快速排序的理解和实现(Java)
快速排序介绍
快速排序(Quick Sort)使用分治法策略,其基本思想是:通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另外一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
快排流程:
- 从数列中选取一个基数
- 将所有比基数小的摆放在基数前面,所有比基数大的摆在基数的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
- 递归地把"基数前面的子数列"和"基数后面的子数列"进行快速排序。
举例说明:
(PS:本例参考一个大神的博客:http://www.cnblogs.com/skywang12345/p/3596746.html#a1)
数列a={30,40,60,10,20,50}为例,演示它的快速排序过程(如下图)
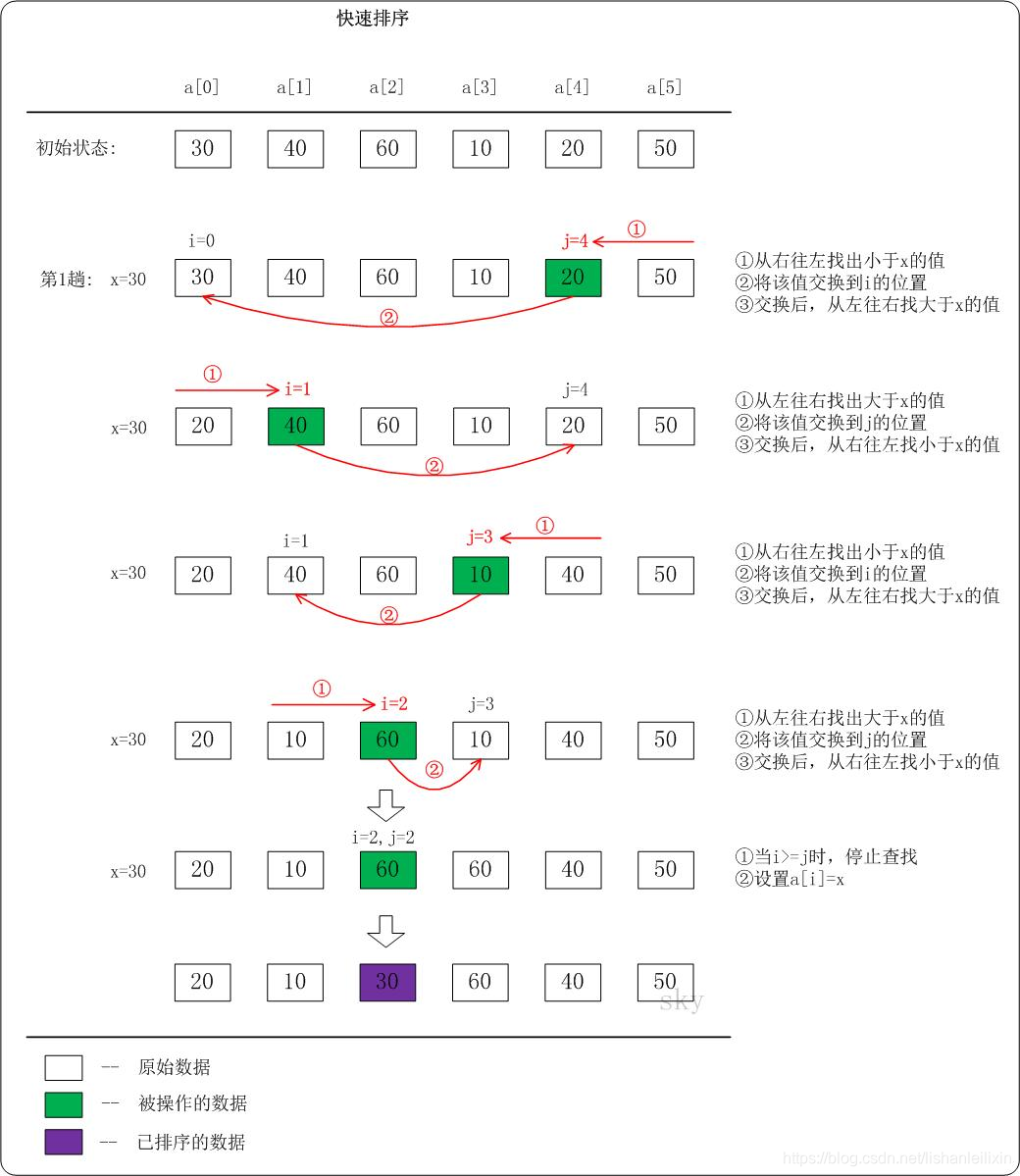
上图只是给出了第1趟快速排序的流程,按照同样的方法,对子数列进行递归遍历。最后可以得到有序序列。
代码实现:
//对顺序表elem进行快速排序
public void quickSort(int[] elem) {
QSort_2(elem, 1, elem.length - 1);
}
//对顺序表elem中的子序列elem[start...end]做快速排序
public void QSort(int[] elem, int start, int end) {
int pivot;
if(start < end) {
pivot = Partition(elem ,start, end);
QSort(elem, start, pivot - 1);
QSort(elem, pivot + 1, end);
}
}
/**
* 交换顺序表elem中字表记录,使基数记录到位,并返回其所在位置
* 此时在它之前(后)的记录均不大(小)于它
* @param elem
* @param low
* @param high
* @return
*/
public int Partition(int[] elem, int low, int high) {
int pivotkey = elem[low];
while(low < high) {
while((low < high) && (elem[high] >= pivotkey)) {
high--;
}
swap(elem, low, high);
while((low < high) && (elem[low] <= pivotkey)) {
low++;
}
swap(elem, low, high);
}
return low;
}
快速排序复杂度分析
(PS:由于本人数学功底太弱,并没有理解快排复杂度的推演公式,在此只是摘抄于《大话数据机构》)
在最优情况下,如果排序n个关键字,其递归树的深度就是[log2log_2log2n] + 1([x]表示不大于x的最大整数),即仅需要递归log2log_2log2n次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后获得的基数将数组一分为二,那么各自还需要T(n2\frac{n}{2}2n)的时间(注意这是最好情况下,所以平分两半)。于是不断划分下去,就有下面不等式推断
T(n) ≤ 2T(n2\frac{n}{2}2n) + n, T(1)=0
T(n) ≤2(2T(n4\frac{n}{4}4n)+n2\frac{n}{2}2n) + n=4T(n4\frac{n}{4}4n) +2n
T(n) ≤ 4(2T(n8\frac{n}{8}8n)+n4\frac{n}{4}4n) + 2n=8T(n8\frac{n}{8}8n) +3n
