如何在Ubuntu的idea上运行Hadoop程序
如何在Ubuntu的idea上运行Hadoop程序
一、前言
在idea上运行Hadoop程序,需要使用Hadoop的相关库,Ubuntu为Hadoop的运行提供了良好的支持。
二、操作方法
首先我们需要创建一个maven项目,然后在pom.xml中进行设置,导入必要的包,最后写出mapreduce程序即可。
其中pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.zyr.bigdata</groupId>
<artifactId>MapReduce</artifactId>
<version>1.0-SNAPSHOT</version> <name>MapReduce</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.0</version>
</dependency> </dependencies> <build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
然后是编写代码:
package com.zyr.bigdata; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
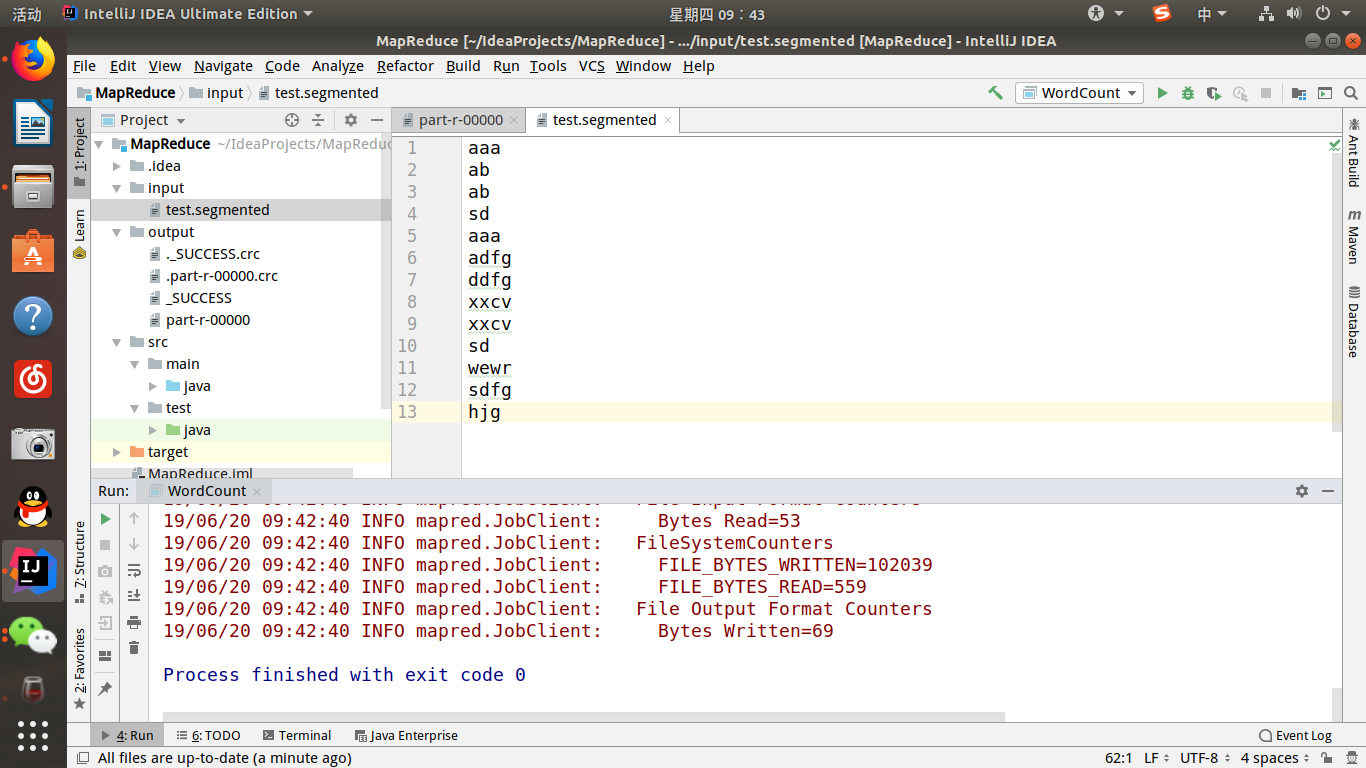
