Scrapy 框架(二)数据的持久化
scrapy数据的持久化(将数据保存到数据库)
一、建立项目
1、scrapy startproject dushu
2、进入项目
cd dushu
执行:scrapy genspider -t crawl read www.dushu.com
查看:read.py
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1175.html']

注:项目更改了默认模板,使其具有递归性
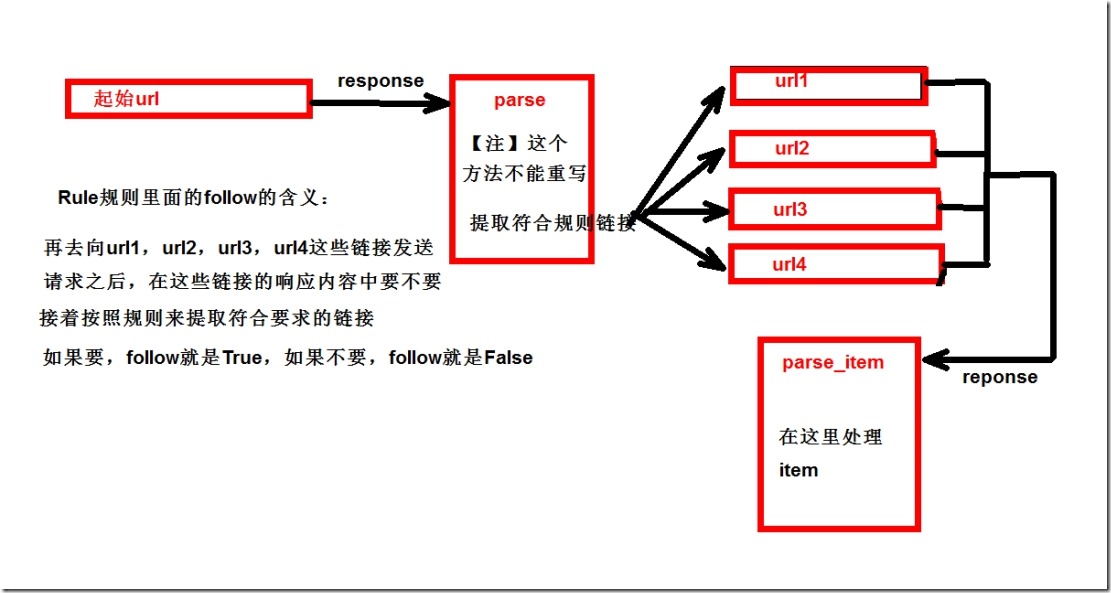
3、模板CrawlSpider具有以下优点:
1)继承自scrapy.Spider;
2)CrawlSpider可以定义规则
在解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求;