…
T(n) ≤ nT(1) + (log2log_2log2n) * n= O(nlog\loglogn)
也就是说在最优情况下,快排算法的时间复杂度为O(nlog\loglogn)
在最坏情况下,待排序的序列为正序或者逆序,每次划只得到一个比上次划分少一个记录的子序列,注意另一个是空。如果画出递归树,那么就是一棵斜树。此时需要执行n-1次递归调用,且第i次划分需要经过n-i次关键字的比较才能找到第i个记录,也就是基数的位置,因此比较次数为:
∑i=1n−1(n−i)=n−1+n−2+...+1=n(n−1)2\sum_{i=1}^{n-1}(n-i)=n-1+n-2+...+1= \frac{n(n-1)}{2}i=1∑n−1(n−i)=n−1+n−2+...+1=2n(n−1)
最终其时间复杂度为O(n2n^2n2)
平均情况下,设基数的关键字应该在第k的位置(1≤k≤n),那么
T(n)=1n∑k=1n(T(k−1)+T(n−k))+n=2n∑k=1nT(k)+nT(n)=\frac{1}{n}\sum_{k=1}^{n}(T(k-1) + T(n-k))+n= \frac{2}{n}\sum_{k=1}^{n}T(k)+nT(n)=n1k=1∑n(T(k−1)+T(n−k))+n=n2k=1∑nT(k)+n
有数学归纳法可证明,其数量级为O(nlog\loglogn)
就空间复杂度来说,主要是递归造成的栈空间的使用,最好情况下递归树的深度为log2log_2log2n,其空间复杂度也就为O(log\loglogn),最坏情况下,需要进行n-1次递归调用,其空间复杂度为O(n),平均情况下,空间复杂度为O(log\loglogn)。
由于关键字的比较和交换是跳跃式的进行,所以快速排序是一种不稳定的排序方法。
快速排序的优化
优化选取基数
采用三数取中法,即取三个关键字先进性排序,将中间数做为基数,一般是取左端,右端和中间三个数。
//三分取中法
public int Partition_1(int[] elem, int low, int high) {
int pivotkey;
int m = low + (high - low) / 2;
if(elem[low] > elem[high]) {
swap(elem, low, high);
}
if(elem[m] > elem[high]) {
swap(elem, high, m);
}
if(elem[m] > elem[low]) {
swap(elem, low, m);
}
pivotkey= elem[low];
while(low < high) {
while((low < high) && (elem[high] >= pivotkey)) {
high--;
}
swap(elem, low, high);
while((low < high) && (elem[low] <= pivotkey)) {
low++;
}
swap(elem, low, high);
}
return low;
}
优化不必要的交换
//优化不必要的交换
public int Partition_2(int[] elem, int low, int high) {
int pivotkey = elem[low];
elem[0] = pivotkey;
while(low < high) {
while((low < high) && (elem[high] >= pivotkey)) {
high--;
}
elem[low] = elem[high];
while((low < high) && (elem[low] <= pivotkey)) {
low++;
}
elem[high] = elem[low];
}
elem[low] = elem[0];
return low;
