python初探爬虫
python爬虫初探
爬取前50名豆瓣电影:
废话少说,直接上代码!
import re
import requests
from bs4 import BeautifulSoup
def get_content(url,):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def parser_content(htmlContent):
# 实例化soup对象, 便于处理;
soup = BeautifulSoup(htmlContent, 'html.parser')
# 1). 电影信息存储在ol标签里面的li标签:
# <ol class="grid_view">
olObj = soup.find_all('ol', class_='grid_view')[0]
# 2). 获取每个电影的详细信息, 存储在li标签;
details = olObj.find_all('li')
for detail in details:
# # 3). 获取电影名称;
movieName = detail.find('span', class_='title').get_text()
# 4). 电影评分:
movieScore = detail.find('span', class_='rating_num').get_text()
# 5). 评价人数***************
# 必须要转换类型为字符串
movieCommentNum = str(detail.find(text=re.compile('\d+人评价')))
# 6). 电影短评
movieCommentObj = detail.find('span', class_='inq')
if movieCommentObj:
movieComment = movieCommentObj.get_text()
else:
movieComment = "无短评"
movieInfo.append((movieName, movieScore, movieCommentNum, movieComment))
import openpyxl
def create_to_excel(wbname, data, sheetname='Sheet1', ):
"""
将制定的信息保存到新建的excel表格中;
:param wbname:
:param data: 往excel中存储的数据;
:param sheetname:
:return:
"""
print("正在创建excel表格%s......" % (wbname))
# wb = openpyxl.load_workbook(wbname)
# 如果文件不存在, 自己实例化一个WorkBook的对象;
wb = openpyxl.Workbook()
# 获取当前活动工作表的对象
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
# 将数据data写入excel表格中;
print("正在写入数据........")
for row, item in enumerate(data): # data发现有4行数据, item里面有三列数据;
print(item)
for column, cellValue in enumerate(item):
# cell = sheet.cell(row=row + 1, column=column + 1, value=cellValue)
cell = sheet.cell(row=row+1, column=column + 1)
cell.value = cellValue
wb.save(wbname)
print("保存工作薄%s成功......." % (wbname))
if __name__ == '__main__':
doubanTopPage = 2