因为是mapreduce的词频统计,因此需要读入文件,在src同级创建input文件夹,里面放入文档即可。
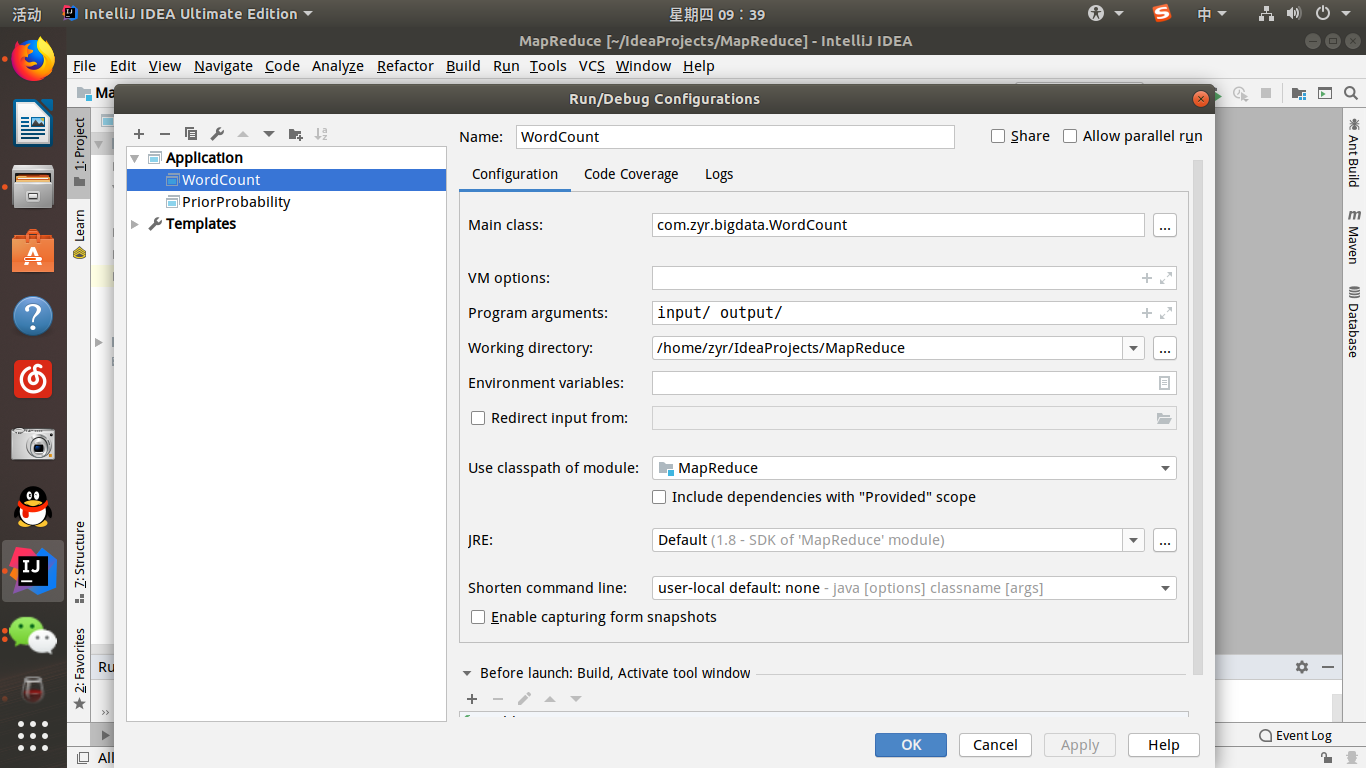
最后需要配置执行程序的设置(在run->edit configure中新建application即可):
然后运行程序,会生成相应的output文件夹,打开即可查看结果。 
至此,最简单的mapreduce程序就完成了,需要注意的是使用maven我们没有在ubuntu上安装相应的Hadoop,因为这是最简单的单机环境,使用的是本地文件系统,但是如果使用分布式的时候就必须需要本地安装Hadoop来提供访问服务了。
如何在Ubuntu的idea上运行Hadoop程序的更多相关文章
- 关于在Eclipse上运行Hadoop程序的日志输出问题
在安装由Eclipse-Hadoop-Plugin的Eclipse中, 可以直接运行Hadoop的MapReduce程序, 但是如果什么都不配置的话你发现Eclipse控制台没有任何日志输出, 这个问 ...
- Ubuntu中使用终端运行Hadoop程序
接上一篇<Ubuntu Kylin系统下安装Hadoop2.6.0> 通过上一篇,Hadoop伪分布式基本配好了. 下一步是运行一个MapReduce程序,以WordCount为例: 1. ...