}
采用替换而不是交换的方式进行操作,在性能上得到部分提升。
优化小数组时的排序
数组非常小,其快速排序不如直接插入(直插是简单排序中性能最好的)。
public final int MAX_LENGTH_INSERT_SORT = 7;
//优化小数组时的排序方案
public void QSort_1(int[] elem, int start, int end) {
int pivot;
if((end - start) > MAX_LENGTH_INSERT_SORT) {
pivot = Partition(elem ,start, end);
QSort(elem, start, pivot - 1);
QSort(elem, pivot + 1, end);
}
else insertSort(elem);
}
//直接插入
public void insertSort(int[] elem) {
int i, j;
for (i = 2; i < elem.length; i++) {
if(elem[i] < elem[i - 1]) {
elem[0] = elem[i];
for (j = i - 1; elem[j] > elem[0]; j--) {
elem[j + 1] = elem[j];
}
elem[j + 1] = elem[0];
}
}
}
优化递归操作
在QSort函数在其尾部有两次递归操作,若待排序序列极端不平衡,递归深度趋近于n,每次递归调用都会浪费栈空间,因此能够减少递归,将会大大提升性能。
对QSort进行尾递归操作:
//优化递归操作
public void QSort_2(int[] elem, int start, int end) {
int pivot;
if((end - start) > MAX_LENGTH_INSERT_SORT) {
while(start < end) {
pivot = Partition(elem ,start, end);
QSort(elem, start, pivot - 1);
start = pivot + 1;
}
}
else insertSort(elem);
}
因为第一次循环后start就没了作用,可将pivot+1赋给start,再循环后,来一次Partition(elem, low, high),其效果等同于“QSort(elem, pivot+1, end)”,结果相同,但采用迭代而不是递归可以缩减堆栈深度,从而提高性能。
快速排序的理解和实现(Java)的更多相关文章
- Atitit 深入理解命名空间namespace java c# php js
Atitit 深入理解命名空间namespace java c# php js 1.1. Namespace还是package1 1.2. import同时解决了令人头疼的include1 1.3 ...
- 理解和解决Java并发修改异常ConcurrentModificationException(转载)
原文地址:https://www.jianshu.com/p/f3f6b12330c1 理解和解决Java并发修改异常ConcurrentModificationException 不知读者在Java ...
- 深入理解和探究Java类加载机制
深入理解和探究Java类加载机制---- 1.java.lang.ClassLoader类介绍 java.lang.ClassLoader类的基本职责就是根据一个指定的类的名称,找到或者生成其对应的字 ...
- 深入理解什么是Java泛型?泛型怎么使用?【纯转】
本篇文章给大家带来的内容是介绍深入理解什么是Java泛型?泛型怎么使用?有一定的参考价值,有需要的朋友可以参考一下,希望对你们有所助. 一.什么是泛型 “泛型” 意味着编写的代码可以被不同类型的对象所 ...
