MongoDB复制集的工作原理介绍(二)
复制集工作原理
1)数据复制原理
开启复制集后,主节点会在 local 库下生成一个集合叫 oplog.rs,这是一个有限集合,也就是大小是固定的。其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作,当空间用完时新记录自动覆盖最老的记录。
复制集中的从节点就是通过读取主节点上面的 oplog 来实现数据同步的,MongoDB的oplog(操作日志)是一种特殊的封顶集合,滚动覆盖写入,固定大小。另外oplog的滚动覆盖写入方式有两种:一种是达到设定大小就开始覆盖写入;二是设定文档数,达到文档数就开始覆盖写入(不推荐使用)。
复制集工作方式如下图:
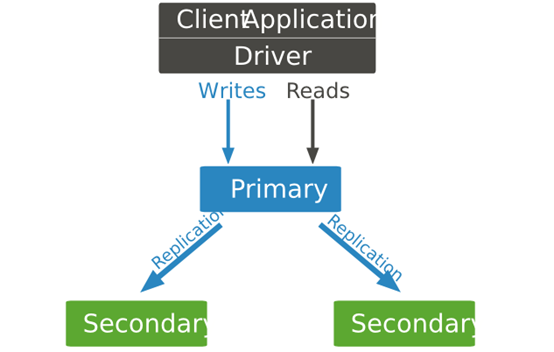
主节点跟应用程序之间的交互是通过Mongodb驱动进行的,Mongodb复制集有自动故障转移功能,那么应用程序是如何找到主节点呢?Mongodb提供了一个rs.isMaster()函数,这个函数可以识别主节点。默认应用程序读写都是在主节点上,默认情况下,读和写都只能在主节点上进行。但是主压力过大时就可以把读操作分离到从节点上从而提高读性能。下面是MongoDB的驱动支持5种复制集读选项:
primary:默认模式,所有的读操作都在复制集的主节点进行的。
primaryPreferred:在大多数情况时,读操作在主节点上进行,但是如果主节点不可用了,读操作就会转移到从节点上执行。
secondary:所有的读操作都在复制集的从节点上执行。
secondaryPreferred:在大多数情况下,读操作都是在从节点上进行的,但是当从节点不可用了,读操作会转移到主节点上进行。
nearest:读操作会在复制集中网络延时最小的节点上进行,与节点类型无关。
但是除了primary 模式以外的复制集读选项都有可能返回非最新的数据,因为复制过程是异步的,从节点上应用操作可能会比主节点有所延后。如果我们不使用primary模式,请确保业务允许数据存在可能的不一致。
举个例子:
用客户端向主节点添加了 100 条记录,那么 oplog 中也会有这 100 条的 insert 记录。从节点通过获取主节点的 oplog,也执行这 100 条 oplog 记录。这样,从节点也就复制了主节点的数据,实现了同步。
需要说明的是:并不是从节点只能获取主节点的 oplog。为了提高复制的效率,复制集中所有节点之间会互相进行心跳检测(通过ping)。每个节点都可以从任何其他节点上获取oplog。还有,用一条语句批量删除 50 条记录,并不是在 oplog 中只记录一条数据,而是记录 50 条单条删除的记录。oplog中的每一条操作,无论是执行一次还是多次执行,对数据集的影响结果是一样的,i.e 每条oplog中的操作都是幂等的。
- 初始化同步
- 回滚后的数据追赶
- 分片的chunk迁移
2)复制集写操作
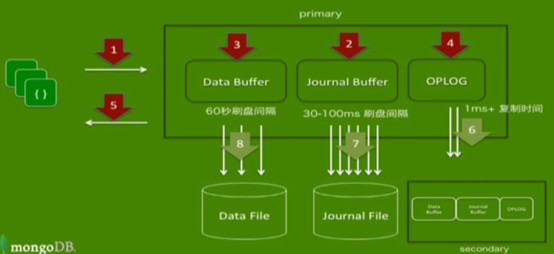
如果启用复制集的话,在内存中会多一个OPLOG区域,是在节点之间进行同步的一个手段,它会把操作日志放到OPLOG中来,然后OPLOG会复制到从节点上。从节点接收并执行OPLOG中的操作日志来达到数据的同步操作。
1) 客户端的数据进来;
2) 数据操作写入到日志缓冲;
3) 数据写入到数据缓冲;
4) 把日志缓冲中的操作日志放到OPLOG中来;
5) 返回操作结果到客户端(异步);
6) 后台线程进行OPLOG复制到从节点,这个频率是非常高的,比日志刷盘频率还要高,从节点会一直监听主节点,OPLOG一有变化就会进行复制操作;
7) 后台线程进行日志缓冲中的数据刷盘,非常频繁(默认100)毫秒,也可自行设置(30-60);
后台线程进行数据缓冲中的数据刷盘,默认是60秒;
3)Oplog的数据结构
|
1
2
3
4
5
6
7
8
9
10
11
|
ywnds:PRIMARY> db.oplog.rs.findOne()
{
"ts" : Timestamp(1453059127, 1),
