初识spark的MLP模型
初识Spark的MLP模型
1. MLP介绍
Multi-layer Perceptron(MLP),即多层感知器,是一个前馈式的、具有监督的人工神经网络结构。通过多层感知器可包含多个隐藏层,实现对非线性数据的分类建模。MLP将数据分为训练集、测试集、检验集。其中,训练集用来拟合网络的参数,测试集防止训练过度,检验集用来评估网络的效果,并应用于总样本集。当因变量是分类型的数值,MLP神经网络则根据所输入的数据,将记录划分为最适合类型。常被MLP用来进行学习的反向传播算法,在模式识别的领域中算是标准监督学习算法,并在计算神经学及并行分布式处理领域中,持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
2. 使用Java进行开发
2.1开发环境准备
- 基本Java开发环境
Eclipse,Maven,Jdk1.7
- spark开发需要环境
Windows操作系统保存训练模型必须要依赖于hadoop-common-2.2.0-bin-master,如果不保存模型不需要配置此环境,linux操作系统不需要配置此环境。
配置此环境有以下两种方法:
- 直接在代码最开始写
System.setProperty("hadoop.home.dir", "D:\\Programe\\hadoop-common-2.2.0-bin-master");
- 配置入环境变量
直接在Windows的系统变量里面配置HADOOP_HOME,然后在PATH里面配置HADOOP_HOME/bin
2.2项目搭建
- 创建简单的maven项目
- 在pom下增加下列jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.3</version>
<scope>runtime</scope>
</dependency>
注意:本例使用jdk1.7,spark2.2.x要求jdk1.8。
2.3官网实例
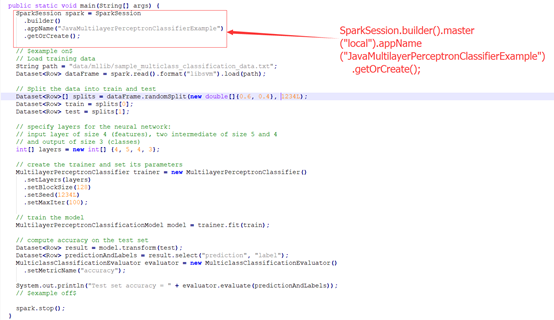
注意:创建SparkSession时添加.master(“local”)
2.4保存训练模型
上例是直接使用数据训练模型之后进行预测,大多数情况是模型只需训练一次,之后就可以直接使用,于是Spark提供了保存模型的方法。
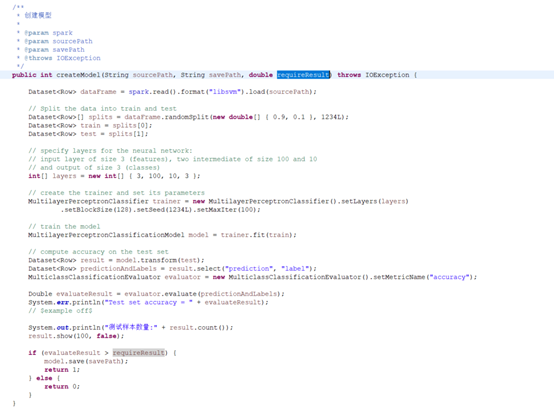
2.5获取训练模型

2.6其他相关知识
- Java类型数据转换为Spark数据类型
略
- 如何从word生成Spark可加载的libsvm的文档
略
3. 参考文档
hadoop-common-2.2.0-bin-master下载地址
https://github.com/srccodes/hadoop-common-2.2.0-bin
Spark的MPL例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
代码例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
初识spark的MLP模型的更多相关文章
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- 初识Spark(Spark系列)
1.Spark Spark是继Hadoop之后,另外一种开源的高效大数据处理引擎,目前已提交为apach顶级项目. 效率: 据官方网站介绍,Spark是Hadoop运行效率的10-100倍(随内存计算 ...
- Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存:另一个是两种共享变量,支持并行计算的广播变量和累加器. 1.RDD介绍 S ...
- Spark分布式计算执行模型
引言 相对Hadoop, Spark在处理需要迭代运算的机器学习训练等任务上有着很大性能提升,同时提供了批处理.实时数据处理.机器学习以及图算法等一站式的服务,因此最近大家一起来学习Spark,特别是 ...
- Spark2.1.0之初识Spark
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题:社交圈子从现实搬到了Facebook.Twitter.微信等社交平台上:女孩子们现在少了逛街,多了在各大电商平台上的 ...
- Spark 决策树--回归模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.evaluation.Regres ...
- Spark 决策树--分类模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.{D ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- 带你初识Angular中MVC模型
简介 MVC是一种使用 MVC(Model View Controller 模型-视图-控制器)设计模式,该模型的理念也被许多框架所吸纳,比如,后端框架(Struts.Spring MVC等).前端框 ...
随机推荐
- if __name__ == 'main': 的作用和原理
if __name__ == 'main': 功能 一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行. if __na ...
- sql语句应用
laravel5.6框架中用到的sql语句 //排序 $data=DB::table('admin')->select(array('id','name','password'))->or ...
- 用es5原生模仿-es6Promise异步处理
用es5原生模仿-es6Promise异步处理,不过在处理异常的时候有点小bug不是很完美,不过多级then 是没问题的和resolve, rejec 正常调用和异常处理调用是没问题的.本帖属于原创 ...
- Linux命令:source
语法 source filename 说明 . 的同义词
- docker原理(转)
可能是把Docker的概念讲的最清楚的一篇文章 [编者的话]本文只是对Docker的概念做了较为详细的介绍,并不涉及一些像Docker环境的安装以及Docker的一些常见操作和命令. Docker是世 ...
- 微信小程序 project.config.json 配置
可以在项目根目录使用 project.config.json 文件对项目进行配置. miniprogramRoot Path String 指定小程序源码的目录(需为相对路径) qcloudRoot ...
- html入门第二天。
二·1.图片与多媒体:-------------- img标签(重中之重): 网页中的图片展示就是用的img标签实现,img元素相网页中嵌入一幅图形,行内标签,单标签. 基础语句:<img sr ...
- java钉钉通讯录同步
钉钉做了好好几个项目了,和阿里云还有阿里钉钉合作也挺不错.因为之前就做过微信公众号,接触钉钉感觉还是比较顺手的,虽然也有一些不一样的地方. 因为之前写了一个微信公众号的开发文档,一直想写一个钉钉的开发 ...
- LeetCode至 少有 1 位重复的数字
给定正整数 N,返回小于等于 N 且具有至少 1 位重复数字的正整数. 示例 1: 输入:20 输出:1 解释:具有至少 1 位重复数字的正数(<= 20)只有 11 . 示例 2: 输入:10 ...
- IDEA中添加javap反编译