opentelemetry全链路初探--jaeger架构拆分
前言
jaeger的架构演变
在之前的描述中,一直使用jaeger:all-in-one来做数据存储与展示,jaeger:all-in-one就是将collector、query、ui、storage等等功能的大杂烩,在调试与测试环境中,非常方便,但是在生产环境肯定是不能这样用,本节就来 将其拆分成对应的子模块
jaeger架构改造
- 数据上报:可以是sdk、api、定时脚本等一切上报trace、metrics数据的工具
- collector:用于接收trace数据上报
- storage:将数据发送到对应的地方存储起来,以便UI查询使用。trace常见的storage:es、kafka等
- UI:trace常见的展示工具:jaeger
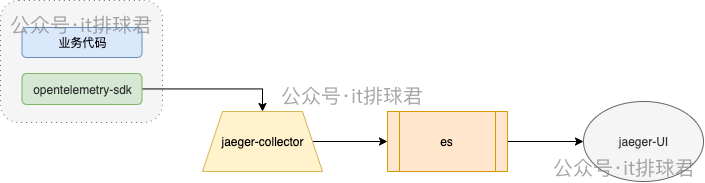
下面我们来详细描述一下整个过程
采集程序
import tornado.httpserver as httpserver
import tornado.web
from tornado.ioloop import IOLoop
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.trace import get_tracer
trace.set_tracer_provider(
TracerProvider(resource=Resource.create({SERVICE_NAME: "hello-otlp"}))
)
span_processor = BatchSpanProcessor(OTLPSpanExporter(endpoint="http://127.0.0.1:14318/v1/traces"))
trace.get_tracer_provider().add_span_processor(span_processor)
def traced(name):
def decorator(func):
def wrapper(*args, **kwargs):
tracer = get_tracer(__name__)
with tracer.start_as_current_span(name):
return func(*args, **kwargs)
return wrapper
return decorator
class TestFlow(tornado.web.RequestHandler):
def get(self):
views()
self.finish('hello world')
@traced("phase-1")
def views():
views_sub_2()
views_sub_3()
@traced("phase-2")
def views_sub_2():
pass
@traced("phase-3")
def views_sub_3():
pass
def applications():
urls = []
urls.append([r'/', TestFlow])
return tornado.web.Application(urls)
def main():
app = applications()
server = httpserver.HTTPServer(app)
server.bind(10000, '0.0.0.0')
