PYTHON之爬虫学习(一)基础
关于python爬虫,大家都很熟悉,那么我就不多说,开始做了。
首先,python爬虫先安装python库,主要是requests库,在windows中cmd中输入,pip install requests ,之后会自动安装。
之后再python IDLE 中输入import requests 无报错说明安装正确。
下面试试爬取百度页面:
最简单的方式
import requests
r=requests.get("http://www.baidu.com")
print(r.text)
返回的结果:
<!DOCTYPE html> <!--STATUS OK--><html> <head>
<meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge> <meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css>
<title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc>
<div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form>
<div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div>
<form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1>
<input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8>
<input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1>
<input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>
</span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn"></span> </form>
</div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a>
<a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a>
<a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a>
<a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a>
<noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a>
</noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å ³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿ è¯»</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
返回页面的所有代码
PYTHON之爬虫学习(一)基础的更多相关文章
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- Python网络爬虫学习手记(1)——爬虫基础
1.爬虫基本概念 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.--------百度百科 简单的说,爬 ...
- python之爬虫学习记录与心得
之前在寒假的时候,学习了python基础.在慕课网上看的python入门:http://www.imooc.com/learn/177 python进阶:http://www.imooc.com/le ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- python网络爬虫学习笔记(一)Request库
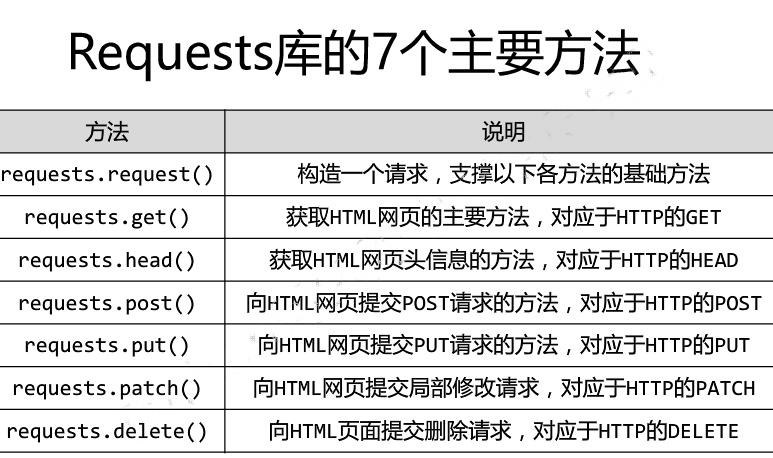
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- Python scrapy爬虫学习笔记01
1.scrapy 新建项目 scrapy startproject 项目名称 2.spiders编写(以爬取163北京新闻为例) 此例中用到了scrapy的Itemloader机制,itemloade ...
- python网络爬虫学习
网络爬虫 Requests官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html Beautiful So ...
- python beautifulsoup爬虫学习
BeautifulSoup(page_html, "lxml").select(),这里可以通过浏览器开发者模式选择copy selector,并且并不需要完整路径. github ...
随机推荐
- 基于ansj_seg和nlp-lang的简单nlp工具类
1.首先在pom中引入ansj_seg和nlp-lang的依赖包, ansj_seg包的作用: 这是一个基于n-Gram+CRF+HMM的中文分词的java实现: 分词速度达到每秒钟大约200万字左右 ...
- Linux网络编程之套接字基础
1.套接字的基本结构 struct sockaddr 这个结构用来存储套接字地址. 数据定义: struct sockaddr { unsigned short sa_family; /* addre ...
- xxx_initcall相关知识
参考文件include/linux/init.h /* * Early initcalls run before initializing SMP. * * Only for built-in cod ...
- centos 安装flash
linux系统中安装flash插件 linux中安装flashplayer插件的简单方法: 1.下载其中最新版本的播放器,下载地址: http://get.adobe.com/cn/flashplay ...
- jstorm相关
https://www.cnblogs.com/antispam/p/4182210.html
- 【LabVIEW技巧】代码块快速放置
前言 之前的文章中介绍了如何使用QuickDrop来实现快速代码放置,今天我们来详细的聊一下如何进行代码块的快速放置. 正文 LabVIWE程序设计中,我们在架构层级总是进行重复性的编写.举一个例子: ...
- echarts断点连线问题 终级
/** * * 测试关系图 graph type* */var coors1 = [['1', 0],['2', 182],['5', 290],['6', 330],['7', 310],['10' ...
- js字符串与Unicode编码互相转换
).toString() "597d" 这段代码的意思是,把字符'好'转化成Unicode编码,toString()就是把字符转化成16进制了 看看charCodeAt()是怎么个 ...
- LeetCode218. The Skyline Problem
https://leetcode.com/problems/the-skyline-problem/description/ A city's skyline is the outer contour ...
- redis之(十五)redis的集群中的哨兵角色
一:redis集群的哨兵的目的是什么?. (1)监控主redis和从redis数据库是否正常运行 (2)主redis出现故障,自动将其中一台从redis升级为主redis.将原先的主redis转变成从 ...