canal源码分析简介-2
3.0 server模块
server模块的核心接口是CanalServer,其有2个实现类CanalServerWithNetty、CanalServerWithEmbeded。关于CanalServer,官方文档中有有以下描述:
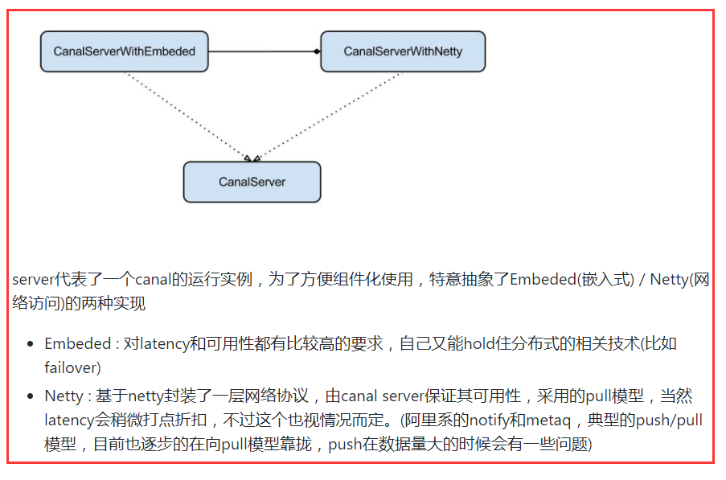
下图是笔者对官方文档的进一步描述:
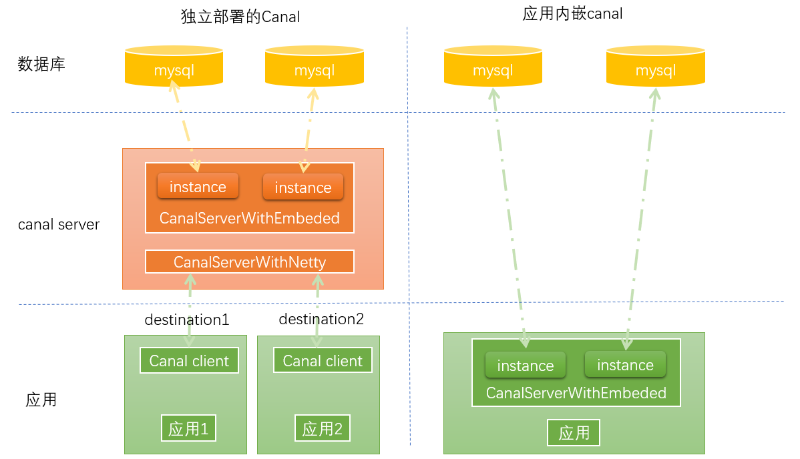
左边的图
表示的是Canal独立部署。不同的应用通过canal client与canal server进行通信,所有的canal client的请求统一由CanalServerWithNetty接受,之后CanalServerWithNetty会将客户端请求派给CanalServerWithEmbeded 进行真正的处理。CannalServerWithEmbeded内部维护了多个canal instance,每个canal instance伪装成不同的mysql实例的slave,而CanalServerWithEmbeded会根据客户端请求携带的destination参数确定要由哪一个canal instance为其提供服务。
右边的图
是直接在应用中嵌入CanalServerWithEmbeded,不需要独立部署canal。很明显,网络通信环节少了,同步binlog信息的效率肯定更高。但是对于使用者的技术要求比较高。在应用中,我们可以通过CanalServerWithEmbeded.instance()方法来获得CanalServerWithEmbeded实例,这一个单例。
整个server模块源码目录结构如下所示:
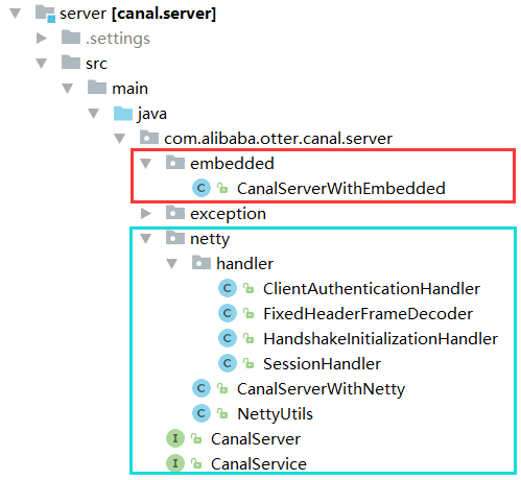
其中上面的红色框就是嵌入式实现,而下面的绿色框是基于Netty的实现。
看起来基于netty的实现代码虽然多一点,这其实只是幻觉,CanalServerWithNetty会将所有的请求委派给CanalServerWithEmbedded处理。
而内嵌的方式只有CanalServerWithEmbedded一个类, 是因为CanalServerWithEmbedded又要根据destination选择某个具体的CanalInstance来处理客户端请求,而CanalInstance的实现位于instance模块,我们将在之后分析。因此从canal server的角度来说,CanalServerWithEmbedded才是server模块真正的核心。
CanalServerWithNetty和CanalServerWithEmbedded都是单例的,提供了一个静态方法instance()获取对应的实例。回顾前一节分析CanalController源码时,在CanalController构造方法中准备CanalServer的相关代码,就是通过这两个静态方法获取对应的实例的。
- public CanalController(final Properties properties){
- ....
- // 准备canal server
- ip = getProperty(properties, CanalConstants.CANAL_IP);
- port = Integer.valueOf(getProperty(properties, CanalConstants.CANAL_PORT));
- embededCanalServer = CanalServerWithEmbedded.instance();
- embededCanalServer.setCanalInstanceGenerator(instanceGenerator);// 设置自定义的instanceGenerator
- canalServer = CanalServerWithNetty.instance();
- canalServer.setIp(ip);
- canalServer.setPort(port);
- ....
- }
CanalServer接口
CanalServer接口继承了CanalLifeCycle接口,主要是为了重新定义start和stop方法,抛出CanalServerException。
- public interface CanalServer extends CanalLifeCycle {
- void start() throws CanalServerException;
- void stop() throws CanalServerException;
- }
CanalServerWithNetty
CanalServerWithNetty主要用于接受客户端的请求,然后将其委派给CanalServerWithEmbeded处理。下面的源码显示了CanalServerWithNetty种定义的字段和构造方法
- public class CanalServerWithNetty extends AbstractCanalLifeCycle implements CanalServer {
- //监听的所有客户端请求都会为派给CanalServerWithEmbedded处理
- private CanalServerWithEmbedded embeddedServer; // 嵌入式server
- //监听的ip和port,client通过此ip和port与服务端通信
- private String ip;
- private int port;
- //netty组件
- private Channel serverChannel = null;
- private ServerBootstrap bootstrap = null;
- //....单例模式实现
- private CanalServerWithNetty(){
- //给embeddedServer赋值
- this.embeddedServer = CanalServerWithEmbedded.instance();
- }
- //... start and stop method
- //...setters and getters...