server.start(1)
IOLoop.current().start()
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt as e:
IOLoop.current().stop()
finally:
IOLoop.current().close()
jaeger-collector
docker run -d --name jaeger-collector \
-p 14250:14250 \
-p 14268:14268 \
-p 14317:4317 \
-p 14318:4318 \
-e SPAN_STORAGE_TYPE=elasticsearch \
-e ES_SERVER_URLS=http://10.22.12.178:9200 \
-e ES_USERNAME=elastic \
-e LOG_LEVEL=debug \
jaegertracing/jaeger-collector:1.72.0
storage
这里使用es来充当storage
docker run -d --name jaeger-es \
-e bootstrap.memory_lock=true \
-e discovery.type=single-node \
-p 9200:9200 \
-p 9300:9300 \
-e xpack.security.enabled=false \
-e xpack.security.http.ssl.enabled=false \
elastic/elasticsearch:9.1.2
jaeger-ui
docker run -d --name jaeger-query \
-p 16686:16686 \
-p 16687:16687 \
-e SPAN_STORAGE_TYPE=elasticsearch \
-e ES_SERVER_URLS=http://10.22.12.178:9200 \
-e ES_USERNAME=elastic \
-e LOG_LEVEL=debug \
jaegertracing/jaeger-query:1.72.0
来看下效果:
- 首先让上报程序上报trace数据:
curl 127.0.0.1:10000 - 登录
http://127.0.0.1:16686/查看
![]()
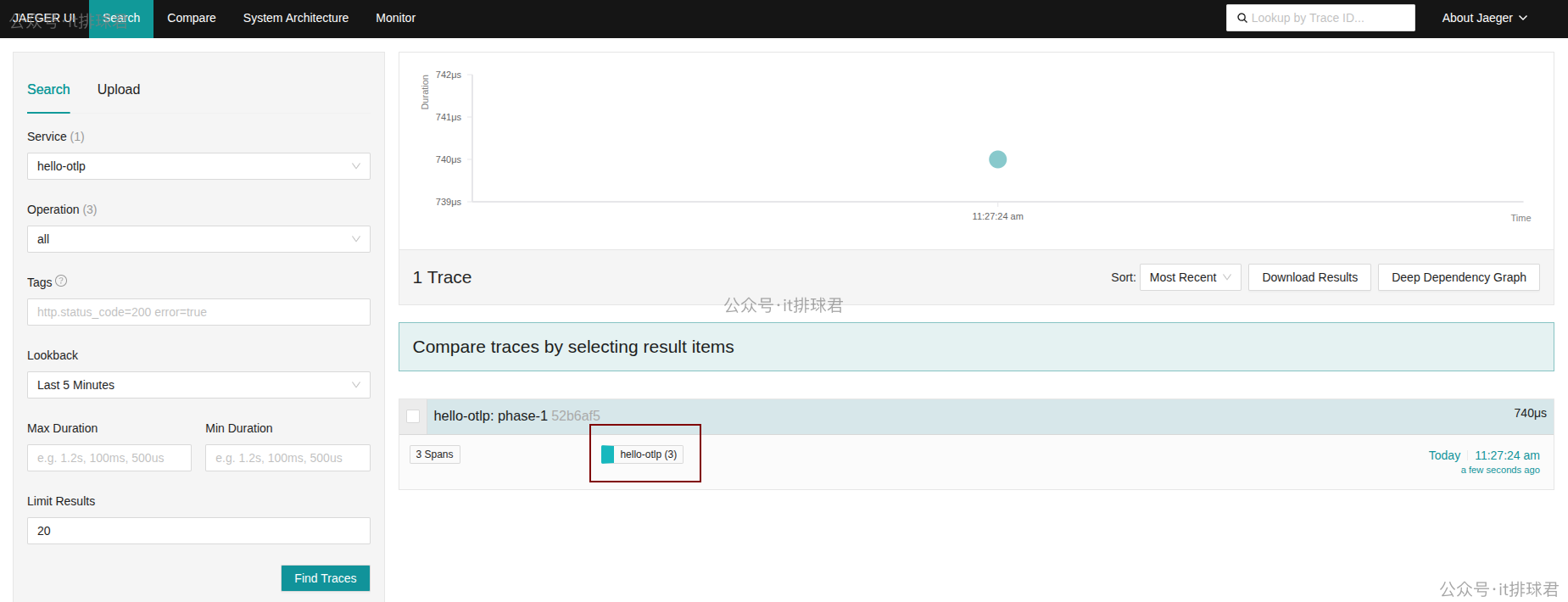
很好,数据已经正常上报了
小结
- jaeger从1.35版本开始支持原生otlp协议,所以可以直接在sdk中使用otlp协议上报。如果是低版本的jaeger,需要使用jaeger grpc、jaeger thrift等协议
- 这里要非常小心版本对应的问题,文中jaeger的版本是1.72,而es的版本是9.1.2,如果版本不匹配,很容易报错。在低版本中,Jaeger Collector 在创建 ES 索引模板时,模板的格式不符合 Elasticsearch 8.x 新的要求 造成的。ES 7.x 还接受某些字段是字符串,但 8.x 对 index_template 结构要求更严格,会直接拒绝了导致无法启动
新增数据处理层otel-collector
在jaeger-collector上做一层otel-collector做数据采集
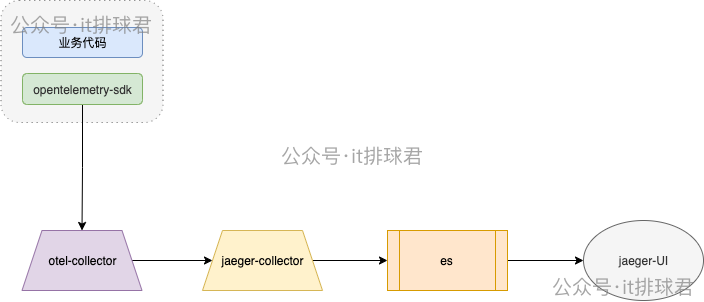
对应的修改:
数据采集
...