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的;
3)模拟使用:
a: 正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
b: xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
c:css用法:links3 = LinkExtractor(restrict_css='.x')
4、更改模板后rules参数解释:
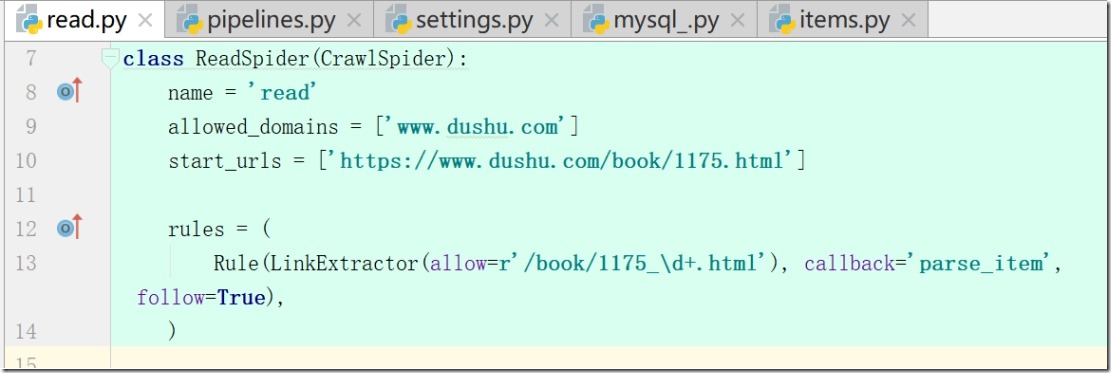
a:参数一 (allow=r'/book/1175_\d+.html') 匹配规则;
b: 参数二 callback='parse_item' ,数据回来之后调用多方法
c: 参数三,True,从新的页面中继续提取链接
注:False,当前页面中提取链接,当前页面start_urls