- }
字段说明:
embeddedServer:因为CanalServerWithNetty需要将请求委派给CanalServerWithEmbeded处理,因此其维护了embeddedServer对象。
ip、port:这是netty监听的网络ip和端口,client通过这个ip和端口与server通信
serverChannel、bootstrap:这是netty的API。其中
ServerBootstrap用于启动服务端,通过调用其bind方法,返回一个类型为Channel的serverChannel对象,代表服务端通道。关于netty知识不是本教程重点,如果读者不熟悉,可以参考笔者的netty教程。
start方法
start方法中包含了netty启动的核心逻辑,如下所示:
com.alibaba.otter.canal.server.netty.CanalServerWithNetty#start
- public void start() {
- super.start();
- //优先启动内嵌的canal server,因为基于netty的实现需要将请求委派给其处理
- if (!embeddedServer.isStart()) {
- embeddedServer.start();
- }
- /* 创建bootstrap实例,参数NioServerSocketChannelFactory也是Netty的API,其接受2个线程池参数
- 其中第一个线程池是Accept线程池,第二个线程池是woker线程池,
- Accept线程池接收到client连接请求后,会将代表client的对象转发给worker线程池处理。
- 这里属于netty的知识,不熟悉的用户暂时不必深究,简单认为netty使用线程来处理客户端的高并发请求即可。*/
- this.bootstrap = new ServerBootstrap(new NioServerSocketChannelFactory(Executors.newCachedThreadPool(),
- Executors.newCachedThreadPool()));
- /*pipeline实际上就是netty对客户端请求的处理器链,
- 可以类比JAVA EE编程中Filter的责任链模式,上一个filter处理完成之后交给下一个filter处理,
- 只不过在netty中,不再是filter,而是ChannelHandler。*/
- bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
- public ChannelPipeline getPipeline() throws Exception {
- ChannelPipeline pipelines = Channels.pipeline();
- //主要是处理编码、解码。因为网路传输的传入的都是二进制流,FixedHeaderFrameDecoder的作用就是对其进行解析
- pipelines.addLast(FixedHeaderFrameDecoder.class.getName(), new FixedHeaderFrameDecoder());
- //处理client与server握手
- pipelines.addLast(HandshakeInitializationHandler.class.getName(), new HandshakeInitializationHandler());
- //client身份验证
- pipelines.addLast(ClientAuthenticationHandler.class.getName(),
- new ClientAuthenticationHandler(embeddedServer));
- //SessionHandler用于真正的处理客户端请求,是本文分析的重点
- SessionHandler sessionHandler = new SessionHandler(embeddedServer);
- pipelines.addLast(SessionHandler.class.getName(), sessionHandler);
- return pipelines;
- }
- });
- // 启动,当bind方法被调用时,netty开始真正的监控某个端口,此时客户端对这个端口的请求可以被接受到
- if (StringUtils.isNotEmpty(ip)) {
- this.serverChannel = bootstrap.bind(new InetSocketAddress(this.ip, this.port));
- } else {
- this.serverChannel = bootstrap.bind(new InetSocketAddress(this.port));
- }
- }
关于stop方法无非是一些关闭操作,代码很简单,这里不做介绍。
SessionHandler
很明显的,canal处理client请求的核心逻辑都在SessionHandler这个处理器中。注意其在实例化时,传入了embeddedServer对象,前面我们提过,CanalServerWithNetty要将请求委派给CanalServerWithEmbedded处理,显然SessionHandler也要维护embeddedServer实例。
这里我们主要分析SessionHandler的 messageReceived方法,这个方法表示接受到了一个客户端请求,我们主要看的是SessionHandler如何对客户端请求进行解析,然后委派给CanalServerWithEmbedded处理的。为了体现其转发请求处理的核心逻辑,以下代码省去了大量源码片段,如下
SessionHandler#messageReceived
- public class SessionHandler extends SimpleChannelHandler {
- ....
- //messageReceived方法表示收到客户端请求
- public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) throws Exception {
- ....
- //根据客户端发送的网路通信包请求类型type,将请求委派embeddedServer处理
- switch (packet.getType()) {
- case SUBSCRIPTION://订阅请求
- ...
- embeddedServer.subscribe(clientIdentity);
- ...
- break;
- case UNSUBSCRIPTION://取消订阅请求
- ...
- embeddedServer.unsubscribe(clientIdentity);
- ...
- break;
- case GET://获取binlog请求
- ....
- if (get.getTimeout() == -1) {// 根据客户端是否指定了请求超时时间调用embeddedServer不同方法获取binlog
- message = embeddedServer.getWithoutAck(clientIdentity, get.getFetchSize());
- } else {
- ...
- message = embeddedServer.getWithoutAck(clientIdentity,
- get.getFetchSize(),
- get.getTimeout(),
- unit);
- }
- ...
- break;
- case CLIENTACK://客户端消费成功ack请求
- ...
- embeddedServer.ack(clientIdentity, ack.getBatchId());
- ...
- break;
- case CLIENTROLLBACK://客户端消费失败回滚请求
- ...
- if (rollback.getBatchId() == 0L) {
- embeddedServer.rollback(clientIdentity);// 回滚所有批次
- } else {
- embeddedServer.rollback(clientIdentity, rollback.getBatchId()); // 只回滚单个批次
- }
- ...
- break;
- default://无法判断请求类型
- NettyUtils.error(400, MessageFormatter.format("packet type={} is NOT supported!", packet.getType())
- .getMessage(), ctx.getChannel(), null);
- break;
- }
- ...
- }
- ...
- }
可以看到,SessionHandler对client请求进行解析后,根据请求类型,委派给CanalServerWithEmbedded的相应方法进行处理。因此核心逻辑都在CanalServerWithEmbedded中。
CannalServerWithEmbeded
CanalServerWithEmbedded实现了CanalServer和CanalServiceCan两个接口。其内部维护了一个Map,key为destination,value为对应的CanalInstance,根据客户端请求携带的destination参数将其转发到对应的CanalInstance上去处理。
- public class CanalServerWithEmbedded extends AbstractCanalLifeCycle implements CanalServer, CanalService {
- ...
- //key为destination,value为对应的CanalInstance。
- private Map<String, CanalInstance> canalInstances;
- ...
- }
对于CanalServer接口中定义的start和stop这两个方法实现比较简单,这里不再赘述。
在上面的SessionHandler源码分析中,我们已经看到,会根据请求报文的类型,会调用CanalServerWithEmbedded的相应方法,这些方法都定义在CanalService接口中,如下:
- public interface CanalService {
- //订阅
- void subscribe(ClientIdentity clientIdentity) throws CanalServerException;
- //取消订阅
- void unsubscribe(ClientIdentity clientIdentity) throws CanalServerException;
- //比例获取数据,并自动自行ack
- Message get(ClientIdentity clientIdentity, int batchSize) throws CanalServerException;
- //超时时间内批量获取数据,并自动进行ack
- Message get(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit) throws CanalServerException;
- //批量获取数据,不进行ack
- Message getWithoutAck(ClientIdentity clientIdentity, int batchSize) throws CanalServerException;
- //超时时间内批量获取数据,不进行ack
- Message getWithoutAck(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit) throws CanalServerException;
- //ack某个批次的数据
- void ack(ClientIdentity clientIdentity, long batchId) throws CanalServerException;
- //回滚所有没有ack的批次的数据
- void rollback(ClientIdentity clientIdentity) throws CanalServerException;
- //回滚某个批次的数据
- void rollback(ClientIdentity clientIdentity, Long batchId) throws CanalServerException;
- }
细心地的读者会发现,每个方法中都包含了一个ClientIdentity类型参数,这就是客户端身份的标识。
- public class ClientIdentity implements Serializable {
- private String destination;
- private short clientId;
- private String filter;
- ...
