[转帖]Git数据存储的原理浅析
Git数据存储的原理浅析
https://segmentfault.com/a/1190000016320008
写作背景
进来在闲暇的时间里在看一些关系P2P网络的拓扑发现的内容,重点关注了Markle Tree的知识点,在一篇文章里(https://www.sdnlab.com/20095....),发现了了一句话“Merkle DAG的一个常见例子就是Git存储库”,于是查找了一些关于git存储库的原理,先整理如下。仅供自己和大家参考。
Git存储库解析
当时我的疑问:
- git怎么存储数据的,如何能根据存储的数据可以很精确的回退到制定的版本?
- git存储和docker的存储机制类似吗?是不是都是分层的存储?
- git如果不是分层,每次提交都存储起来,那么数据量大了会怎么办?
解惑
我们的解惑路线是,从新建一个本地git仓库开始,一步一步增加数据和提交,观察内容的具体变化。
首先使用
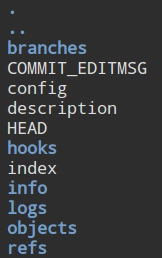
git init新建一个本地仓库,然后打开仓库中的.git文件夹
- HEAD表示当前提交的指针位置;
- index是索引文件;
- refs文件夹中的文件是不同分支指向的commitID;
- logs文件夹中记录的是每次refs的历史记录;
- objects文件夹中的内容就是用来存放git本地仓库对象
既然找到了存储git数据的位置,那么git数据结构是什么样的呢?
- git 是以键值的方式存储的,也就是说任何类型的数据都可以存储。因此也可以在任何时候通过键取出对应的值;
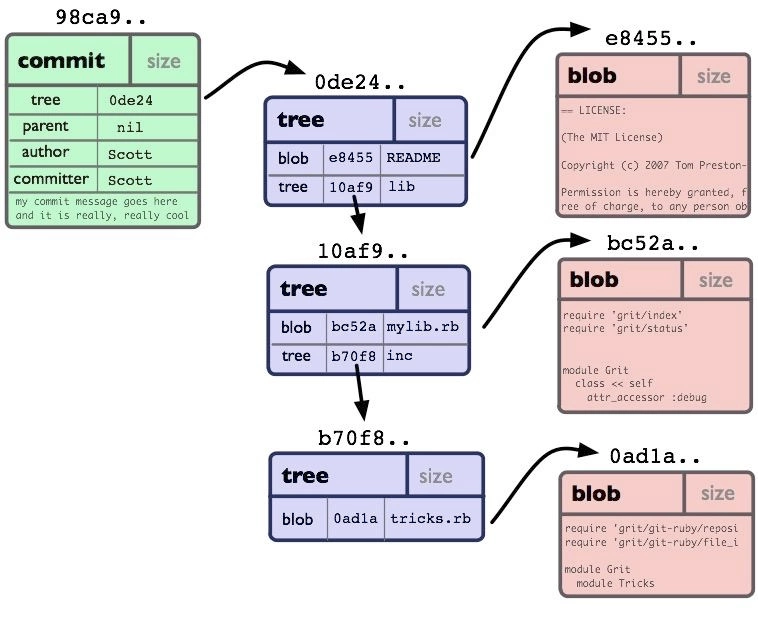
git中底层生成了4中数据的对象:
- tree对象:可以看作一个目录,管理一些“tree”对象或是“blob”对象。它有一串指向“blob”对象或是其它“tree”对象的指针,一般用来表示内容之间的目录层次关系(就像文件和子目录)。
- blob对象: 一个“blob”通常用来存储文件的内容。一个“blob”对象就是一块二进制数据,blob对象的键是根据SHA1算法生成的,所以若两个文件在一个目录树或是一个版本仓库中有同样的数据内容,那么它们将会共享同一个“blob”对象,和其所对应的文件所在路径、文件名是否改被更改都完全没有关系。
- commit对象:“commit”对象指向一个“tree对象”,并且带有相关的描述信息,标记项目某一个特定时间点的状态。它包括一些关于时间点的元数据,如时间戳、最近一次提交的作者、指向上次提交的指针等等。
- tag对象: 一个“tag”对象包括一个对象名(SHA1签名)、对象类型、标签名、标签创建人的名字(“tagger”), 还有一条可能包含有签名(signature)的消息。
当新增一些内容的时候,进行
git commit命令会出现什么变化?