"h" : NumberLong("-6090285017139205124"),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : {
"msg" : "initiating set"
}
}
|
ts:操作发生时的时间戳,这个时间戳包含两部分内容t和i,t是标准的时间戳(自1970年1月1日 00:00:00 GMT 以来的毫秒数)。而i是一个序号,目的是为了保证t与i组合出的Mongo时间戳ts可以唯一的确定一条操作记录。
h:此操作的独一无二的ID。
v:oplog的版本。
op:操作类型(insert、update、delete、db cmd、null),紧紧代表一个消息信息。
ns:操作所处的命名空间(db_name.coll_name)。
o:操作对应的文档,文档在更新前的状态(“msg” 表示信息)。
o2:仅update操作时有,更新操作的变更条件(只记录更改数据)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{
"ts" : Timestamp(1481094522, 1),
"t" : NumberLong(1),
"h" : NumberLong("-7286476219427328778"),
"v" : 2,
"op" : "u",
"ns" : "test.foo",
"o2" : {
"_id" : ObjectId("58466e872780d8f6f65951ad")
},
"o" : {
"_id" : ObjectId("58466e872780d8f6f65951ad"),
"a" : 1000
}
}
|
PS:当你想查询最后一次数据库操作的oplog记录时,可以使用此语句db.oplog.rs.find().sort({$natural:-1}).limit(1).pretty()。
需要重点强调的是oplog只记录改变数据库状态的操作。比如,查询就不存储在oplog中。这是因为oplog只是作为从节点与主节点保持数据同步的机制。存储在oplog中的操作也不是完全和主节点的操作一模一样的,这些操作在存储之前先要做等幂变换,也就是说,这些操作可以在从服务器端多次执行,只要顺序是对的,就不会有问题。例如,使用“$inc”执行的增加更新操作,会被转换为“$set”操作。
4)Oplog大小及意义
当你第一次启动复制集中的节点时,MongoDB会用默认大小建立Oplog。这个默认大小取决于你的机器的操作系统。大多数情况下,默认的oplog大小是足够的。在 mongod 建立oplog之前,我们可以通过设置 oplogSizeMB 选项来设定其大小。但是,如果已经初始化过复制集,已经建立了Oplog了,我们需要通过修改Oplog大小中的方式来修改其大小。
OpLog的默认大小:
- 在64位Linux、Windows操作系统上为当前分区可用空间的5%,但最大不会超过50G。
- 在64位的OS X系统中,MongoDB默认分片183M大小给Oplog。
- 在32位的系统中,MongoDB分片48MB的空间给Oplog。
4.1 复制时间窗口
既然Oplog是一个封顶集合,那么Oplog的大小就会有一个复制时间窗口的问题。举个例子,如果Oplog是大小是可用空间的5%,且可以存储24小时内的操作,那么从节点就可以在停止复制24小时后仍能追赶上主节点,而不需要重新获取全部数据。如果说从节点在24小时后开始追赶数据,那么不好意思主节点的oplog已经滚动覆盖了,把从节点没有执行的那条语句给覆盖了。这个时候为了保证数据一致性就会终止复制。然而,大多数复制集中的操作没有那么频繁,oplog可以存放远不止上述的时间的操作记录。但是,再生产环境中尽可能把oplog设置大一些也不碍事。使用rs.printReplicationInfo()可以查看oplog大小以及预计窗口覆盖时间。
|
1
2
3
4
5
6
|
test:PRIMARY> rs.printReplicationInfo()
configured oplog size: 1024MB <--集合大小
log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