- }
CanalServerWithEmbedded就是根据ClientIdentity中的destination参数确定这个请求要交给哪个CanalInstance处理的。
下面一次分析每一个方法的作用:
subscribe方法:
subscribe主要用于处理客户端的订阅请求,目前情况下,一个CanalInstance只能由一个客户端订阅,不过可以重复订阅。订阅主要的处理步骤如下:
1、根据客户端要订阅的destination,找到对应的CanalInstance
2、通过这个CanalInstance的CanalMetaManager组件记录下有客户端订阅。
3、获取客户端当前订阅位置(Position)。首先尝试从CanalMetaManager中获取,CanalMetaManager 中记录了某个client当前订阅binlog的位置信息。如果是第一次订阅,肯定无法获取到这个位置,则尝试从CanalEventStore中获取第一个binlog的位置。从CanalEventStore中获取binlog位置信息的逻辑是:CanalInstance一旦启动,就会立刻去拉取binlog,存储到CanalEventStore中,在第一次订阅的情况下,CanalEventStore中的第一条binlog的位置,就是当前客户端当前消费的开始位置。
4、通知CanalInstance订阅关系变化
- /**
- * 客户端订阅,重复订阅时会更新对应的filter信息
- */
- @Override
- public void subscribe(ClientIdentity clientIdentity) throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- //1、根据客户端要订阅的destination,找到对应的CanalInstance
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- if (!canalInstance.getMetaManager().isStart()) {
- canalInstance.getMetaManager().start();
- }
- //2、通过CanalInstance的CanalMetaManager组件进行元数据管理,记录一下当前这个CanalInstance有客户端在订阅
- canalInstance.getMetaManager().subscribe(clientIdentity); // 执行一下meta订阅
- //3、获取客户端当前订阅的binlog位置(Position),首先尝试从CanalMetaManager中获取
- Position position = canalInstance.getMetaManager().getCursor(clientIdentity);
- if (position == null) {
- //3.1 如果是第一次订阅,尝试从CanalEventStore中获取第一个binlog的位置,作为客户端订阅开始的位置。
- position = canalInstance.getEventStore().getFirstPosition();// 获取一下store中的第一条
- if (position != null) {
- canalInstance.getMetaManager().updateCursor(clientIdentity, position); // 更新一下cursor
- }
- logger.info("subscribe successfully, {} with first position:{} ", clientIdentity, position);
- } else {
- logger.info("subscribe successfully, use last cursor position:{} ", clientIdentity, position);
- }
- //4 通知下订阅关系变化
- canalInstance.subscribeChange(clientIdentity);
- }
unsubscribe方法:
unsubscribe方法主要用于取消订阅关系。在下面的代码中,我们可以看到,其实就是找到CanalInstance对应的CanalMetaManager,调用其unsubscribe取消这个订阅记录。需要注意的是,取消订阅并不意味着停止CanalInstance。当某个客户端取消了订阅,还会有新的client来订阅这个CanalInstance,所以不能停。
- /**
- * 取消订阅
- */
- @Override
- public void unsubscribe(ClientIdentity clientIdentity) throws CanalServerException {
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- canalInstance.getMetaManager().unsubscribe(clientIdentity); // 执行一下meta订阅
- logger.info("unsubscribe successfully, {}", clientIdentity);
- }
listAllSubscribe方法:
这一个管理方法,其作用是列出订阅某个destination的所有client。这里返回的是一个List<ClientIdentity>,不过我们已经多次提到,目前一个destination只能由一个client订阅。这里之所以返回一个list,是canal原先计划要支持多个client订阅同一个destination。不过,这个功能一直没有实现。所以List中,实际上只会包含一个ClientIdentity。
- /**
- * 查询所有的订阅信息
- */
- public List<ClientIdentity> listAllSubscribe(String destination) throws CanalServerException {
- CanalInstance canalInstance = canalInstances.get(destination);
- return canalInstance.getMetaManager().listAllSubscribeInfo(destination);
- }
listBatchIds方法:
- /**
- * 查询当前未被ack的batch列表,batchId会按照从小到大进行返回
- */
- public List<Long> listBatchIds(ClientIdentity clientIdentity) throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- checkSubscribe(clientIdentity);
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- Map<Long, PositionRange> batchs = canalInstance.getMetaManager().listAllBatchs(clientIdentity);
- List<Long> result = new ArrayList<Long>(batchs.keySet());
- Collections.sort(result);
- return result;
- }
getWithoutAck方法:
getWithoutAck方法用于客户端获取binlog消息 ,一个获取一批(batch)的binlog,canal会为这批binlog生成一个唯一的batchId。客户端如果消费成功,则调用ack方法对这个批次进行确认。如果失败的话,可以调用rollback方法进行回滚。客户端可以连续多次调用getWithoutAck方法来获取binlog,在ack的时候,需要按照获取到binlog的先后顺序进行ack。如果后面获取的binlog被ack了,那么之前没有ack的binlog消息也会自动被ack。
getWithoutAck方法大致工作步骤如下所示:
根据destination找到要从哪一个CanalInstance中获取binlog消息。
确定从哪一个位置(Position)开始继续消费binlog。通常情况下,这个信息是存储在CanalMetaManager中。特别的,在第一次获取的时候,CanalMetaManager 中还没有存储任何binlog位置信息。此时CanalEventStore中存储的第一条binlog位置,则应该client开始消费的位置。
根据Position从CanalEventStore中获取binlog。为了尽量提高效率,一般一次获取一批binlog,而不是获取一条。这个批次的大小(batchSize)由客户端指定。同时客户端可以指定超时时间,在超时时间内,如果获取到了batchSize的binlog,会立即返回。 如果超时了还没有获取到batchSize指定的binlog个数,也会立即返回。特别的,如果没有设置超时时间,如果没有获取到binlog也立即返回。
在CanalMetaManager中记录这个批次的binlog消息。CanalMetaManager会为获取到的这个批次的binlog生成一个唯一的batchId,batchId是递增的。如果binlog信息为空,则直接把batchId设置为-1。
- @Override
- public Message getWithoutAck(ClientIdentity clientIdentity, int batchSize) throws CanalServerException {
- return getWithoutAck(clientIdentity, batchSize, null, null);
- }
- /**
- * <pre>
- * 几种case:
- * a. 如果timeout为null,则采用tryGet方式,即时获取
- * b. 如果timeout不为null
- * 1. timeout为0,则采用get阻塞方式,获取数据,不设置超时,直到有足够的batchSize数据才返回
- * 2. timeout不为0,则采用get+timeout方式,获取数据,超时还没有batchSize足够的数据,有多少返回多少
- * </pre>
- */
- @Override
- public Message getWithoutAck(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit)
- throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- checkSubscribe(clientIdentity);
- // 1、根据destination找到要从哪一个CanalInstance中获取binlog消息
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- synchronized (canalInstance) {
- //2、从CanalMetaManager中获取最后一个没有ack的binlog批次的位置信息。
- PositionRange<LogPosition> positionRanges = canalInstance.getMetaManager().getLastestBatch(clientIdentity);
- //3 从CanalEventStore中获取binlog
- Events<Event> events = null;
- if (positionRanges != null) { // 3.1 如果从CanalMetaManager获取到了位置信息,从当前位置继续获取binlog