span_processor = BatchSpanProcessor(OTLPSpanExporter(endpoint="http://127.0.0.1:4318/v1/traces"))
...
otel-collector
docker run -d --name=otel-collector \
-v ./otel-collector-config.yaml:/etc/otelcol/config.yaml \
-p 4317:4317 \
-p 4318:4318 \
otel/opentelemetry-collector:latest
配置完成,有位老哥说了,为啥要这么配置,本来我直接发到jaeger-collector就行了,现在多加一层otel-collector,多做了一层无用功,完全没必要啊
这位老哥的思路非常清晰,现在来仔细观察下otel-collector与jaeger-collector的区别
otel-collector与jaeger-collector
| otel-collector | jaeger-collector | |
|---|---|---|
| 作用范围 | traces、metrics | 只支持traces |
| 协议 | OTLP、prometheus、zipkin等多种协议 | jaeger thrift、jaeger grpc,新版本也支持OTLP |
| 后端支持 | 可以发到支持otel的后端,比如tempo、prometheus、logging,甚至是jaeger-collector | 只能发到 Jaeger Collector |
- jaeger的出现早于opentelemetry,所以有部分系统是通过jaeger这一套逻辑构建的,但是后面慢慢发展,不但traces数据需要分析,还有metrics、logs等重要的数据也需要分析了,那opentelemetry的出现解决了这个问题,能 采集需要的数据,并且otel-collector作为一个数据逐渐成为了数据中转中心。比如jaeger擅长分析traces,那就发到jaeger这一套生态中,包括jaeger-collector、jaeger-UI等;prometheus擅长分析metrics数据,那就将metrics发到prometheus里面去
- 所以在jaeger-collector之前新增otel-collector,并没有增加系统冗余,而是解耦了jaeger与数据采集,并且丰富了系统功能性
otel-collector采集metrics
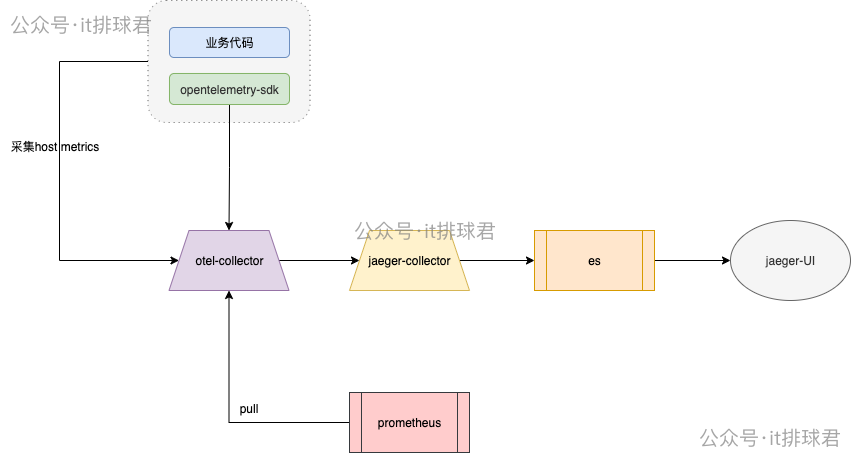
otel-collector
修改otel-collector-config.yaml
receivers:
...
hostmetrics:
collection_interval: 10s
scrapers:
cpu: {}
memory: {}
disk: {}
filesystem: {}
network: {}
exporters:
...