- Ubuntu下Eclipse中运行Hadoop程序的参数问题
需要统一的参数: 当配置好eclipse中hadoop的程序后,几个参数需要统一一下: hadoop安装目录下/etc/core_site.xml中 fs.default.name的端口号一定要与ha ...
- Ubuntu 12.04上安装Hadoop并运行
Ubuntu 12.04上安装Hadoop并运行 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在官网上下载好四个文件 在Ubuntu的/home/w ...
- 如何在Ubuntu 18.04上安装Pip
一.简介: Pip是一个软件包管理系统,它简化了用Python编写的软件包(如Python包索引(PyPI)中的软件包)的安装和管理. 在Ubuntu 18.04上缺省没有安装Pip,但安装非常简单. ...
- 转载:如何在Ubuntu 18.04上使用UFW设置防火墙
https://blog.csdn.net/u013068789/article/details/82051943 介绍 UFW或Uncomplicated Firewall是iptables一个接口 ...
- 如何在Ubuntu 18.04上安装Django
Django是一个免费的开源高级Python Web框架,旨在帮助开发人员构建安全,可扩展和可维护的Web应用程序. 根据您的需要,有不同的方法来安装Django.它可以使用pip在系统范围内安装或在 ...
- 如何在Ubuntu 16.04上安装配置Redis
如何在Ubuntu 16.04上安装配置Redis Redis是一个内存中的键值存储,以其灵活性,性能和广泛的语言支持而闻名.在本指南中,我们将演示如何在Ubuntu 16.04服务器上安装和配置Re ...
- 如何在Ubuntu 18.04上安装和配置Apache 2 Web服务器(转)
如何在Ubuntu 18.04上安装和配置Apache 2 Web服务器 什么是Apache Web Server? Apache或Apache HTTP服务器是一个免费的开源Web服务器,由Apac ...
随机推荐
- python--基础知识点梳理(之数据结构)
数据结构: # 按逻辑结构(面向问题)分为:集合结构.线性结构.树形结构.图形结构 # 按物理结构(面向计算机)分为: # 顺序存储结构(把数据元素放在地址连续的存储单元中,数据间的逻辑关系和物理关系 ...
- C语言程序设计100例之(9):生理周期
例9 生理周期 问题描述 人生来就有三个生理周期,分别为体力.感情和智力周期,它们的周期长度为 23 天.28 天和33 天.每一个周期中有一天是高峰.在高峰这天,人会在相应的方面表现出色.例如 ...
- Java实现编辑距离算法
Java实现编辑距离算法 编辑距离,又称Levenshtein距离(莱文斯坦距离也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它 ...
- Java中的集合-您必须知道的13件事
Java Collections Framework是Java编程语言的核心部分之一.集合几乎用于任何编程语言中.大多数编程语言都支持各种类型的集合,例如List, Set, Queue, Stack ...
- 前端笔记之Vue(六)分页排序|酷表单实战&Vue-cli
一.分页排序案例 后端负责提供接口(3000) 前端负责业务逻辑(8080) 接口地址:从8080跨域到3000拿数据 http://127.0.0.1:3000/shouji http://127. ...
- 06-Django视图
什么是视图? 视图就是应用中views.py文件中的函数,视图函数的第一个参数必须是request(HttpRequest)对象.返回的时候必须返回一个HttpResponse对象或子对象(包含Htt ...
- 洛谷 P2657 (数位DP)
### 洛谷 P2657 题目链接 ### 题目大意:给你一个数的范围 [A,B] ,问你这段区间内,有几个数满足如下条件: 1.两个相邻数位上的数的差值至少为 2 . 2.不包含前导零. 很简单的数 ...
- EJB组件开发实记(1)
安装JBoss或者Wildfly jdk1.4以上. Eclipes安装插件 JBoss Tools: eclipes Jee photon 在eclipes 内部点击 >>Windows ...
- PHP fastcgi_finish_request 方法
本文介绍,PHP运行在FastCGI模式时,FPM提供的方法:fastcgi_finish_request. 在说这个方法之前,我们先了解PHP有哪些常用的运行模式? PHP运行模式 CGI 通用网关 ...
- node 连接 mysql 数据库三种方法------笔记
一.mysql库 文档:https://github.com/mysqljs/mysql mysql有三种创建连接方式 1.createConnection 使用时需要对连接的创建.断开进行管理 2. ...