- events = getEvents(canalInstance.getEventStore(), positionRanges.getStart(), batchSize, timeout, unit);
- } else { //3.2 如果没有获取到binlog位置信息,从当前store中的第一条开始获取
- Position start = canalInstance.getMetaManager().getCursor(clientIdentity);
- if (start == null) { // 第一次,还没有过ack记录,则获取当前store中的第一条
- start = canalInstance.getEventStore().getFirstPosition();
- }
- // 从CanalEventStore中获取binlog消息
- events = getEvents(canalInstance.getEventStore(), start, batchSize, timeout, unit);
- }
- //4 记录批次信息到CanalMetaManager中
- if (CollectionUtils.isEmpty(events.getEvents())) {
- //4.1 如果获取到的binlog消息为空,构造一个空的Message对象,将batchId设置为-1返回给客户端
- logger.debug("getWithoutAck successfully, clientId:{} batchSize:{} but result is null", new Object[] {
- clientIdentity.getClientId(), batchSize });
- return new Message(-1, new ArrayList<Entry>()); // 返回空包,避免生成batchId,浪费性能
- } else {
- //4.2 如果获取到了binlog消息,将这个批次的binlog消息记录到CanalMetaMaager中,并生成一个唯一的batchId
- Long batchId = canalInstance.getMetaManager().addBatch(clientIdentity, events.getPositionRange());
- //将Events转为Entry
- List<Entry> entrys = Lists.transform(events.getEvents(), new Function<Event, Entry>() {
- public Entry apply(Event input) {
- return input.getEntry();
- }
- });
- logger.info("getWithoutAck successfully, clientId:{} batchSize:{} real size is {} and result is [batchId:{} , position:{}]",
- clientIdentity.getClientId(),
- batchSize,
- entrys.size(),
- batchId,
- events.getPositionRange());
- //构造Message返回
- return new Message(batchId, entrys);
- }
- }
- }
- /**
- * 根据不同的参数,选择不同的方式获取数据
- */
- private Events<Event> getEvents(CanalEventStore eventStore, Position start, int batchSize, Long timeout,
- TimeUnit unit) {
- if (timeout == null) {
- return eventStore.tryGet(start, batchSize);
- } else {
- try {
- if (timeout <= 0) {
- return eventStore.get(start, batchSize);
- } else {
- return eventStore.get(start, batchSize, timeout, unit);
- }
- } catch (Exception e) {
- throw new CanalServerException(e);
- }
- }
- }
ack方法:
ack方法时客户端用户确认某个批次的binlog消费成功。进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。注意:进行反馈时必须按照batchId的顺序进行ack(需有客户端保证)
ack时需要做以下几件事情:
从CanalMetaManager中,移除这个批次的信息。在getWithoutAck方法中,将批次的信息记录到了CanalMetaManager中,ack时移除。
记录已经成功消费到的binlog位置,以便下一次获取的时候可以从这个位置开始,这是通过CanalMetaManager记录的。
从CanalEventStore中,将这个批次的binlog内容移除。因为已经消费成功,继续保存这些已经消费过的binlog没有任何意义,只会白白占用内存。
- @Override
- public void ack(ClientIdentity clientIdentity, long batchId) throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- checkSubscribe(clientIdentity);
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- PositionRange<LogPosition> positionRanges = null;
- //1 从CanalMetaManager中,移除这个批次的信息
- positionRanges = canalInstance.getMetaManager().removeBatch(clientIdentity, batchId); // 更新位置
- if (positionRanges == null) { // 说明是重复的ack/rollback
- throw new CanalServerException(String.format("ack error , clientId:%s batchId:%d is not exist , please check",
- clientIdentity.getClientId(),
- batchId));
- }
- //2、记录已经成功消费到的binlog位置,以便下一次获取的时候可以从这个位置开始,这是通过CanalMetaManager记录的
- if (positionRanges.getAck() != null) {
- canalInstance.getMetaManager().updateCursor(clientIdentity, positionRanges.getAck());
- logger.info("ack successfully, clientId:{} batchId:{} position:{}",
- clientIdentity.getClientId(),
- batchId,
- positionRanges);
- }
- //3、从CanalEventStore中,将这个批次的binlog内容移除
- canalInstance.getEventStore().ack(positionRanges.getEnd());
- }
rollback方法:
- /**
- * 回滚到未进行 {@link #ack} 的地方,下次fetch的时候,可以从最后一个没有 {@link #ack} 的地方开始拿
- */
- @Override
- public void rollback(ClientIdentity clientIdentity) throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- // 因为存在第一次链接时自动rollback的情况,所以需要忽略未订阅
- boolean hasSubscribe = canalInstance.getMetaManager().hasSubscribe(clientIdentity);
- if (!hasSubscribe) {
- return;
- }
- synchronized (canalInstance) {
- // 清除batch信息
- canalInstance.getMetaManager().clearAllBatchs(clientIdentity);
- // rollback eventStore中的状态信息
- canalInstance.getEventStore().rollback();
- logger.info("rollback successfully, clientId:{}", new Object[] { clientIdentity.getClientId() });
- }
- }
- /**
- * 回滚到未进行 {@link #ack} 的地方,下次fetch的时候,可以从最后一个没有 {@link #ack} 的地方开始拿
- */
- @Override
- public void rollback(ClientIdentity clientIdentity, Long batchId) throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- // 因为存在第一次链接时自动rollback的情况,所以需要忽略未订阅
- boolean hasSubscribe = canalInstance.getMetaManager().hasSubscribe(clientIdentity);
- if (!hasSubscribe) {
- return;
- }
- synchronized (canalInstance) {
- // 清除batch信息
- PositionRange<LogPosition> positionRanges = canalInstance.getMetaManager().removeBatch(clientIdentity,
- batchId);
- if (positionRanges == null) { // 说明是重复的ack/rollback
- throw new CanalServerException(String.format("rollback error, clientId:%s batchId:%d is not exist , please check",
- clientIdentity.getClientId(),
- batchId));
- }
- // lastRollbackPostions.put(clientIdentity,
- // positionRanges.getEnd());// 记录一下最后rollback的位置
- // TODO 后续rollback到指定的batchId位置
- canalInstance.getEventStore().rollback();// rollback
- // eventStore中的状态信息
- logger.info("rollback successfully, clientId:{} batchId:{} position:{}",
- clientIdentity.getClientId(),
- batchId,
- positionRanges);
- }
- }
get方法:
与getWithoutAck主要流程完全相同,唯一不同的是,在返回数据给用户前,直接进行了ack,而不管客户端消费是否成功。
- @Override