5、 修改start_urls
start_urls = ['https://www.dushu.com/book/1175.html']
写 def parse_item(self, response)
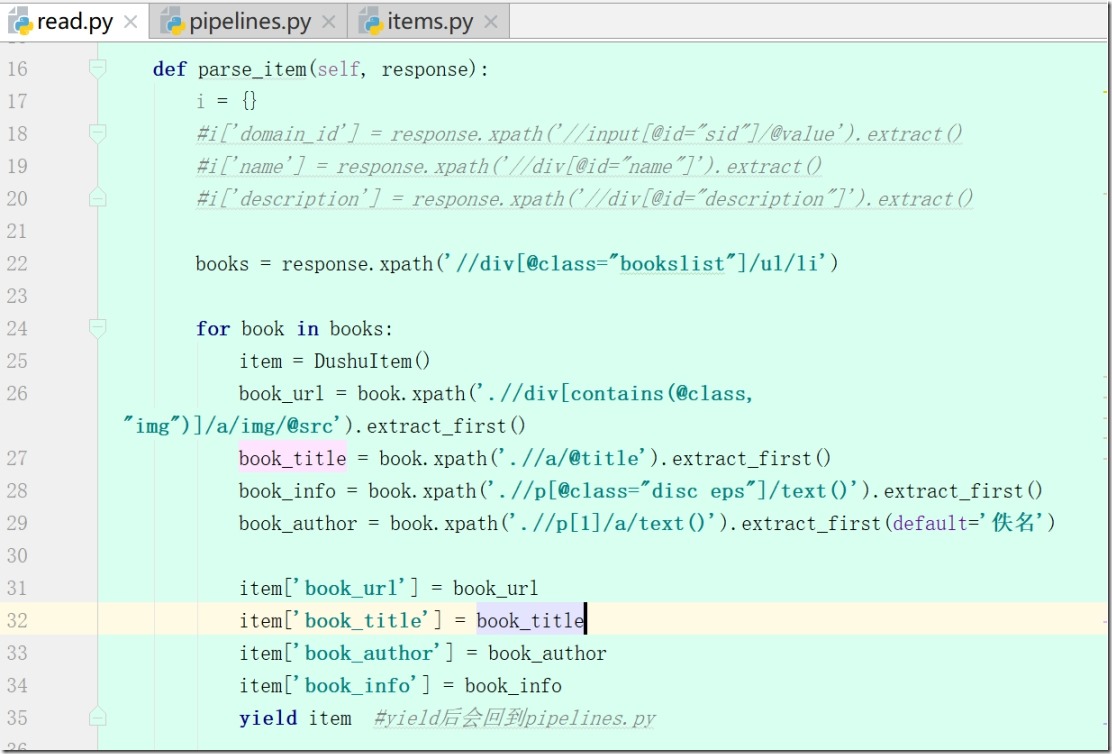
6、items.py
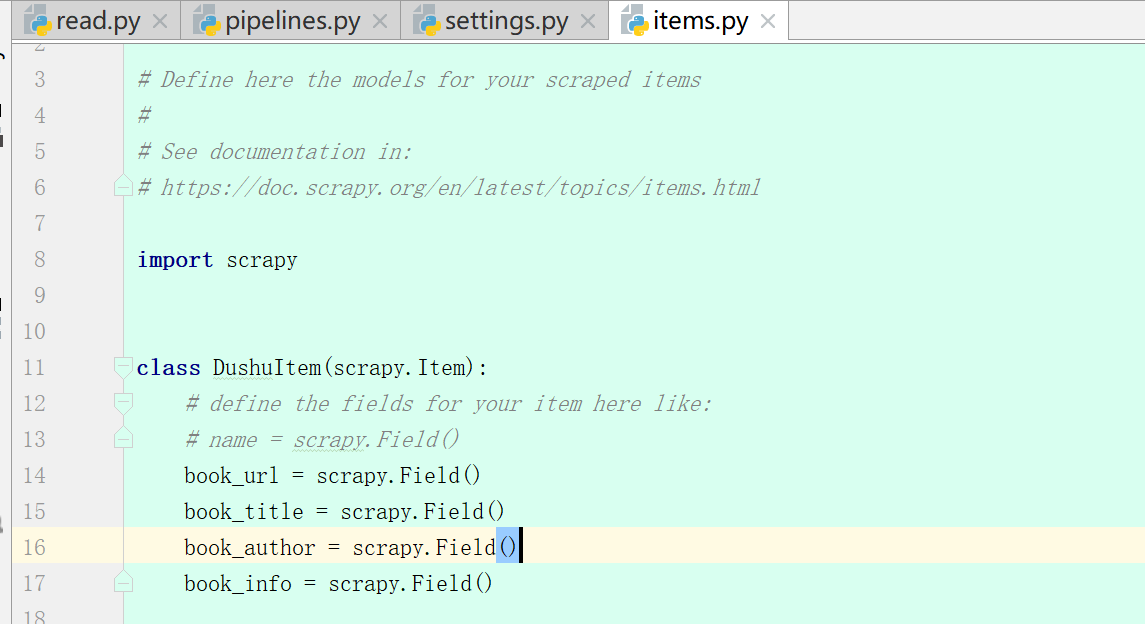
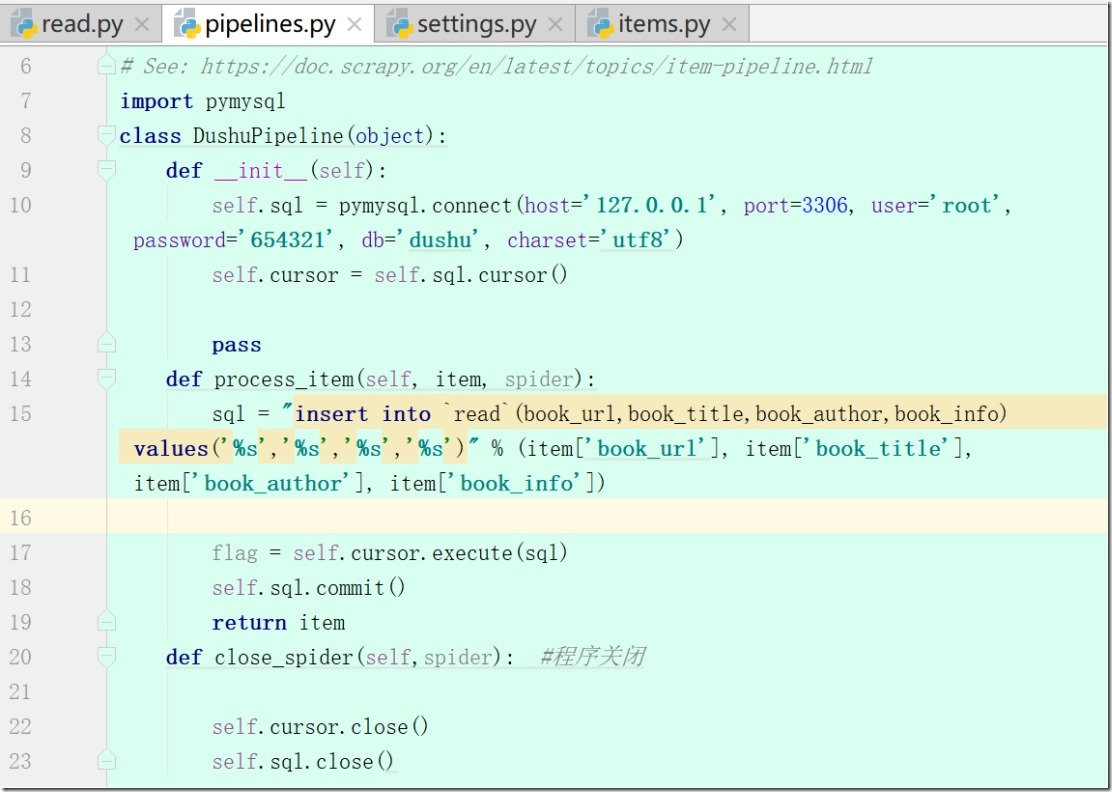
7、pipelines.py(yield后会回到pipelines.py)
1)写def __init__(self): 和 def close_spider(self,spider):
2)连接mysql,保存数据
3)启动mysql (Navicat)
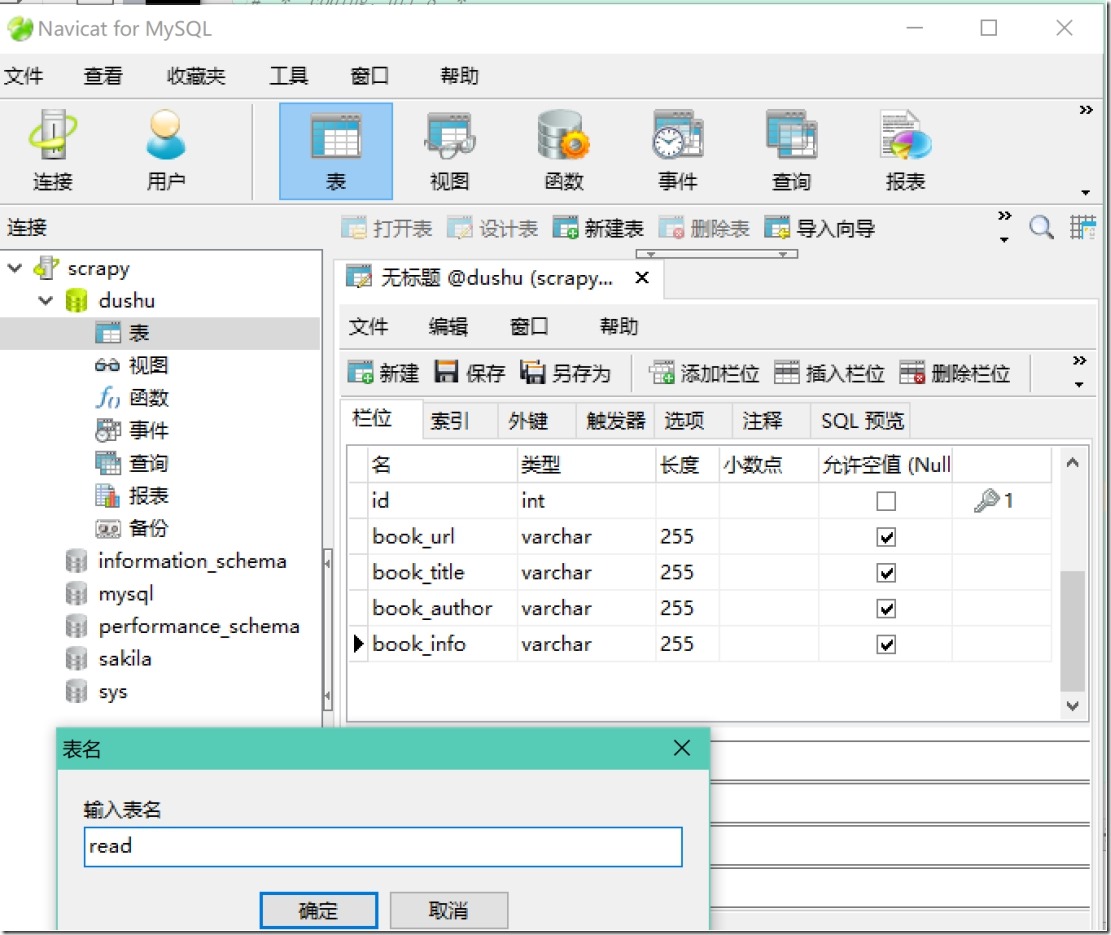
4) 连接数据库def process_item(self, item, spider)
5)setting(robots、USER_AGENT、ITEM_PIPELINES)
6)read.py(修改rules)
8、执行scrapy crawl read,将数据写入数据库
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


Scrapy 框架(二)数据的持久化的更多相关文章
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- scrapy框架基于管道的持久化存储
scrapy框架的使用 基于管道的持久化存储的编码流程 在爬虫文件中数据解析 将解析到的数据封装到一个叫做Item类型的对象 将item类型的对象提交给管道 管道负责调用process_item的方法 ...
