python,爬取小说网站小说内容,同时每一章存在不同的txt文件中
思路,第一步小说介绍页获取章节地址,第二部访问具体章节,获取章节内容
具体如下:先获取下图章节地址

def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
上方代码可获取到下图红色区域内内容,即每一章节地址的变量部分,且全部存在脚本输出的集合中
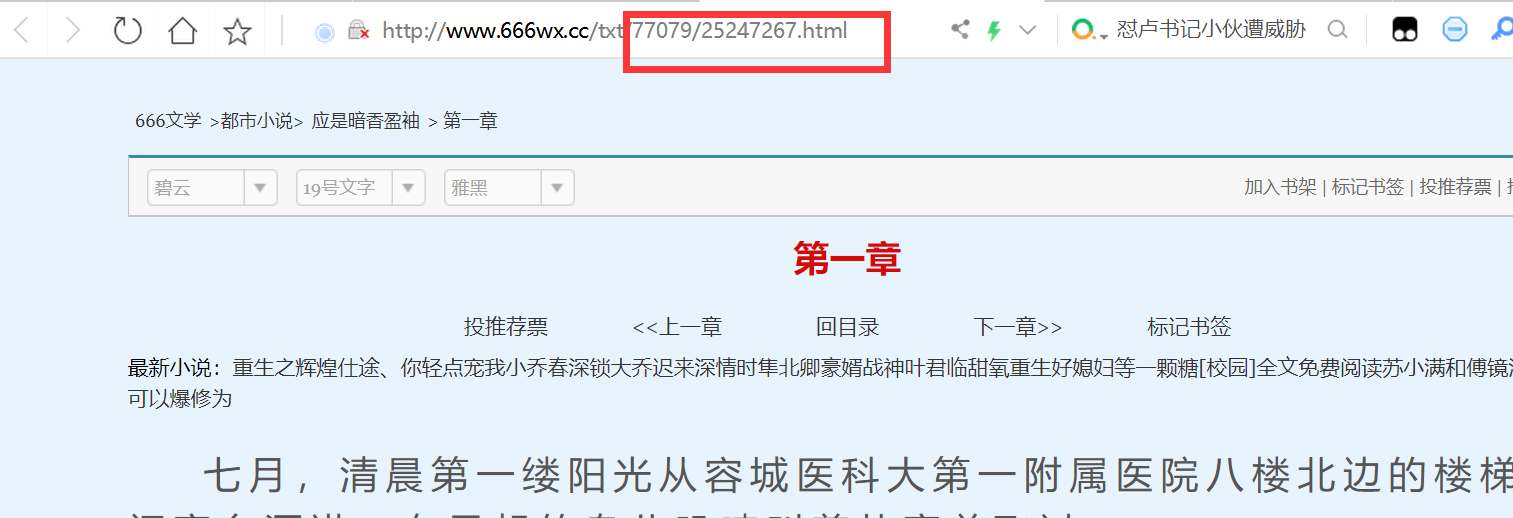
第二部,循环访问集合中的章节地址,获取章节内容,同时逐行存储在对应章节命名的txt文件中
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
生成的文件一览
txt内容
全部脚本
# -*-coding:utf8-*-
# encoding:utf-8
#本脚本爬取http://www.666wx.cc站小说
import requests
from lxml import etree
import os
import sys
import re headers = {
'authority': 'cl.bc53.xyz',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__cfduid=d9b8dda581516351a1d9d388362ac222c1603542964',
} value = "http://www.666wx.cc/txt/77079/"#小说地址 path = os.path.abspath(os.path.dirname(sys.argv[0])) def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
print("ok")
python,爬取小说网站小说内容,同时每一章存在不同的txt文件中的更多相关文章
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 用Python爬取斗鱼网站的一个小案例
思路解析: 1.我们需要明确爬取数据的目的:为了按热度查看主播的在线观看人数 2.浏览网页源代码,查看我们需要的数据的定位标签 3.在代码中发送一个http请求,获取到网页返回的html(需要注意的是 ...
- Python爬取某网站文档数据完整教程(附源码)
基本开发环境 (https://jq.qq.com/?_wv=1027&k=NofUEYzs) Python 3.6 Pycharm 相关模块的使用 (https://jq.qq.com/?_ ...