- public Message get(ClientIdentity clientIdentity, int batchSize) throws CanalServerException {
- return get(clientIdentity, batchSize, null, null);
- }
- /*
- * 几种case:
- * a. 如果timeout为null,则采用tryGet方式,即时获取
- * b. 如果timeout不为null
- * 1. timeout为0,则采用get阻塞方式,获取数据,不设置超时,直到有足够的batchSize数据才返回
- * 2. timeout不为0,则采用get+timeout方式,获取数据,超时还没有batchSize足够的数据,有多少返回多少
- */
- @Override
- public Message get(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit)
- throws CanalServerException {
- checkStart(clientIdentity.getDestination());
- checkSubscribe(clientIdentity);
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- synchronized (canalInstance) {
- // 获取到流式数据中的最后一批获取的位置
- PositionRange<LogPosition> positionRanges = canalInstance.getMetaManager().getLastestBatch(clientIdentity);
- if (positionRanges != null) {
- throw new CanalServerException(String.format("clientId:%s has last batch:[%s] isn't ack , maybe loss data",
- clientIdentity.getClientId(),
- positionRanges));
- }
- Events<Event> events = null;
- Position start = canalInstance.getMetaManager().getCursor(clientIdentity);
- events = getEvents(canalInstance.getEventStore(), start, batchSize, timeout, unit);
- if (CollectionUtils.isEmpty(events.getEvents())) {
- logger.debug("get successfully, clientId:{} batchSize:{} but result is null", new Object[] {
- clientIdentity.getClientId(), batchSize });
- return new Message(-1, new ArrayList<Entry>()); // 返回空包,避免生成batchId,浪费性能
- } else {
- // 记录到流式信息
- Long batchId = canalInstance.getMetaManager().addBatch(clientIdentity, events.getPositionRange());
- List<Entry> entrys = Lists.transform(events.getEvents(), new Function<Event, Entry>() {
- public Entry apply(Event input) {
- return input.getEntry();
- }
- });
- logger.info("get successfully, clientId:{} batchSize:{} real size is {} and result is [batchId:{} , position:{}]",
- clientIdentity.getClientId(),
- batchSize,
- entrys.size(),
- batchId,
- events.getPositionRange());
- // 直接提交ack
- ack(clientIdentity, batchId);
- return new Message(batchId, entrys);
- }
- }
- }
4.0 instance模块
在上一节server模块源码分析中,我们提到CanalServerWithNetty封装了一层网络请求协议,将请求委派给CanalServerWithEmbedded处理。CanalServerWithEmbedded会根据请求携带的destination参数,选择对应的CanalInstance来真正的处理请求。这正是一步一步抽丝剥茧的过程,在本节中,我们将要分析CanalInstance的源码。
1 CanalInstance源码概览
CanalInstance相关代码位于canal源码的instance模块中,这个模块又有三个子模块,如下所示:

在core模块中,定义了CanalInstance接口,以及其抽象类子类AbstractCanalInstance。
在spring模块,提供了基于spring配置方式的CanalInstanceWithSpring实现,即CanalInstance实例的创建,通过spring配置文件来创建。
在manager模块中,提供了基于manager配置方式的CanalInstanceWithManager实现,即CanalInstance实例根据远程配置中心的内容来创建。
CanalInstance类图继承关系如下所示:
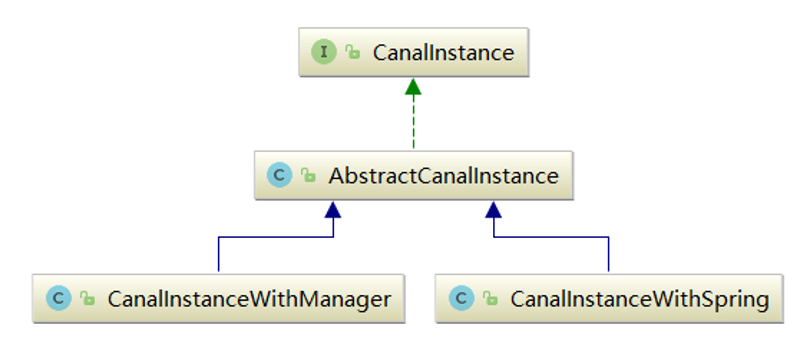
在本节中,我们主要以spring配置方式为例,对CanalInstance源码进行解析。
2 CanalInstance接口
在Canal官方文档中有一张图描述了CanalInstance的4个主要组件,如下:
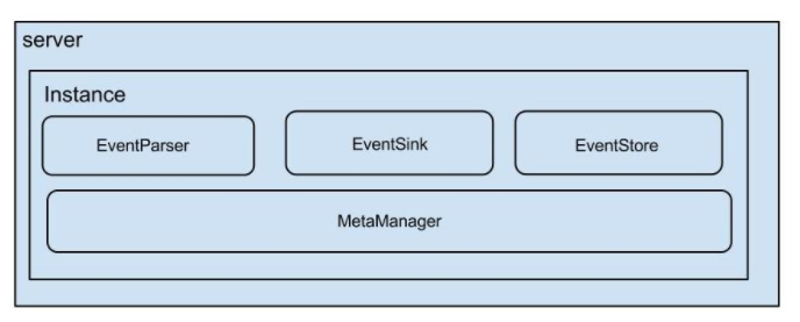
其中:
event parser:数据源接入,模拟slave协议和master进行交互,协议解析
event sink:parser和store链接器,进行数据过滤,加工,分发的工作
event store:数据存储
meta manager:增量订阅/消费binlog元数据位置存储
在CanalInstance接口中,主要就是定义了获得这几个组成部分的方法:
- public interface CanalInstance extends CanalLifeCycle {
- //这个instance对应的destination
- String getDestination();
- //数据源接入,模拟slave协议和master进行交互,协议解析,位于canal.parse模块中
- CanalEventParser getEventParser();
- //parser和store链接器,进行数据过滤,加工,分发的工作,位于canal.sink模块中
- CanalEventSink getEventSink();
- //数据存储,位于canal.store模块中
- CanalEventStore getEventStore();
- //增量订阅&消费元数据管理器,位于canal.meta模块中
- CanalMetaManager getMetaManager();
- //告警,位于canal.common块中
- CanalAlarmHandler getAlarmHandler();
- /** * 客户端发生订阅/取消订阅行为 */
- boolean subscribeChange(ClientIdentity identity);
- }
可以看到,instance模块其实是把这几个模块组装在一起,为客户端的binlog订阅请求提供服务。有些模块都有多种实现,不同组合方式,最终确定了一个CanalInstance的工作逻辑。
CanalEventParser接口实现类:
MysqlEventParser:伪装成单个mysql实例的slave解析binglog日志
GroupEventParser:伪装成多个mysql实例的slave解析binglog日志。内部维护了多个CanalEventParser。主要应用场景是分库分表:比如产品数据拆分了4个库,位于不同的mysql实例上。正常情况下,我们需要配置四个CanalInstance。对应的,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。为了方便业务使用,此时我们可以让CanalInstance引用一个GroupEventParser,由GroupEventParser内部维护4个MysqlEventParser去4个不同的mysql实例去拉取binlog,最终合并到一起。此时业务只需要启动1个客户端,链接这个CanalInstance即可.
LocalBinlogEventParser:解析本地的mysql binlog。例如将mysql的binlog文件拷贝到canal的机器上进行解析。
CanalEventSink接口实现类:
EntryEventSink
GroupEventSink:基于归并排序的sink处理
CanalEventStore接口实现类:
目前只有MemoryEventStoreWithBuffer,基于内存buffer构建内存memory store
CanalMetaManager:
ZooKeeperMetaManager:将元数据存存储到zk中
MemoryMetaManager:将元数据存储到内存中
MixedMetaManager:组合memory + zookeeper的使用模式
PeriodMixedMetaManager:基于定时刷新的策略的mixed实现
FileMixedMetaManager:先写内存,然后定时刷新数据到File
关于这些实现的具体细节,我们在相应模块的源码分析时,进行讲解。目前只需要知道,一些组件有多种实现,因此组合工作方式有多种。
3 AbstractCanalInstance源码分析
AbstractCanalInstance是CanalInstance的抽象子类,定义了相关字段来维护eventParser、eventSink、eventStore、metaManager的引用。
- public class AbstractCanalInstance extends AbstractCanalLifeCycle implements CanalInstance {
- private static final Logger logger = LoggerFactory.getLogger(AbstractCanalInstance.class);
- protected Long canalId; // 和manager交互唯一标示
- protected String destination; // 队列名字
- protected CanalEventStore<Event> eventStore; // 有序队列
- protected CanalEventParser eventParser; // 解析对应的数据信息
- protected CanalEventSink<List<CanalEntry.Entry>> eventSink; // 链接parse和store的桥接器
- protected CanalMetaManager metaManager; // 消费信息管理器
- protected CanalAlarmHandler alarmHandler; // alarm报警机制
- //...