prometheus:
endpoint: "0.0.0.0:9464"
namespace: otelcol
service:
...
metrics:
receivers: [hostmetrics]
exporters: [prometheus]
暴露9464端口,等prometheus来拉取
docker run -d --name=otel-collector \
-v ./otel-collector-config.yaml:/etc/otelcol/config.yaml \
-p 4317:4317 \
-p 4318:4318 \
-p 9464:9464 \
otel/otel-collector:latest
prometheus
prometheus.yml
global:
scrape_interval: 5s
scrape_configs:
- job_name: "otel-collector"
static_configs:
- targets: ["10.22.12.178:9464"]
docker run -d --name prometheus \
-p 9090:9090 \
-v ./prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus:v3.5.0
检查prometheus,metrics数据已经获取
traces转换为metrics
提取traces耗时
将traces数据转换为metrics,比如文中有3段span phase-1 phase-2 phase-3,分别将它们的耗时时间转换成metrics存入prometheus,便于分析
1)修改otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
hostmetrics:
collection_interval: 10s
scrapers:
cpu: {}
memory: {}
disk: {}
filesystem: {}
network: {}
connectors:
spanmetrics:
dimensions:
- name: operation
exporters:
otlp:
endpoint: 10.22.12.178:14317
tls:
insecure: true
prometheus:
endpoint: "0.0.0.0:9464"
