LInkHashMap源码分析
说LinkHashMap之前,我们先来谈谈什么是LRU算法?
按照英文的直接原义就是Least Recently Used,最近最久未使用法,它是按照一个非常注明的计算机操作系统基础理论得来的:最近使用的页面数据会在未来一段时期内仍然被使用,已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。基于这个思想,会存在一种缓存淘汰机制,每次从内存中找到最久未使用的数据然后置换出来,从而存入新的数据!它的主要衡量指标是使用的时间,附加指标是使用的次数。在计算机中大量使用了这个机制,它的合理性在于优先筛选热点数据,所谓热点数据,就是最近最多使用的数据!因为,利用LRU我们可以解决很多实际开发中的问题,并且很符合业务场景。
双向循环链表
public class LinkedHashMap<K,V>extends HashMap<K,V>{
transient LinkedEntry<k,V> header; //头结点
private final boolean accessOrder; //true:访问排序 false:插入排序
public LinkedHashMap(){
init();
accessOrder=false; //默认情况为false,基于插入排序的
}
static class LinkedEntrykK,V> extends HashMapEntry<K, V> //linkedEntry继承了HashMapEntry,也就拥有了父类的所有属性和方法
{
LinkedEntry<K, V> nxt;
LinkedEntry<K, V> prv;
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<k, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
linkedHashMap只是重写了hashMap put方法里的addNewEntry增加新元素方法
header:头结点
eldest:最先进来的结点(最老的)
oldTail:
newTail:新添加的结点
table[index]:一维数组,把新的尾巴加入到table[index]里面来
@Override
void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header; LinkedEntry<K, V> eldest = header.nxt; if (eldest != header && removeEldestEntry(eldest)) {如果头结点不是自己抱自己
remove(eldest.key);
}
LinkedEntry<K, V> oldTail = header.prv;
//添加一个新元素
LinkedEntry<K, V> newTail = new LinkedEntry<K, V>(
key, value, hash, table[index], header(next), oldTail(previous)); //做构造函数时newTail.next指向header
①table[index] = ②oldTail.nxt = ③header.prv = ④newTail; 4=3 4=2 2=1
}
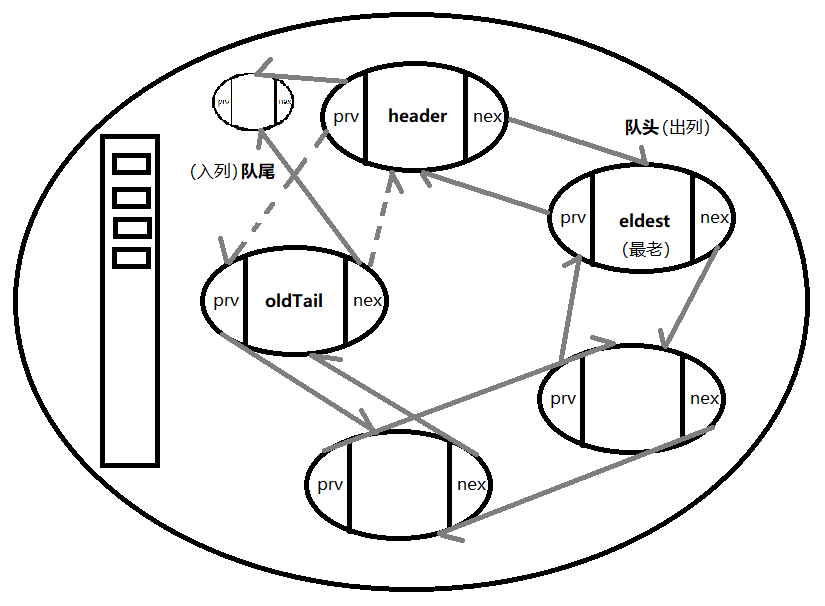 因为新加进来的元素是在队尾插入的,不断插入元素的话就不断移动,如果eldest没有用了,将来就用removeEldestEntry方法移除
因为新加进来的元素是在队尾插入的,不断插入元素的话就不断移动,如果eldest没有用了,将来就用removeEldestEntry方法移除
//默认构造方法,头结点自己指向自己,也就是自己抱自己
@Override void init(){
header]=new uinkedEntry<K,V>(); LinkedEntry(){
super(nu11,nul1,0,null); nxt = prv = this;
隐藏了一列一维数组,将来还是有用的
默认return false;不会移除 方法的作用:是在内存过高时,移除最老的元素,所以需要重写这个方法,return true;
protected boolean removeEldestEntry(Map. Entry<k,V>eldest){
return false;
}
访问
如果要访问 包含头结点顺时针第四个元素,让它成为最新的,就需要把第五个和第三个结点连起来,再在队尾用addNewEntry方法添加一个newTail
e:访问到的元素
@Override
public V get(Object key) {
if (key == null) {
HashMapEntry<k, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTai1((LinkedEntry<K, V>) e);
return e.value;
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<k, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKeyI = e.key;