- }
需要注意的是,在AbstractCanalInstance中,并没有提供方法来初始化这些字段。可以看到,这些字段都是protected的,子类可以直接访问,显然这些字段都是在AbstractCanalInstance的子类中进行赋值的。
AbstractCanalInstance不关心这些字段的具体实现,只是从接口层面进行调用。对于其子类而言,只需要给相应的字段赋值即可。在稍后我们将要讲解的CanalInstanceWithSpring中,你将会发现其仅仅给eventParser、eventSink、eventStore、metaManager几个字段赋值,其他什么工作都没干。
因此,对于instance模块而言,其核心工作逻辑都是在AbstractCanalInstance中实现的。
3.1 start方法和stop方法:
start方法:
在AbstractCanalInstance的start方法中,主要就是启动各个模块。启动顺序为:metaManager—>eventStore—>eventSink—>eventParser。
源码如下所示:
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#start
- public void start() {
- super.start();
- if (!metaManager.isStart()) {
- metaManager.start();
- }
- if (!alarmHandler.isStart()) {
- alarmHandler.start();
- }
- if (!eventStore.isStart()) {
- eventStore.start();
- }
- if (!eventSink.isStart()) {
- eventSink.start();
- }
- if (!eventParser.isStart()) {
- beforeStartEventParser(eventParser);//启动前执行一些操作
- eventParser.start();
- afterStartEventParser(eventParser);//启动后执行一些操作
- }
- logger.info("start successful....");
- }
要理解为什么按照这个顺序启动很简单。官方关于instance模块构成的图中,把metaManager放在最下面,说明其是最基础的部分,因此应该最先启动。
而eventParser依赖于eventSink,需要把自己解析的binlog交给其加工过滤,而eventSink又要把处理后的数据交给eventStore进行存储。因此依赖关系如下:eventStore—>eventSink—>eventParser ,启动的时候也要按照这个顺序启动。
stop方法:
在停止的时候,实际上就是停止内部的各个模块,模块停止的顺序与start方法刚好相反
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#stop
- @Override
- public void stop() {
- super.stop();
- logger.info("stop CannalInstance for {}-{} ", new Object[] { canalId, destination });
- if (eventParser.isStart()) {
- beforeStopEventParser(eventParser);//停止前执行一些操作
- eventParser.stop();
- afterStopEventParser(eventParser);//停止后执行一些操作
- }
- if (eventSink.isStart()) {
- eventSink.stop();
- }
- if (eventStore.isStart()) {
- eventStore.stop();
- }
- if (metaManager.isStart()) {
- metaManager.stop();
- }
- if (alarmHandler.isStart()) {
- alarmHandler.stop();
- }
- logger.info("stop successful....");
- }
3.2 start和stop方法对eventParser的特殊处理
在AbstractCanalInstance的start和stop方法,对于eventParser这个组件的启动和停止,都有一些特殊处理,以下是相关代码片段:
- --start方法
- beforeStartEventParser(eventParser);//启动前执行一些操作
- eventParser.start();
- afterStartEventParser(eventParser);//启动后执行一些操作
- --stop方法
- beforeStopEventParser(eventParser);//停止前执行一些操作
- eventParser.stop();
- afterStopEventParser(eventParser);//停止后执行一些操作
这与eventParser的自身构成有关系。canal官方文档DevGuide中,关于eventParser有以下描述:
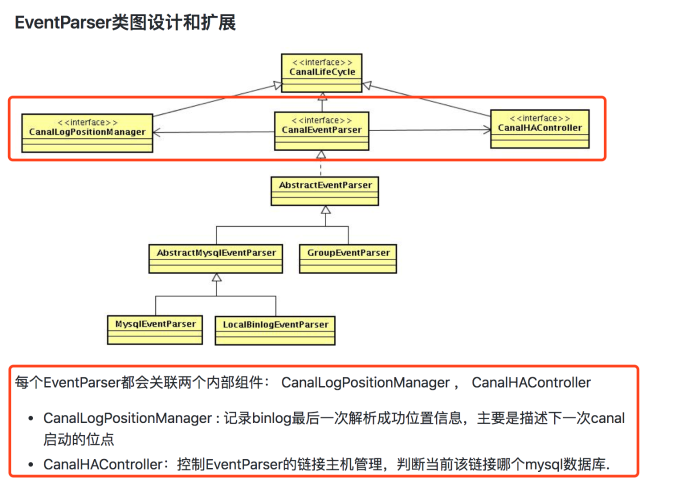
因此,eventParser在启动之前,需要先启动CanalLogPositionManager和CanalHAController。
关于CanalLogPositionManager,做一点补充说明。
mysql在主从同步过程中,要求slave自己维护binlog的消费进度信息。canal伪装成slave,因此也要维护这样的信息。
事实上,如果读者自己搭建过mysql主从复制的话,在slave机器的data目录下,都会有一个master.info文件,这个文件的作用就是存储主库的消费binlog解析进度信息。
beforeStartEventParser方法
beforeStartEventParser方法的作用是eventParser前做的一些特殊处理。首先会判断eventParser的类型是否是GroupEventParser,在前面我已经介绍过,这是为了处理分库分表的情况。如果是,循环其包含的所有CanalEventParser,依次调用startEventParserInternal方法;否则直接调用com.alibaba.otter.canal.instance.core.AbstractCanalInstance#beforeStartEventParser
- protected void beforeStartEventParser(CanalEventParser eventParser) {
- //1、判断eventParser的类型是否是GroupEventParser
- boolean isGroup = (eventParser instanceof GroupEventParser);
- //2、如果是GroupEventParser,则循环启动其内部包含的每一个CanalEventParser,依次调用startEventParserInternal方法
- if (isGroup) {
- // 处理group的模式
- List<CanalEventParser> eventParsers = ((GroupEventParser) eventParser).getEventParsers();
- for (CanalEventParser singleEventParser : eventParsers) {// 需要遍历启动
- startEventParserInternal(singleEventParser, true);
- }
- //如果不是,说明是一个普通的CanalEventParser,直接调用startEventParserInternal方法
- } else {
- startEventParserInternal(eventParser, false);
- }
- }
从上面的分析中,可以看出,针对单个CanalEventParser,都是通过调用startEventParserInternal来启动的,其内部会启动CanalLogPositionManager和CanalHAController。
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#startEventParserInternal
- /**
- * 初始化单个eventParser,不需要考虑group
- */
- protected void startEventParserInternal(CanalEventParser eventParser, boolean isGroup) {
- // 1 、启动CanalLogPositionManager
- if (eventParser instanceof AbstractEventParser) {
- AbstractEventParser abstractEventParser = (AbstractEventParser) eventParser;
- CanalLogPositionManager logPositionManager = abstractEventParser.getLogPositionManager();
- if (!logPositionManager.isStart()) {
- logPositionManager.start();
- }
- }
- // 2 、启动CanalHAController
- if (eventParser instanceof MysqlEventParser) {
- MysqlEventParser mysqlEventParser = (MysqlEventParser) eventParser;
- CanalHAController haController = mysqlEventParser.getHaController();
- if (haController instanceof HeartBeatHAController) {
- ((HeartBeatHAController) haController).setCanalHASwitchable(mysqlEventParser);
- }
- if (!haController.isStart()) {
- haController.start();
- }
- }
- }
关于CanalLogPositionManager和CanalHAController的详细源码,我们将会在分析parser模块的时候进行介绍
afterStartEventParser方法
在eventParser启动后,会调用afterStartEventParser方法。这个方法内部主要是通过metaManager读取一下历史订阅过这个CanalInstance的客户端信息,然后更新一下filter。
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#afterStartEventParser
- protected void afterStartEventParser(CanalEventParser eventParser) {
- // 读取一下历史订阅的client信息
- List<ClientIdentity> clientIdentitys = metaManager.listAllSubscribeInfo(destination);
- for (ClientIdentity clientIdentity : clientIdentitys) {
- //更新filter
- subscribeChange(clientIdentity);
- }
- }
subscribeChange 方法
subscribeChange方法,主要是更新一下eventParser中的filter。
- @Override
- public boolean subscribeChange(ClientIdentity identity) {
- if (StringUtils.isNotEmpty(identity.getFilter())) {//如果设置了filter
- logger.info("subscribe filter change to " + identity.getFilter());
- AviaterRegexFilter aviaterFilter = new AviaterRegexFilter(identity.getFilter());
- boolean isGroup = (eventParser instanceof GroupEventParser);
- if (isGroup) {
- // 处理group的模式
- List<CanalEventParser> eventParsers = ((GroupEventParser) eventParser).getEventParsers();
- for (CanalEventParser singleEventParser : eventParsers) {// 需要遍历启动
- ((AbstractEventParser) singleEventParser).setEventFilter(aviaterFilter);
- }
- } else {
- ((AbstractEventParser) eventParser).setEventFilter(aviaterFilter);
- }
- }
- // filter的处理规则
- // a. parser处理数据过滤处理
- // b. sink处理数据的路由&分发,一份parse数据经过sink后可以分发为多份,每份的数据可以根据自己的过滤规则不同而有不同的数据
- // 后续内存版的一对多分发,可以考虑