namespace: otelcol
service:
pipelines:
traces:
receivers: [otlp]
exporters: [otlp, spanmetrics]
metrics:
receivers: [hostmetrics, spanmetrics]
exporters: [prometheus]
2)重新运行镜像
docker run -d --name=otel-collector \
-v ./otel-collector-config.yaml:/etc/otelcol-contrib/config.yaml \
-p 4317:4317 \
-p 4318:4318 \
-p 9464:9464 \
otel/opentelemetry-collector-contrib:0.132.3
这里需要非常小心了,由于需要对数据处理,使用了spanmetrics插件,而该插件只能在opentelemetry-collector-contrib才有,如果用opentelemetry-collector是没有的
3)上报trace数据: curl 127.0.0.1:10000,查看prometheus
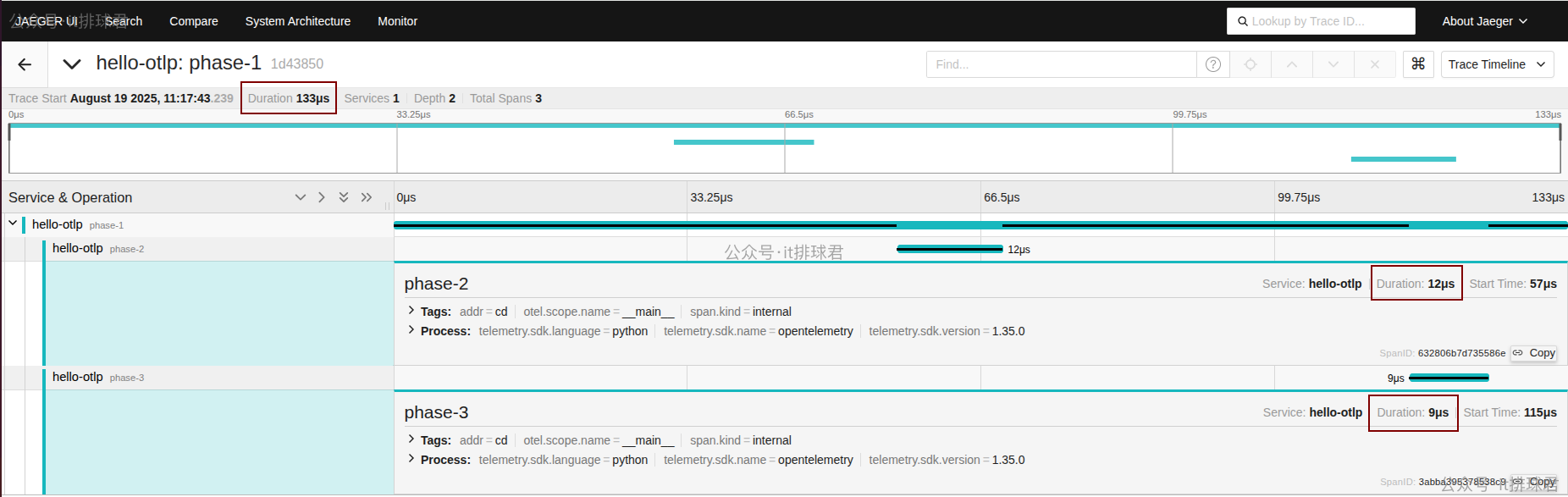
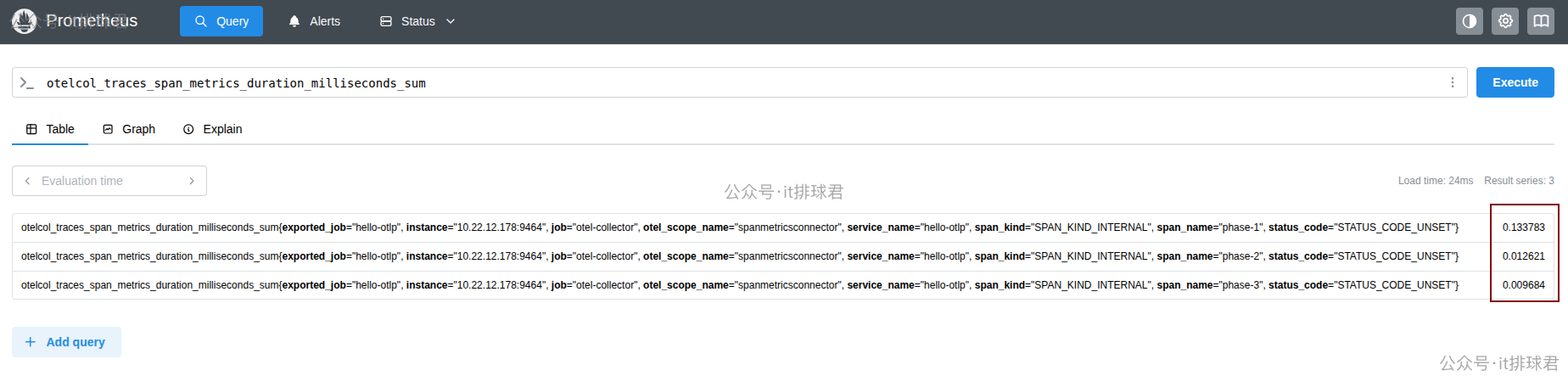
耗时也是能够对应起来的
提取traces的attribute
1)先修改下采集程序,注入attribute
...
def traced(name):
def decorator(func):
def wrapper(*args, **kwargs):
tracer = get_tracer(__name__)
with tracer.start_as_current_span(name) as span:
span.set_attribute("addr", "cd") # 注入属性
return func(*args, **kwargs)
return wrapper
return decorator
...
2)修改otel-collector配置
otel-collector-config.yaml
...
connectors:
spanmetrics:
dimensions:
- name: operation
- name: addr # 提取属性
...