- 当进行一次提交的时候,objects、logs和refs文件夹都会发生变化,我们主要关注objects文件夹。
- 每次commit都会对数据进行一次保存,会生成commit对象、tree对象和blob对象;
- objects文件夹里面的数据存放的具体规则,对于这三种对象,都会用SHA-1对内容和头信息生成Hash值,去hash值的前两位为objects目录下面的文件夹的名字,取剩余38个字符为文件名,例:8b0c4fe1567a463214c09334b54977e0114c90fe,取8b在objects创建一个文件夹,取0c4fe1567a463214c09334b54977e0114c90fe为文件名在8b文件夹下创建一个文件。
知识点学习了之后,我们怎么去验证呢?
- 使用
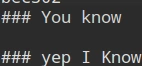
git cat-file对我们提交的内容进行验证。- 我进行了两次commit,一次是完全新建的一个README.md文件,里面是有一行数据(### You Know);第二次commit,新建一个test.py文件和在README.md中新添加了一些数据;
git cat-file -t查看对象的类型,git cat-file -p优雅的方式打印对象的内容。
- 使用
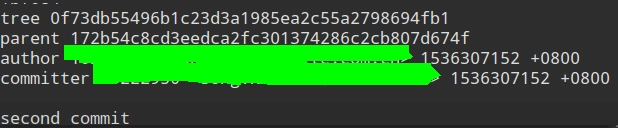
git log --pretty=oneline查看我的两次提交- 使用
git cat-file -t 172b54c8cd3eedca2fc301374286c2cb807d674f查看第一次提交的类型- 使用
git cat-file -p 172b54c8cd3eedca2fc301374286c2cb807d674fe查看第一次提交的内容- 使用
git cat-file -p 8b0c4fe1567a463214c09334b54977e0114c90fe查看第一次提交的tree对象,可以看到tree对象中存放的是一个blob对象,就是我们第一次提交新建的文件README.md- 使用
git cat-file -p 67aeba604cea61ec63d19db0706b19d846c65ba4查看第一次提交的blob对象的内容为### You Know- 使用
git cat-file -p 03543a4c19023da01b5114d7f7a614d95a1bf084查看第二次提交的内容- 使用
git cat-file -p 03543a4c19023da01b5114d7f7a614d95a1bf084查看第二次提交的tree对象内容,包括修改的内容和新增的内容- 使用
git cat-file -p 03543a4c19023da01b5114d7f7a614d95a1bf084查看第二次提交的README.md blob对象内容,可以看到是整个文件的全部内容,而不是仅仅包含修改的数据。
总结问题的答案
- git的数据存储数据结构是键值类型,分为4个对象,并且每次提交都是整个文件的存储,而不是分层的增加存储,所以这样会导致存储的数据量很大,那git用的方法是使用zlib对数据进行压缩,所以我们打开存储的文件是这样的数据,那我们都是用cat-file命令来查看的,怎么才能这些内容是经过zlib压缩过的呢?
- 我用GO语言写了一个简单的程序,来验证这些数据是经过zlib压缩之后的,运行这个程序的时候带上你要查看git对象的文件路径,就可以看到被还原的内容了;

go程序代码
package main import ( "bytes" "compress/zlib" "fmt" "io" "io/ioutil" "os" ) //进行zlib压缩 func DoZlibCompress(src []byte) []byte { var in bytes.Buffer w := zlib.NewWriter(&in) w.Write(src) w.Close() return in.Bytes() } //进行zlib解压缩 func DoZlibUnCompress(compressSrc []byte) []byte { b := bytes.NewReader(compressSrc) var out bytes.Buffer r, _ := zlib.NewReader(b) io.Copy(&out, r) return out.Bytes() } func main() { args := os.Args { fmt.Println("Should input zlib file path.") return } b, err := ioutil.ReadFile(args[]) if err != nil { fmt.Print(err) } fmt.Println(string(DoZlibUnCompress(b))) }






[转帖]Git数据存储的原理浅析的更多相关文章
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
- kafka 数据存储结构+原理+基本操作命令
数据存储结构: Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的.每个topic又可以分成几个不同的partition(每个topic有几个partitio ...