- return true;
- }
关于filter,进行一下补充说明,filter规定了需要订阅哪些库,哪些表。在服务端和客户端都可以设置,客户端的配置会覆盖服务端的配置。
服务端配置:主要是配置instance.properties中的canal.instance.filter.regex配置项,官网文档关于这个配置项有以下介绍

客户端配置
客户端在订阅时,调用CanalConnector接口中定义的带有filter参数的subscribe方法重载形式
- /**
- * 客户端订阅,重复订阅时会更新对应的filter信息
- *
- * <pre>
- * 说明:
- * a. 如果本次订阅中filter信息为空,则直接使用canal server服务端配置的filter信息
- * b. 如果本次订阅中filter信息不为空,目前会直接替换canal server服务端配置的filter信息,以本次提交的为准
- * </pre>
- */
- void subscribe(String filter) throws CanalClientException;
至此,针对start eventParser前后的特殊处理步骤的两个方法:beforeStartEventParser和afterStartEventParser我们已经分析完成。
对于stop eventParser前后做的特殊处理涉及的beforeStopEventParser和afterStopEventParser方法,这里不再赘述。
3.3 AbstractCanalInstance总结
AbstractCanalInstance源码到目前我们已经分析完成,无非就是在start和stop时,按照一定的顺序启动或停止event store、event sink、event parser、meta manager这几个组件,期间对于event parser的启动和停止做了特殊处理,并没有提供订阅binlog的相关方法。那么如何来订阅binglog数据呢?答案是直接操作器内部组件。
AbstractCanalInstance通过相关get方法直接返回了其内部的组件:
- @Override
- public CanalEventParser getEventParser() {return eventParser;}
- @Override
- public CanalEventSink getEventSink() {return eventSink;}
- @Override
- public CanalEventStore getEventStore() {return eventStore;}
- @Override
- public CanalMetaManager getMetaManager() {return metaManager;}
在上一节server模块源码分析中,CanalServerWithEmbedded就是直接通过CanalInstance的内部组件,进行操作的。我们再次回顾一下getWithoutAck方法,进行验证:
com.alibaba.otter.canal.server.embedded.CanalServerWithEmbedded#getWithoutAck
- public Message getWithoutAck(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit)
- throws CanalServerException
- {
- checkStart(clientIdentity.getDestination());
- checkSubscribe(clientIdentity);
- CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination());
- synchronized (canalInstance) {
- //通过canalInstance.getMetaManager() 获取到流式数据中的最后一批获取的位置
- PositionRange<LogPosition> positionRanges = canalInstance.getMetaManager().getLastestBatch(clientIdentity);
- Events<Event> events = null;
- if (positionRanges != null) {
- //通过canalInstance.getEventStore()获得binlog事件
- events = getEvents(canalInstance.getEventStore(), positionRanges.getStart(), batchSize, timeout, unit);
- } else {// ack后第一次获取,通过canalInstance.getMetaManager()获得开始位置
- Position start = canalInstance.getMetaManager().getCursor(clientIdentity);
- if (start == null) { // 第一次,还没有过ack记录,通过canalInstance.getEventStore()当前store中的第一条
- start = canalInstance.getEventStore().getFirstPosition();
- }
- //通过canalInstance.getEventStore()获得binlog事件
- events = getEvents(canalInstance.getEventStore(), start, batchSize, timeout, unit);
- }
- if (CollectionUtils.isEmpty(events.getEvents())) {
- logger.debug("getWithoutAck successfully, clientId:{} batchSize:{} but result is null", new Object[] {
- clientIdentity.getClientId(), batchSize });
- return new Message(-1, new ArrayList<Entry>()); // 返回空包,避免生成batchId,浪费性能
- } else {
- // 通过canalInstance.getMetaManager()记录流式信息
- Long batchId = canalInstance.getMetaManager().addBatch(clientIdentity, events.getPositionRange());
- List<Entry> entrys = Lists.transform(events.getEvents(), new Function<Event, Entry>() {
- public Entry apply(Event input) {
- return input.getEntry();
- }
- });
- ...
- return new Message(batchId, entrys);
- }
- }
- }
可以看到AbstractCanalInstance除了负责启动和停止其内部组件,就没有其他工作了。真正获取binlog信息,以及相关元数据维护的逻辑,都是在CanalServerWithEmbedded中完成的。
事实上,从设计的角度来说,笔者认为既然这些模块是CanalInstance的内部组件,那么相关操作也应该封装在CanalInstance的实现类中,对外部屏蔽,不应该把这些逻辑放到CanalServerWithEmbedded中实现。
最后,AbstractCanalInstance中并没有metaManager、eventSink、eventPaser,eventStore这几个组件。这几个组件的实例化是在AbstractCanalInstance的子类中实现的。AbstractCanalInstance有2个子类:CanalInstanceWithSpring和CanalInstanceWithManager。我们将以CanalInstanceWithSpring为例进行说明如何给这几个组件赋值。
4 CanalInstanceWithSpring
CanalInstanceWithSpring是AbstractCanalInstance的子类,提供了一些set方法为instance的组成模块赋值,如下所示:
- public class CanalInstanceWithSpring extends AbstractCanalInstance {
- private static final Logger logger = LoggerFactory.getLogger(CanalInstanceWithSpring.class);
- public void start() {
- logger.info("start CannalInstance for {}-{} ", new Object[] { 1, destination });
- super.start();
- }
- // ======== setter ========
- public void setDestination(String destination) {
- this.destination = destination;
- }
- public void setEventParser(CanalEventParser eventParser) {
- this.eventParser = eventParser;
- }
- public void setEventSink(CanalEventSink<List<CanalEntry.Entry>> eventSink) {
- this.eventSink = eventSink;
- }
- public void setEventStore(CanalEventStore<Event> eventStore) {
- this.eventStore = eventStore;
- }
- public void setMetaManager(CanalMetaManager metaManager) {
- this.metaManager = metaManager;
- }
- public void setAlarmHandler(CanalAlarmHandler alarmHandler) {
- this.alarmHandler = alarmHandler;
- }
- }
当我们配置加载方式为spring时,创建的CanalInstance实例类型都是CanalInstanceWithSpring。canal将会寻找本地的spring配置文件来创建instance实例。canal默认提供了一下几种spring配置文件:
spring/memory-instance.xml
spring/file-instance.xml
spring/default-instance.xml
spring/group-instance.xml
在这4个配置文件中,我们无一例外的都可以看到以下bean配置:
- <!--注意class属性都是CanalInstanceWithSpring-->
- <bean id="instance" class="com.alibaba.otter.canal.instance.spring.CanalInstanceWithSpring">
- <property name="destination" value="${canal.instance.destination}" />
- <property name="eventParser">
- <ref local="eventParser" />
- </property>
- <property name="eventSink">
- <ref local="eventSink" />
- </property>
- <property name="eventStore">
- <ref local="eventStore" />
- </property>
- <property name="metaManager">
- <ref local="metaManager" />
- </property>
- <property name="alarmHandler">
- <ref local="alarmHandler" />
- </property>
- </bean>
这四个配置文件创建的bean实例都是CanalInstanceWithSpring,但是工作方式却是不同的,因为在不同的配置文件中,eventParser、eventSink、eventStore、metaManager这几个属性引用的具体实现不同。
memory-instance.xml
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
- <bean id="metaManager" class="com.alibaba.otter.canal.meta.MemoryMetaManager" />
- <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer">
- ...
- </bean>
- <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink">
- <property name="eventStore" ref="eventStore" />
- </bean>
- <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”>
- ...
- </bean>
file-instance.xml
所有的组件(parser , sink , store)都选择了基于file持久化模式,注意,不支持HA机制.