3)上报trace数据: curl 127.0.0.1:10000,查看prometheus
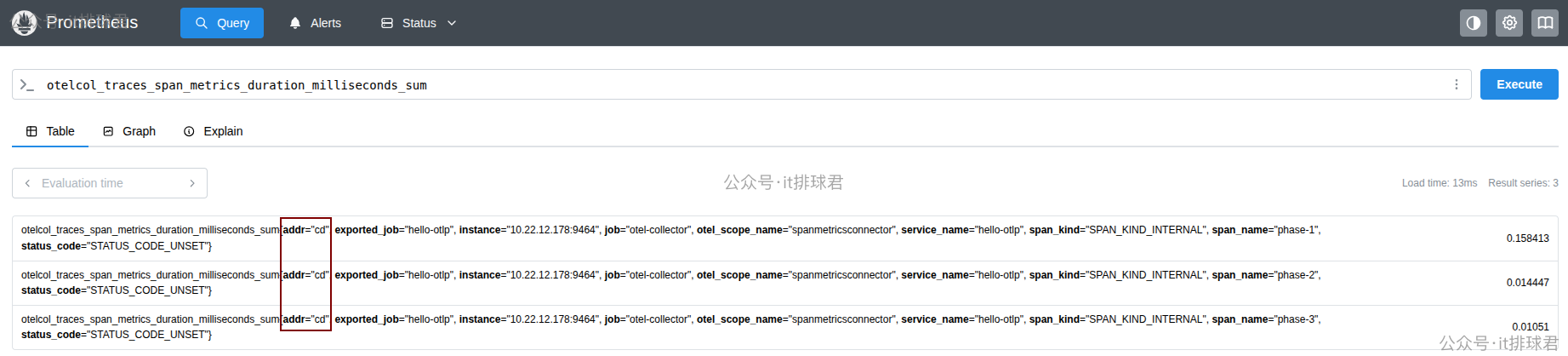
小结
- 先从jaeger出发,从all-in-one的测试架构改造成可在生产环境使用的架构
jaeger-collector-->es storage-->jaeger-UI - 新增数据处理层
otel-collector,使得整个数据采集更灵活,不但可以采集traces、也可以采集metrics otel-collector不但做数据转发,也可以做数据修改
联系我
- 联系我,做深入的交流
![]()

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教...
opentelemetry全链路初探--jaeger架构拆分的更多相关文章
- 高德全链路压测平台TestPG的架构与实践
导读 2018年十一当天,高德DAU突破一个亿,不断增长的日活带来喜悦的同时,也给支撑高德业务的技术人带来了挑战.如何保障系统的稳定性,如何保证系统能持续的为用户提供可靠的服务?是所有高德技术人面临的 ...
- Opentracing + Uber Jaeger 全链路灰度调用链,Nepxion Discovery
当网关和服务在实施全链路分布式灰度发布和路由时候,我们需要一款追踪系统来监控网关和服务走的是哪个灰度组,哪个灰度版本,哪个灰度区域,甚至监控从Http Header头部全程传递的灰度规则和路由策略.这 ...
- 基于Opentracing+Jaeger全链路灰度调用链
当网关和服务在实施全链路分布式灰度发布和路由时候,我们需要一款追踪系统来监控网关和服务走的是哪个灰度组,哪个灰度版本,哪个灰度区域,甚至监控从Http Header头部全程传递的灰度规则和路由策略.这 ...
- 京东全链路压测军演系统(ForceBot)架构解密
摘要:全链路压测是应对电商大促容量规划最有效的手段,如何有效进行容量规划是其中的架构关键问题.京东在全链路压测方面做过多年尝试,本文转载京东商城基础平台技术专家文章,介绍其最新的自动化压测 Force ...
- 全链路实践Spring Cloud 微服务架构
Spring Cloud 微服务架构全链路实践Spring Cloud 微服务架构全链路实践 阅读目录: 网关请求流程 Eureka 服务治理 Config 配置中心 Hystrix 监控 服务调用链 ...
- 基于 Istio 的全链路灰度方案探索和实践
作者|曾宇星(宇曾) 审核&校对:曾宇星(宇曾) 编辑&排版:雯燕 背景 微服务软件架构下,业务新功能上线前搭建完整的一套测试系统进行验证是相当费人费时的事,随着所拆分出微服务数量的不 ...
- 全链路压测平台(Quake)在美团中的实践
背景 在美团的价值观中,以“客户为中心”被放在一个非常重要的位置,所以我们对服务出现故障越来越不能容忍.特别是目前公司业务正在高速增长阶段,每一次故障对公司来说都是一笔非常不小的损失.而整个IT基础设 ...