- MySQL InnoDB 存储引擎原理浅析
注:本文主要基于MySQL 5.6以后版本编写,多数知识来着书籍<MySQL技术内幕++InnoDB存储引擎>,本文章仅记录个人认为比较重要的部分,有兴趣的可以花点时间读原书. 一.MyS ...
- 图解Raid5数据存储的原理
- git知识总结-1.git基础之数据存储
1.前言 git包含四种对象文件: blob tree commit tag(目前没用到,暂时忽略) 2. git对象的关系 图 git三种对象关系 粗略一看,可以大致感觉出blob类似于文件 ...
- ValueStack和OGNL达到Struts2形式的数据存储原理
(1)最近学习struts相框,我们在快乐struts强大.为了便于使用转发,但不了解详细的内部数据存储: (2)网上找了很多关于struts数据存储的原理,但我还没有找到一个具体的解释,本书上找到了 ...
- zookeeper原理解析-数据存储
Zookeeper内存结构 Zookeeper是怎么存储数据的,什么机制保证集群中数据是一致性,在网络异常,当机以及停电等异常情况下恢复数据的,我们知道数据库给我们提供了这些功能,其实zookeepe ...
- [转帖]Docker五种存储驱动原理及应用场景和性能测试对比
Docker五种存储驱动原理及应用场景和性能测试对比 来源:http://dockone.io/article/1513 作者: 陈爱珍 布道师@七牛云 Docker最开始采用AUFS作为文件系统 ...
- 重新学习MySQL数据库3:Mysql存储引擎与数据存储原理
重新学习Mysql数据库3:Mysql存储引擎与数据存储原理 数据库的定义 很多开发者在最开始时其实都对数据库有一个比较模糊的认识,觉得数据库就是一堆数据的集合,但是实际却比这复杂的多,数据库领域中有 ...
随机推荐
- UART串口通信
#include "sys.h" #include "delay.h" #include "usart.h" u8 rdata[]; UAR ...
- python生成语谱图
语音的时域分析和频域分析是语音分析的两种重要方法,但是都存在着局限性.时域分析对语音信号的频率特性没有直观的了解,频域特性中又没有语音信号随时间的变化关系.而语谱图综合了时域和频域的优点,明显的显示出 ...
- Error at offset之反序列化
关于PHP 序列化(serialize)和反序列化(unserialize)出现错误(Error at offset)的解决办法. 首先我们分析一下为什么会出现这个错误: 编码问题 UTF-8: AN ...
- ocv & derate & crpr
OCV: on-chip-variation 是指芯片在制造工艺P.工作电压V.环境温度T 等参数的局部变化情况下导致的 cell &net delay 变化,比如假设从clk 到两个reg ...
- MVC 在action方法中获取当前action的控制器名和action名
如何在某个action方法中获取它所在的控制器和action名称呢. string controllerName = Request.RequestContext.RouteData.Values[& ...
- 虚拟机-Debian服务器配置
目的:用虚拟机中的Debian 8 操作系统作为web服务器 一.安装操作系统 首先要在vmware中安装一个debian操作系统,由于要让在局域网中的其他计算机能访问到此虚拟操作系统,因此在vmwa ...
- Hadoop大数据平台构建
基础:linux常用命令.Java编程基础大数据:科学数据.金融数据.物联网数据.交通数据.社交网络数据.零售数据等等. Hadoop: 一个开源的分布式存储.分布式计算平台.(基于Apache) H ...
- VBA删除 语法
Option Explicit '清空数据 Private Sub CommandButton1_Click() Dim qknum As Integer '选择是或者否 来确认删除数据 '中对话 ...
- UWP 下载文件显示下载进度
<Page x:Class="WgscdProject.TestDownloadPage" xmlns="http://schemas.microsoft.com/ ...
- 20155237 2016-2017-2 《Java程序设计》第十周学习总结
20155237 2016-2017-2 <Java程序设计>第十周学习总结 教材学习内容总结 计算机网络,是指分布在不同地理区域的计算机用通信线路互连起来的一个具有强大功能的网络系统.网 ...