if (ekey == key Il(e.hash == hash && key.equals(ekey))){ //如果找到了这个元素
if (accessOrder)
makeTail((LinkedEntry<K, V>) e); //将访问到的元素当做尾巴反正队尾添加进来
return e.value;
}
}
return null;
}
private void makeTail(LinkedEntry<k, V> e) {
e.prv.nxt = e.nxt; //e.prv(a).nxt=e.nxt(oldTail)
e.nxt.prv = e.prv;
LinkedEntry<K, V> header = this.header;
LinkedEntryf, V > oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
o1dTail.nxt = header.prv = e;
modCount++;
}
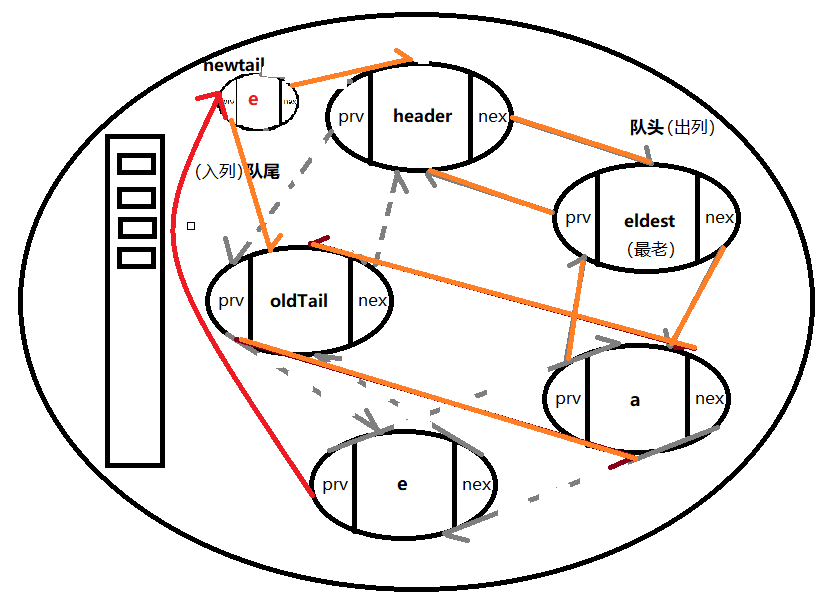
新进来的要放在队头
最后进来的是最新的
顺序存储,谁先存进来的,谁先被移出去。
访问排序,谁最近被访问就是最活跃的,最后才被移出去
LInkHashMap源码分析的更多相关文章
- spark-streaming-kafka-0-10源码分析
转发请注明原创地址http://www.cnblogs.com/dongxiao-yang/p/7767621.html 本文所研究的spark-streaming代码版本为2.3.0-SNAPSHO ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- java使用websocket,并且获取HttpSession,源码分析
转载请在页首注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6238826.html 一:本文使用范围 此文不仅仅局限于spring boot,普通的sprin ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
随机推荐
- LeetCode刷题191118
博主渣渣一枚,刷刷leetcode给自己瞅瞅,大神们由更好方法还望不吝赐教.题目及解法来自于力扣(LeetCode),传送门. 算法: 给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按 ...
- Linux 定位进程对应的文件路径
ls -al /proc/[pid]/exe # 例如: [root@localhost ~]# ls -al /proc/9109/exe lrwxrwxrwx. 1 ibaboss ibaboss ...
- nvidia quadro m5000 驱动安装 - 1804 ubuntu; nvidia-smi topo --matrix 查看gpu拓扑;nvidia-smi命令使用;
查看GPU型号: lspci | grep -i nvidia 驱动安装: https://www.nvidia.cn/Download/index.aspx?lang=cn 下载对应版本的驱动驱动程 ...
- vue/cli2.0优化
vue/cli2.0 脚手架 在项目写完了之后, 运行npm run build --report可以看出这个项目的资源占比情况.可以看出整个项目哪一个资源在整个项目占比最大.它会自动打开一个可视化的 ...
- 【2019.8.20 NOIP模拟赛 T2】小B的树(tree)(树形DP)
树形\(DP\) 考虑设\(f_{i,j,k}\)表示在\(i\)的子树内,从\(i\)向下的最长链长度为\(j\),\(i\)子树内直径长度为\(k\)的概率. 然后我们就能发现这个东西直接转移是几 ...
- Nacos集群搭建过程详解
Nacos的单节点,也就是我们最开始使用的standalone模式,配置的数据是默认存储到内嵌的数据库derby中. 如果我们要搭建集群的话,那么肯定是不能用内嵌的数据库,不然数据无法共享.集群搭建的 ...
- 用OC实现一个栈:结合单链表创建动态栈
一.介绍 栈是一种数据存储结构,存储的数据具有先进后出的特点.栈一般分为动态栈和静态栈. 静态栈比较好理解,例如用数组实现的栈.动态栈可以用链表来实现. 方式:固定base指针,每次更改top指向入栈 ...
- 《js高程》笔记总结一:基本概念(语法,数据类型,流程控制,函数)
1.ECMA 欧洲计算机制造商协会 2.";"的作用 代码后的:当压缩代码时可以用于压缩代码,有效的间隔开代码. 3.数据类型有 undefined,null,boolean,st ...
- 【Linux命令】EOF自定义终止符
EOF自定义终止符用法 我们在脚本中经常会发现使用EOF的情况.EOF可以结合cat命令对内容进行追加.比如:执行脚本的时候,需要往一个文件里自动输入多行内容.如果是少数的几行内容,可以用echo命令 ...
- 【shell脚本】一键部署LNMP===deploy.sh
一键部署mysql,php,nginx,通过源码安装部署 #!/bin/bash # 一键部署 LNMP(源码安装版本) menu() { clear echo " ############ ...