|
4.2 Oplog大小应随着实际使用压力而增加
如果我能够对我复制集的工作情况有一个很好地预估,如果可能会出现以下的情况,那么我们就可能需要创建一个比默认大小更大的oplog。相反的,如果我们的应用主要是读,而写操作很少,那么一个小一点的oplog就足够了。
下列情况我们可能需要更大的oplog。
4.2.1 同时更新大量的文档。
Oplog为了保证 幂等性 会将多项更新(multi-updates)转换为一条条单条的操作记录。这就会在数据没有那么多变动的情况下大量的占用oplog空间。
4.2.2 删除了与插入时相同大小的数据
如果我们删除了与我们插入时同样多的数据,数据库将不会在硬盘使用情况上有显著提升,但是oplog的增长情况会显著提升。
4.2.3 大量In-Place更新
如果我们会有大量的in-place更新,数据库会记录下大量的操作记录,但此时硬盘中数据量不会有所变化。
4.3 Oplog幂等性
Oplog有一个非常重要的特性——幂等性(idempotent)。即对一个数据集合,使用oplog中记录的操作重放时,无论被重放多少次,其结果会是一样的。举例来说,如果oplog中记录的是一个插入操作,并不会因为你重放了两次,数据库中就得到两条相同的记录。
5)Oplog的状态信息
我们可以通过 rs.printReplicationInfo() 来查看oplog的状态,包括大小、存储的操作的时间范围。关于oplog的更多信息可以参考Check the Size of the Oplog。
|
1
2
3
4
5
6
|
test:PRIMARY> rs.printReplicationInfo()
configured oplog size: 1024MB <--集合大小
log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
|
在各类异常情况下,从节点oplog的更新可能落后于主节点一些时间。在从节点上通过 db.getReplicationInfo() 和 db.getReplicationInfo可以获得现在复制集的状态与,也可以知道是否有意外的复制延时。
|
1
2
3
4
5
6
7
8
9
10
|
test:SECONDARY> db.getReplicationInfo()
{
"logSizeMB" : 1024,
"usedMB" : 168.06,
"timeDiff" : 7623151,
"timeDiffHours" : 2117.54,
"tFirst" : "Fri Aug 19 2016 12:27:04 GMT+0800 (CST)",
"tLast" : "Tue Nov 15 2016 17:59:35 GMT+0800 (CST)",
"now" : "Tue Dec 06 2016 11:27:36 GMT+0800 (CST)"
}
|
6)复制集数据同步过程
Mongodb复制集里的Secondary会从Primary上同步数据,以保持副本集所有节点的数据保持一致,数据同步主要包含2个过程
6.1 initial sync
6.2 replication(oplog sync)
先通过initial sync同步全量数据,再通过replication不断重放Primary上的oplog同步增量数据。
initial sync
初始同步会将完整的数据集复制到各个节点上,Secondary启动后,如果满足以下条件之一,会先进行initial sync。
1. Secondary上oplog为空,比如新加入的空节点。
2. local.replset.minvalid集合里_initialSyncFlag标记被设置。当initial sync开始时,同步线程会设置该标记,当initial sync结束时清除该标记,故如果initial sync过程中途失败,节点重启后发现该标记被设置,就知道应该重新进行initial sync。
3. BackgroundSync::_initialSyncRequestedFlag被设置。当向节点发送resync命令时,该标记会被设置,此时会强制重新initial sync。