- 利用Python爬取电影网站
#!/usr/bin/env python #coding = utf-8 ''' 本爬虫是用来爬取6V电影网站上的电影资源的一个小脚本程序,爬取到的电影链接会通过网页的形式显示出来 ''' impo ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
- python爬取招聘网站数据
# -*- coding: utf-8 -*- # 爬虫分析 from bs4 import BeautifulSoup from lxml import etree from selenium im ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- Python爬取mn52网站美女图片以及图片防盗链的解决方法
防盗链原理 http标准协议中有专门的字段记录referer 一来可以追溯上一个入站地址是什么 二来对于资源文件,可以跟踪到包含显示他的网页地址是什么 因此所有防盗链方法都是基于这个Referer字段 ...
- python爬取凤凰网站的新闻,及其链接地址,来源,时间和内容,用selenium自动化和requests处理数据
有写规则需要自己定义判断. import requests from selenium import webdriver import time def grasp(urlT): driver = w ...
- python爬取视频网站m3u8视频,下载.ts后缀文件,合并成整视频
最近发现一些网站,可以解析各大视频网站的vip.仔细想了想,这也算是爬虫呀,爬的是视频数据. 首先选取一个视频网站,我选的是 影视大全 ,然后选择上映不久的电影 “一出好戏” . 分析页面 我用的是c ...
随机推荐
- Java类加载机制与JVM运行时数据区各逻辑内存区域与JDK的版本相关差异浅谈
Java类加载机制与JVM运行时数据区各逻辑内存区域与JDK的版本相关差异浅谈 [摘要] JVM(Java Virtual Machine)作为Java研发人员工作的每天都会接触到的虚拟机,其运行机制 ...
- 一镜到底,通过Llama大模型架构图看透transformers原理
一镜到底,通过Llama大模型架构图看透transformers原理 Llama Nuts and Bolts是Github上使用Go语言从零重写Llama3.1 8B-Instruct模型推理过程( ...
- 再次使用layui遇见问题
Layui似乎只接收data里的数据,所以只能使用这个方式把原有数据放入dataparseData: function (res) { //res 即为原始返回的数据 return { "c ...
- Kali Linux 简介
Kali Linux 简介 Kali Linux 是一个由 Offensive Security 公司开发.维护和资助的基于 Debian 的 Linux 发行版,专为高级渗透测试和安全审计而设计.它 ...
- 手把手教你喂养 DeepSeek 本地模型
上篇文章<手把手教你部署 DeepSeek 本地模型>首发是在公众号,但截止目前只有500多人阅读量,而在自己博客园BLOG同步更新的文章热度很高,目前已达到50000+的阅读量,流量是公 ...
- Flink基础Source配置
一.pom文件 https://www.cnblogs.com/robots2/p/16048648.html 二.代码demo FlinkBaseSource.java package net.xd ...
- Microsoft.Expression.Drawing文件安装
使用Blend的绘制功能,需要引用 Microsoft.Expression.Drawing 库文件, xmlns:ed="http://schemas.microsoft.com/expr ...
- 【忍者算法】从拉链到链表:探索有序链表的合并之道|LeetCode 21 合并两个有序链表
从拉链到链表:探索有序链表的合并之道 生活中的合并 想象你正在整理两叠按日期排好序的收据.最自然的方式就是:拿起两叠收据,每次比较最上面的日期,选择日期较早的那张放入新的一叠中.这个简单的日常操作,恰 ...
- CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
CSnakes 是一个用于在.NET项目中嵌入Python代码的工具,由.NET源生成器和运行时组成,能够实现高效的跨语言调用,Github:https://github.com/tonybalone ...
- 植物大战僵尸杂交版,最新安装包(PC+手机+苹果)+ 修改器+高清工具
植物大战僵尸杂交版:全新游戏体验与创意碰撞 游戏简介 <植物大战僵尸杂交版>是由B站知名UP主潜艇伟伟迷基于经典游戏<植物大战僵尸>进行的一次大胆且富有创意的二次创作.这款游戏 ...