- Python项目--Scrapy框架(二)
本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息 环境 win8, python3.7, pycharm 正文 1. 创建scrapy项目文件 在cmd命令行中任意目录下执行 ...
- (六--二)scrapy框架之持久化操作
scrapy框架之持久化操作 基于终端指令的持久化存储 基于管道的持久化存储 1 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过 ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- scrapy框架的另一种分页处理以及mongodb的持久化储存以及from_crawler类方法的使用
一.scrapy框架处理 1.分页处理 以爬取亚马逊为例 爬虫文件.py # -*- coding: utf-8 -*- import scrapy from Amazon.items import ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- 理解Java反射
一.反射简介 Java让我们在运行时识别对象和类的信息,主要有2种方式:一种是传统的RTTI,它假定我们在编译时已经知道了所有的类型信息:另一种是反射机制,它允许我们在运行时发现和使用类的信息. 1. ...
- git 报错:error: failed to push some refs to 'https://github.com/Anderson-An/******.git'(已解决)
提交push 报错: $ git push origin masterTo https://github.com/Anderson-An/******.git ! [rejected] master ...
- ArcGIS Server + ArcGIS Portal 10.5
1.安装IE11 2. 域名需要在C:\Windows\System32\drivers\etc\host文件中添加 127.0.0.1 机器名.域名 win2008.smartmap.com 19 ...
- 树莓派 温度监控 PWM 控制风扇 shell python c 语言
Mine: 图中圈出来的是三极管 和滤波电容 依赖库: wiringPi sudo apt-get install wiringpi Shell脚本 本文介绍使用Shell脚本在树莓派上启用软件PWM ...
- 【CLR Via C#】16 数组
所有的数组都隐式的从System.Array抽象类派生,后者又派生自System.Object 数组是引用类型,所以会在托管堆上分配内存,数组对象占据的内存块包含数组的元素,一个类型对象指针.一个同步 ...
- C# 程序员最常犯的 10 个错误http://www.oschina.net/translate/top-10-mistakes-that-c-sharp-programmers-make
来源:http://www.oschina.net/translate/top-10-mistakes-that-c-sharp-programmers-make 关于C# C#是达成微软公共语言运行 ...
- java实现文件复制粘贴功能
java编程思想中讲到了IO流的思想,以前对于java基础总是不够深入,浅尝辄止,如今碰到语句插桩的时候就感到书到用时方恨少啊! 文件的复制涉及到源文件和新文件(无需手动创建),给出源文件的路径和文件 ...
- 类与接口(三)java中的接口与嵌套接口
一.接口 1. 接口简介 接口: 是java的一种抽象类型,是抽象方法的集合.接口比抽象类更加抽象的抽象类型. 接口语法: [修饰符] [abstract] interface 接口名 [extend ...
- Appium环境搭建(MAC版)
一.环境搭建 (1)安装node.js brew install node (2)安装Xcode 测试iOS App需要.打开Finder,在Applications文件夹下,看是否有Xcode.ap ...
- Python笔记(十):正则表达式
正则表达式对比工具 https://pan.baidu.com/s/1XIPyF1vFSj5PACPx9zW8_g (一) 正则表达式符号和特殊字符 符号 说明 示例 | 或 re1|re2 ...