initial sync同步流程
1. minValid集合设置_initialSyncFlag(db.replset.minvalid.find())。
2. 获取同步源当前最新的oplog时间戳t0。
3. 从同步源克隆所有的集合数据。
4. 获取同步源最新的oplog时间戳t1。
5. 同步t0~t1所有的oplog。
6. 获取同步源最新的oplog时间戳t2。
7. 同步t1~t2所有的oplog。
8. 从同步源读取index信息,并建立索引(除了_id ,这个之前已经建立完成)。
9. 获取同步源最新的oplog时间戳t3。
10. 同步t2~t3所有的oplog。
11. minValid集合清除_initialSyncFlag,initial sync结束。
当完成了所有操作后,该节点将会变为正常的状态secondary。
replication (sync oplog)
initial sync结束后,Secondary会建立到Primary上local.oplog.rs的tailable cursor,不断从Primary上获取新写入的oplog,并应用到自身。Tailable cursor每次会获取到一批oplog,Secondary采用多线程重放oplog以提高效率,通过将oplog按照所属的namespace进行分组,划分到多个线程里,保证同一个namespace的所有操作都由一个线程来replay,以保证统一namespace的操作时序跟primary上保持一致(如果引擎支持文档锁,只需保证同一个文档的操作时序与primary一致即可)。
同步场景分析
1. 副本集初始化
初始化选出Primary后,此时Secondary上无有效数据,oplog是空的,会先进行initial sync,然后不断的应用新的oplog。
2. 新成员加入
因新成员上无有效数据,oplog是空的,会先进行initial sync,然后不断的应用新的oplog。
3. 有数据的节点加入
有数据的节点加入有如下情况:
A.该节点与副本集其他节点断开连接,一段时间后恢复
B.该节点从副本集移除(处于REMOVED)状态,通过replSetReconfig命令将其重新加入
C.其他? 因同一个副本集的成员replSetName配置必须相同,除非有误配置,应该不会有其他场景
此时,如果该节点最新的oplog时间戳,比所有节点最旧的oplog时间戳还要小,该节点将找不到同步源,会一直处于RECOVERING而不能服务;反之,如果能找到同步源,则直接进入replication阶段,不断的应用新的oplog。
因oplog太旧而处于RECOVERING的节点目前无法自动恢复,需人工介入处理(故设置合理的oplog大小非常重要),最简单的方式是发送resync命令,让该节点重新进行initial sync。
7)多线程复制
MongoDB允许通过多线程进行批量写操作来提高并发能力,MongoDB将批操作通过命名空间来分组。
MongoDB复制集的工作原理介绍(二)的更多相关文章
- MongoDB副本集的工作原理
在MongoDB副本集中,主节点负责处理客户端的读写请求,备份节点则负责映射主节点的数据. 备份节点的工作原理过程可以大致描述为,备份节点定期轮询主节点上的数据操作,然后对自己的数据副本进行这些操作, ...
- MongoDB复制集成员及架构介绍(一)
MongoDB复制集介绍 MongoDB支持在多个机器中通过异步复制达到提供了冗余,增加了数据的可用性.MongoDB有两种类型的复制,第一种是同于MySQL的主从复制模式(MongoDB已不再推荐此 ...
- MongoDB学习4:MongoDB复制集机制和原理,搭建复制集
1.复制集的作用 1.1 MongoDB复制集的主要意义在于实现服务高可用 1.2 它的实现依赖于两个方面的功能: · 数据写入时将数据迅速复制到另一个独立节点上 · 在接收写入的 ...
- MongoDB复制集原理
版权声明:本文由孔德雨原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/136 来源:腾云阁 https://www.qclo ...