- Go微服务全链路跟踪详解
在微服务架构中,调用链是漫长而复杂的,要了解其中的每个环节及其性能,你需要全链路跟踪. 它的原理很简单,你可以在每个请求开始时生成一个唯一的ID,并将其传递到整个调用链. 该ID称为Correlati ...
- Node.js 应用全链路追踪技术——全链路信息存储
作者:vivo 互联网前端团队- Yang Kun 本文是上篇文章<Node.js 应用全链路追踪技术--全链路信息获取>的后续.阅读完,再来看本文,效果会更佳哦. 本文主要介绍在Node ...
- 全链路追踪traceId,ThreadLocal与ExecutorService
关于全链路追踪traceId遇到线程池的问题,做过架构的估计都遇到过,现在以写个demo,总体思想就是获取父线程traceId,给子线程,子线程用完移除掉. mac上的chrome时不时崩溃,写了一大 ...
随机推荐
- 利用LiveNVR实现设置头RTSP直播流、RTMP等互联网直播流转换成GB28181协议
Onvif/RTSP流媒体服务 LiveNVR Onvif/RTSP流媒体服务: http://nvr.liveqing.com,支持RTSP稳定拉流接入,支持Onvif协议接入,支持RTMP/HLS ...
- LiveNVR传统安防摄像机互联网直播-二次开发相关的API接口
LiveNVR安防流媒体服务,支持RTSP稳定拉流接入,支持Onvif协议接入,支持RTMP/HLS/HTTP-FLV分发,将传统安防监控设备互联化,无插件直播等. LiveNVR相关二次开发-API ...
- BOE(京东方)“向新2025”年终媒体智享会首站落地上海 六大维度创新开启产业发展新篇章
12月17日,BOE(京东方)以"向新2025"为主题的年终媒体智享会在上海启动.正值BOE(京东方)新三十年的开局之年,活动全面回顾了2024年BOE(京东方)在各领域所取得的领 ...
- Win11的defender黄色叹号
当你把能忽略的设置全部忽略后,还是叹号时,请往下看:(重装三次系统后的偶然发现)不要点右下角defender图标进入安全中心不要点右下角defender图标进入安全中心不要点右下角defender图标 ...
- [MCP][07]logging和progress等功能说明
前言 截至目前(2025年9月19日),除了基础的Prompt.Resource和Tool概念,FastMCP还提供了以下功能:Sampling.Elicitation.Logging.Progres ...
- DesignWareBuildingBlock IP的仿真与综合
感谢一下同学的协助,跑通了一个case. IP核调用 dw_fp_mac.sv module dw_fp_mac( inst_a, inst_b, inst_c, inst_rnd, z_inst, ...
- 【光照】[各向异性]在UnityURP中的实现
[从UnityURP开始探索游戏渲染]专栏-直达 Kajiya-Kay模型在Unity URP中的BRDF实现 模型原理与特点 Kajiya-Kay模型是一种专门用于模拟头发.毛发等纤维状材质各向异性 ...
- SpringBoot项目打包与部署
springboot的war想要在tomcat服务器上运行,必须添加配置. 1.继承并重写 让启动类继承SpringBootServletInitializer,并重写configure方法,关键代码 ...
- win10安装mysql8.0.19zip包
本文下载的是MySQL的最新版本8.0.19,windows下64位的ZIP包,本人电脑系统是Windows 10. 把下载的压缩包,解压到 D:\mysql-8.0.19-winx64,在解压后的目 ...
- 【附源码】JAVA进销存系统源码+SpringBoot+VUE+前后端分离
学弟,学妹好,我是爱学习的学姐,今天带来一款优秀的项目:进销存系统 . 本文介绍了系统功能与部署安装步骤,如果您有任何问题,也请联系学姐,偶现在是经验丰富的程序员! 一. 系统演示 系统测试截图 系统 ...