perPage = 25
# [(), (), ()]
movieInfo = []
# 1, 2, 3 ,4, 5
for page in range(1, doubanTopPage+1):
# start的值= (当前页-1)*每页显示的数量(25)
url = "https://movie.douban.com/top250?start=%s" %((page-1)*perPage)
content = get_content(url)
parser_content(content)
create_to_excel('/tmp/hello.xlsx', movieInfo, sheetname="豆瓣电影信息")
如果你是直接复制粘贴的,那你这里一定会出现一大串儿红字
解决办法:
创建一个tmp文件夹里边存一个hello.xlsx
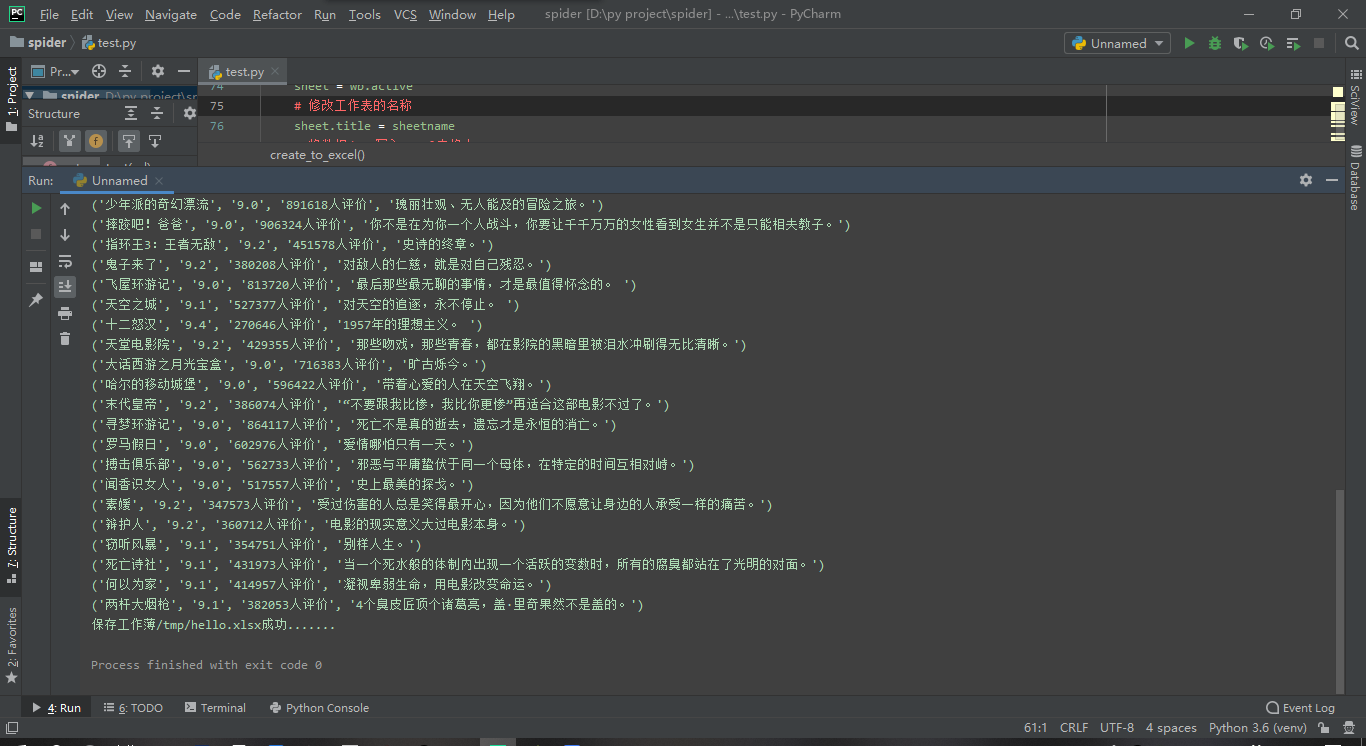
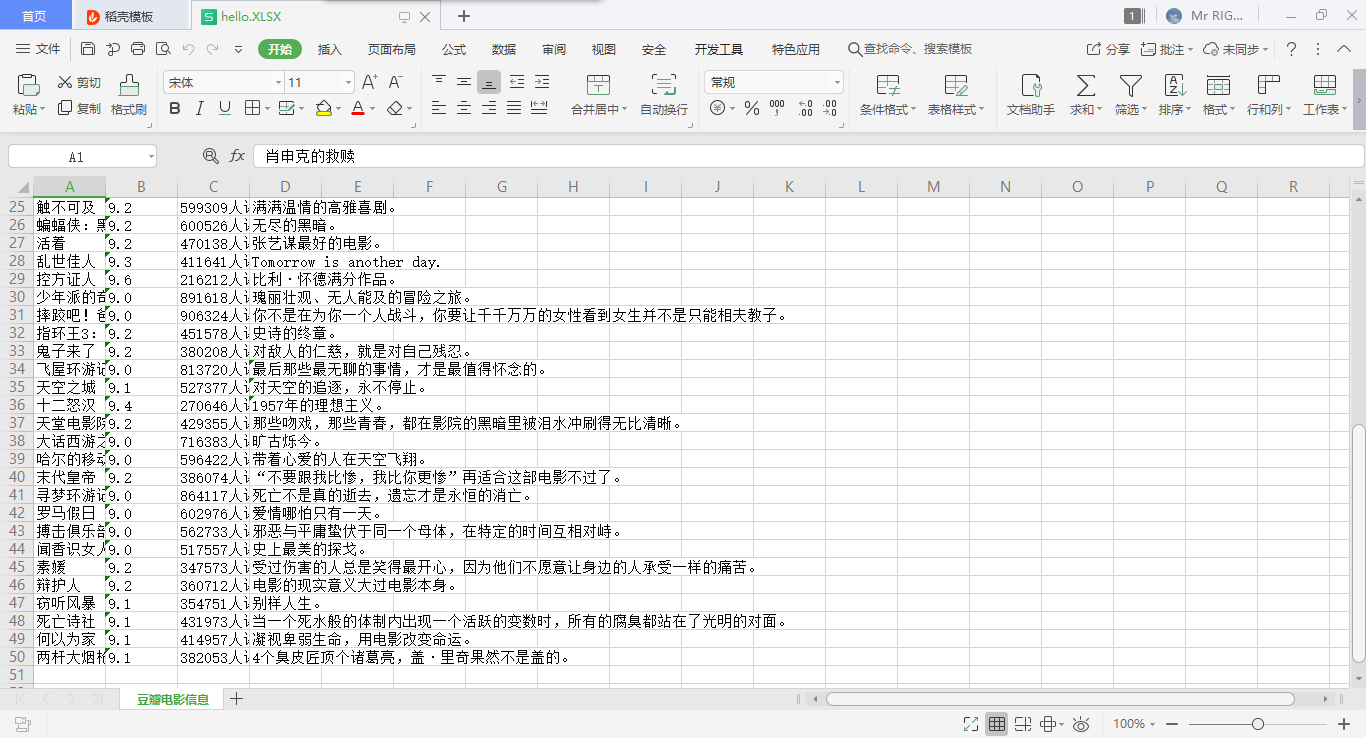
运行截图:
python初探爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
随机推荐
- 数据结构学习笔记——顺序数组1
线性表最简单的刚开始就是顺序存储结构,我是看着郝斌的视频一点一点来的,严蔚敏的书只有算法,没有具体实现,此笔记是具体的实现 为什么数据结构有ADT呢,就是为了满足数据结构的泛性,可以在多种数据类型使用 ...
- Android Dialog对话框的七种形式的使用
参考资料:http://www.oschina.net/question/54100_32486 注:代码进行了整理 在Android开发中,我们经常会需要在Android界面上弹出一些对话框,比如询 ...
- CSS:目录
ylbtech-CSS:目录 1.返回顶部 1. http://www.runoob.com/css/css-tutorial.html 2. https://www.w3school.com.cn/ ...
- 如何从ST官网下载STM32标准库
Frm:https://blog.csdn.net/k1ang/article/details/79645044
- 第一章 Linux是什么
Linux是核心与系统调用接口两层中间的操作系统 不同硬件的功能函数并不相同,IBM的Power CPU与Inter的x86架构不同,所以同一套操作系统是不能在不同的硬件平台上面运行的.也就是说,每种 ...
- Linux基本知识点
压缩和解压类 7.8.1 gzip/gunzip 压缩 1.基本语法 gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件) gunzip 文件.gz (功能描述:解压缩文件命令) 2. ...
- assignment of day four
目录 1.Numeric type (1)integer (2)float Usefulness Define How to use 2.string type Use Define How to u ...
- 操作bin目录下的文件
string dir = AppDomain.CurrentDomain.BaseDirectory + "Video"; if (!System.IO.Directory.Exi ...
- Handler Looper源码解析(Android消息传递机制)
Android的Handler类应该是常用到的,多用于线程间的通信,以及子线程发送消息通知UI线程刷新View等等.这里我主要总结下我对整个消息传递机制,包括Handler,Looper,Messag ...
- web APP 开发之踩坑手记
屏蔽输入框怪异的内阴影 -webkit-appearance:none 禁止自动识别电话和邮箱 <meta content="telephone=no" name=" ...