- java中快速排序的理解以及实例
所谓的快速排序的思想就是,首先把数组的第一个数拿出来做为一个key,在前后分别设置一个i,j做为标识,然后拿这个key对这个数组从后面往前遍历,及j--,直到找到第一个小于这个key的那个数,然后交换 ...
- [转载] 深入理解Android之Java虚拟机Dalvik
本文转载自: http://blog.csdn.net/innost/article/details/50377905 一.背景 这个选题很大,但并不是一开始就有这么高大上的追求.最初之时,只是源于对 ...
- 如何理解和使用Java package包
Java中的一个包就是一个类库单元,包内包含有一组类,它们在单一的名称空间之下被组织在了一起.这个名称空间就是包名.可以使用import关键字来导入一个包.例如使用import java.util.* ...
- 深入理解JVM(6)——Java内存模型和线程
Java虚拟机规范中定义了Java内存模型(Java Memory Model,JMM)用来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果(“即Ja ...
- 理解JVM之Java内存区域
Java虚拟机运行时数据区分为以下几个部分: 方法区.虚拟机栈.本地方法栈.堆.程序计数器.如下图所示: 一.程序计数器 程序计数器可看作当前线程所执行的字节码行号指示器,字节码解释器工作时就是通过改 ...
随机推荐
- KbmMW 认证管理器说明(转载)
这是kbmmw 作者关于认证管理器的说明,我懒得翻译了,自己看吧. There are 5 parts of setting up an authorization manager: A) Defin ...
- 2018.09.07 Amount of degrees(数位dp)
描述 求给定区间[X,Y]中满足下列条件的整数个数:这个数恰好等于K个互不相等的B的整数次幂之和. 例如,设X=15,Y=20,K=2,B=2,则有且仅有下列三个数满足题意: 17 = 24+20, ...
- 2018.08.29 NOIP模拟 pmatrix(线性筛)
[问题描述] 根据哥德巴赫猜想(每个不小于 6 的偶数都可以表示为两个奇素数之和),定义 哥德巴赫矩阵 A 如下:对于正整数对(i,j),若 i+j 为偶数且 i,j 均为奇素数,则 Ai,j = 1 ...
- android 蓝牙通讯编程 备忘
1.启动App后: 判断->蓝牙是否打开(所有功能必须在打牙打开的情况下才能用) 已打开: 启动代码中的蓝牙通讯Service 未打开: 发布 打开蓝牙意图(系统),根据Activity返回进场 ...
- 数据分析工具R和RStudio入门介绍
https://www.cnblogs.com/yjd_hycf_space/p/6672995.html Python&R语言-python和r相遇:https://www.cnblogs. ...
- (网络流 模板 Edmonds-Karp)Drainage Ditches --POJ --1273
链接: http://poj.org/problem?id=1273 Drainage Ditches Time Limit: 1000MS Memory Limit: 10000K Total ...
- 给ubuntu系统的root设置密码:
首先输入:sudo passwd root 然后输入当前用户的密码,例如xiaomeige这个用户的密码为xiaomeige 然后输入希望给root账户设置的密码,例如密码也为root
- Vue2.5 Web App 项目搭建 (TypeScript版)
参考了几位同行的Blogs和StackOverflow上的许多问答,在原来的ng1加TypeScript以及Webpack的经验基础上,搭建了该项目,核心文件如下,供需要的人参考. package.j ...
- VSTS 更名为 Azure DevOps
微软正式对外宣布Azure DevOps,其实就是原来的VSTS,我们来看一下Azure DevOps的介绍: 今天我们宣布Azure DevOps.与世界各地的客户和开发人员合作,很明显,DevOp ...
- 【TFS错误】TF30063: 您没有访问 Microsoft-IIS/8.5 的权限
问题现象 开发人员报告,所有的生成都失败了,日志显示下载源代码出错,系统提示错误信息为"-TF30063: 您没有访问 Microsoft-IIS/8.5 的权限-". 图1 - ...