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
- <bean id="metaManager" class="com.alibaba.otter.canal.meta.FileMixedMetaManager">
- <property name="dataDir" value="${canal.file.data.dir:../conf}" />
- <property name="period" value="${canal.file.flush.period:1000}" />
- </bean>
- <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer">
- ...
- </bean>
- <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink">
- <property name="eventStore" ref="eventStore" />
- </bean>
- <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”>
- ...
- </bean>
在这里,有一点需要注意,目前开源版本的eventStore只有基于内存模式的实现,因此官方文档上说store也是基于file持久化的描述是错误的。
default-instance.xml:
所有的组件(parser , sink , store)都选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA
场景:生产环境,集群化部署.
- <!--注意,由于default-instance.xml支持同ZK来进行HA保障,所以多了此项配置-->
- <bean id="zkClientx" class="org.springframework.beans.factory.config.MethodInvokingFactoryBean" >
- <property name="targetClass" value="com.alibaba.otter.canal.common.zookeeper.ZkClientx" />
- <property name="targetMethod" value="getZkClient" />
- <property name="arguments">
- <list>
- <value>${canal.zkServers:127.0.0.1:2181}</value>
- </list>
- </property>
- </bean>
- <bean id="metaManager" class="com.alibaba.otter.canal.meta.PeriodMixedMetaManager">
- <property name="zooKeeperMetaManager">
- <bean class="com.alibaba.otter.canal.meta.ZooKeeperMetaManager">
- <property name="zkClientx" ref="zkClientx" />
- </bean>
- </property>
- <property name="period" value="${canal.zookeeper.flush.period:1000}" />
- </bean>
- <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer">
- ...
- </bean>
- <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink">
- <property name="eventStore" ref="eventStore" />
- </bean>
- <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”>
- ...
- </bean>
group-instance.xml:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
- <bean id="metaManager" class="com.alibaba.otter.canal.meta.MemoryMetaManager" />
- <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer">
- ...
- </bean>
- <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink">
- <property name="eventStore" ref="eventStore" />
- </bean>
- <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.group.GroupEventParser">
- <property name="eventParsers">
- <list>
- <ref bean="eventParser1" />
- <ref bean="eventParser2" />
- </list>
- </property>
- </bean>
细心的读者会发现,这几个不同的spring配置文件中,最主要的就是metaManager 和eventParser 这两个配置有所不同,eventStore 、和eventSink 定义都是相同的。这是因为:
eventStore:目前的开源版本中eventStore只有一种基于内存的实现,所以配置都相同
eventSink:其作用是eventParser和eventStore的链接器,进行数据过滤,加工,分发的工作。不涉及存储,也就没有必要针对内存、file、或者zk进行区分。
最后,上面只是列出了这几个模块spring配置文件不同定义,特别的针对metaManager和eventParser具体属性配置都没有介绍,我们将会在相应模块的源码分析中进行讲解。
canal源码分析简介-2的更多相关文章
- 【Canal源码分析】Canal Instance启动和停止
一.序列图 1.1 启动 1.2 停止 二.源码分析 2.1 启动 这部分代码其实在ServerRunningMonitor的start()方法中.针对不同的destination,启动不同的Cana ...
- 【Canal源码分析】Canal Server的启动和停止过程
本文主要解析下canal server的启动过程,希望能有所收获. 一.序列图 1.1 启动 1.2 停止 二.源码分析 整个server启动的过程比较复杂,看图难以理解,需要辅以文字说明. 首先程序 ...
- 「从零单排canal 03」 canal源码分析大纲
在前面两篇中,我们从基本概念理解了canal是一个什么项目,能应用于什么场景,然后通过一个demo体验,有了基本的体感和认识. 从这一篇开始,我们将从源码入手,深入学习canal的实现方式.了解can ...
- 【Canal源码分析】parser工作过程
本文主要分析的部分是instance启动时,parser的一个启动和工作过程.主要关注的是AbstractEventParser的start()方法中的parseThread. 一.序列图 二.源码分 ...
- 【Canal源码分析】Sink及Store工作过程
一.序列图 二.源码分析 2.1 Sink Sink阶段所做的事情,就是根据一定的规则,对binlog数据进行一定的过滤.我们之前跟踪过parser过程的代码,发现在parser完成后,会把数据放到一 ...
- 使用canal分析binlog(二) canal源码分析
在能够跑通example后有几个疑问 1. canal的server端对于已经读取的binlog,client已经ack的position,是否持久化,保存在哪里 2. 即使不启动zookeeper, ...
- 【Canal源码分析】重要类图
从Canal的整体架构中,我们可以看出,在Canal中,比较重要的一些领域有Parser.Sink.Store.MetaManager.CanalServer.CanalInstance.CanalC ...
- 【Canal源码分析】TableMetaTSDB
这是Canal在新版本引入的一个内容,主要是为了解决由于历史的DDL导致表结构与现有表结构不一致,导致的同步失败的问题.采用的是Druid和Fastsql,来记录表结构到DB中,如果需要进行回滚时,得 ...
- 【Canal源码分析】整体架构
本文详解canal的整体架构. 一.整体架构 说明: server代表一个canal运行实例,对应于一个jvm instance对应于一个数据队列 (1个server对应1..n个instance) ...
- 【Canal源码分析】配置项
本文讲解canal中的一些配置含义. 一.配置加载图 二.配置文件canal.properties 2.1 common参数定义 比如可以将instance.properties的公用参数,抽取放置到 ...
随机推荐
- 13.Kubernetes核心技术Ingress
Kubernetes核心技术Ingress 前言 原来我们需要将端口号对外暴露,通过 ip + 端口号就可以进行访问 原来是使用Service中的NodePort来实现 在每个节点上都会启动端口 在访 ...
- delphi Image32 图像采样
图像数据采样 代码: 1 unit uFrmImageResampling; 2 3 interface 4 5 uses 6 Winapi.Windows, Winapi.Messages, Win ...
- 【一步步开发AI运动小程序】二十一、如果将AI运动项目配置持久化到后端?
说明:本文所涉及的AI运动识别.计时.计数能力,都是基于云智「Ai运动识别引擎」实现.云智「Ai运动识别」插件识别引擎,可以为您的小程序或Uni APP赋于原生.本地.广覆盖.高性能的人体识别.姿态识 ...
- YIi2 Object 报错问题
yii2的老版本会有在PHP7运行的错误提示 Cannot use yii\base\Object as Object because 'Object' is a special class name ...
- git cherry-pick 同事代码commit后 如何修改为自己的author
如果有个功能是同事在做,但是做到一半,需要接手帮忙修改或者完成后续,可以切入他的分支 git checkout 分支名称 直接开发,也可以 git checkout -b 新分支名称 这样就完全拥有他 ...
- viper读取配置文件
//方法一 func readConfig1(path, filename, filetype string) interface{} { viper.AddConfigPath(path) vipe ...
- 读书笔记-C#8.0本质论-06
18.4 并行迭代 如果一个对CPU资源占用较大的计算可以很容易被分割为多个彼此完全独立的部分以任意顺序执行,则要使用并行循环.示例如下: using System; using System.Col ...
- README.md书写范例
具体参考: https://learnku.com/docs/laravel-specification/5.5/readme-examplemd/523
- mysql 自定义函数写法
1.业务场景 有时候我们希望通过sql语句解决一些复杂的问题,比如根据一个ID 查询组织的路径.这个时候我们可以使用函数来实现. 2.函数编写 CREATE FUNCTION getGroupById ...
- VTK 显示3D模型的网格线(线框/wireframe)
在VTK9.1.0在Windows10+VS2019+Qt 5.15.2环境下编译安装的Qt例子中,想显示球体表面的网格线(线框/wireframe),设置actor的EdgeVisibilityOn ...