- MongoDB复制集原理、环境配置及基本测试详解
一.MongoDB复制集概述 MongoDB复制集实现了冗余备份和故障转移两大功能,这样能保证数据库的高可用性.在生产环境,复制集至少包括三个节点,其中一个必须为主节点,一个从节点,一个仲裁节点.其中 ...
- MongoDB 复制集 (一) 成员介绍
一 MongoDB 复制集简介 MongoDB的复制机制主要分为两种: Master-Slave (主从复制) 这个已经不建议使用 ...
- Raft与MongoDB复制集协议比较
在一文搞懂raft算法一文中,从raft论文出发,详细介绍了raft的工作流程以及对特殊情况的处理.但算法.协议这种偏抽象的东西,仅仅看论文还是比较难以掌握的,需要看看在工业界的具体实现.本文关注Mo ...
- MongoDB复制集高可用选举机制(三)
复制集高可用选举机制 在上一章介绍了MongoDB的架构,复制集的架构直接影响着故障切换时的结果.为了能够有效的故障切换,请确保至少有一个节点能够顺利升职为主节点.保证在拥有核心业务系统的数据中心中拥 ...
- 02 . MongoDB复制集,分片集,备份与恢复
复制集 MongoDB复制集RS(ReplicationSet): 基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB)Paxos(mysql MGR 用的是变种)) 如果发生主 ...
随机推荐
- 【MySQL8】 安装后的简单配置(主要解决navicat等客户端登陆报错问题)
一.navicat等客户端登陆报错的原因 使用mysql,多数我们还是喜欢用可视化的客户端登陆管理的,个人比较喜欢用navicat.一般装好服务器以后,习惯建一个远程的登陆帐号,在mysql8服务器上 ...
- 精品绿色便携软件 & 录制操作工具
https://www.vtaskstudio.com/index.php 录制宏工具 https://soft.anruan.com/29821/ TinyTask V1.5 电脑版 https ...
- Clojure学习之比线性箭头操作
1. 单箭头( -> ) 单箭头操作符会把其参数form迭代式地依次插入到相邻的下个一个form中作为该form的第一个参数.这就好像把这些form串起来了,即线性化(Threading). 由 ...
- sencha touch Container
Container控件是我们在实际开发中最常用的控件,大部分视图控件都是继承于Container控件,了解此控件能帮我们更好的了解sencha touch. layout是一个很重要的属性,能够帮助你 ...
- JVM学习--内存分配策略(持续更新)
一.前言 最近学习<深入java虚拟机>,目前看到内存分配策略这块.本文将进行一些实践. 二.内存分配策略 1.大对象直接进入老年代 书中提到了: 下面进行测试,代码如下: public ...
- pycharm的版本问题
1.分类: 专业版是收费的 Professional 教育版是免费 edu https://www.jetbrains.com/pycharm-edu/whatsnew/ 社区版是免费的 Free C ...
- 23种设计模式之命令模式(Command)
命令模式是一种对象的行为型模式,类似于传统程序设计方法中的回调机制,它将一个请求封装为一个对象,从而使得可用不同的请求对客户进行参数化:对请求排队或者记录请求日志,以及支持可撤销的操作.命令模式是对命 ...
- Android按钮事件的4种写法
经过前两篇blog的铺垫,我们今天热身一下,做个简单的例子. 目录结构还是引用上篇blog的截图. 具体实现代码: public class MainActivity extends Activity ...
- 【CF932G】Palindrome Partition 回文自动机
[CF932G]Palindrome Partition 题意:给你一个字符串s,问你有多少种方式,可以将s分割成k个子串,设k个子串是$x_1x_2...x_k$,满足$x_1=x_k,x_2=x_ ...
- 【BZOJ1417】Pku3156 Interconnect 记忆化搜索
[BZOJ1417]Pku3156 Interconnect Description 给出无向图G(V, E). 每次操作任意加一条非自环的边(u, v), 每条边的选择是等概率的. 问使得G连通的期 ...