被扫描链接。参见下面的例子。
restrict_css() # restrict_css(str或list) - 一个CSS选择器(或选择器列表),用于定义响应中应提取链接的区域。有相同的行为restrict_xpaths。 标签(str或list) - 标签或在提取链接时要考虑的标签列表。默认为。('a', 'area')
attrs() # attrs(list) - 在查找要提取的链接时应该考虑的属性或属性列表(仅适用于参数中指定的那些标签tags )。默认为('href',)
canonicalize() # canonicalize(boolean) - 规范化每个提取的url(使用w3lib.url.canonicalize_url)。默认为True。
unique() # unique(boolean) - 是否应对提取的链接应用重复过滤。
process_value() # process_value(callable) -
接收从标签提取的每个值和扫描的属性并且可以修改值并返回新值的函数,或者返回None以完全忽略链接。如果没有给出,process_value默认为。lambda x: x

scrapy的使用-LinkExtractor的更多相关文章
- scrapy之使用LinkExtractor提取链接
一.概述: 在页面含有少量链接时,使用selector来提取信息就可以,但如果链接特别多时,就需要用LinkExtractor来提取. 二.LinkExtractor构造器的各个参数: 1.allow ...
- scrapy中使用LinkExtractor提取链接
le = LinkExtractor(restrict_css='ul.pager li.next') links = le.extract_links(response) 使用LinkExtra ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- 爬虫的入门以及scrapy
一.简介 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- 爬虫--Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- 爬虫入门scrapy
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
随机推荐
- CentOS7编译安装MPLAYER!!!
Linux装软件就是折磨人!! Mplayer官网下好release版本 然后./configure --[options] 注意:--prefix=/usr/local/mplayer 是安装路径- ...
- elipse手机设备显示Target unknown或者offline解决方法
参考资料: http://blog.csdn.net/yuanjingjiang/article/details/11297433 http://www.educity.cn/wenda/153487 ...
- android studio import cannot resolve symbol错误
试了好多,都不行 经过查阅和测试,发现如果上文的解决方式不可以的话,可以使用另一种: 删除项目.idea目录下的libraries目录 重新启动Android Studio 感谢作者:https:// ...
- vue2.0使用基础
开发情况下需要引入vue.js和vue-resource.js,el:dom生效范围,data,dom静态数据,mounted:初始化调用方法,注意,官方文档需要添加this.$nextTict(fu ...
- Vim多窗口编辑
在Linux中使用vim编辑多个窗口 方式: 1. vim -o file1 file2 打开的两个文件上下窗口分布 比如当前目录有makefil ...
- 用JS获取地址栏参数的方法(转)
方法一:采用正则表达式获取地址栏参数:( 强烈推荐,既实用又方便!) function GetQueryString(name) { var reg = new RegExp("( ...
- CSS中background的用法
CSS中 background 是一个很基本的而且比较常用的样式 background : background-color || background-image || background-re ...
- linux每日命令(3):which命令
这个命令我也神佑体会它的用处,在linux要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索: which 查看可执行文件的位置. whereis 查看文件的位置. locate ...
- 微信小程序之模板消息推送
最近在用sanic框架写微信小程序,其中写了一个微信消息推送,还挺有意思的,写了个小demo 具体见官方文档:https://developers.weixin.qq.com/miniprogram/ ...
- 加载ubuntu的时候卡在‘SMBus Host Controller not enabled'错误
实验系统:ubuntu-16.04.6-server-amd64 我在VMware安装完这个系统后进入发现卡在了’SMBus Host Controller not enabled‘里,后来查过网络发 ...