python写一个信息收集四大件的脚本
0x0前言:
带来一首小歌:
之前看了小迪老师讲的课,仔细做了些笔记
然后打算将其写成一个脚本。
0x01准备:
requests模块
socket模块
optparser模块
time模块
0x02笔记和思路:
笔记:
信息收集四大件
6.快速判断网站系统类型:
改一个网站后缀名文件,看它对大小写是否敏感
windows:不区分大小写
Linux:区分大小写
7.判断网站语言格式
看后缀
动态语言
疑问:伪静态该怎么判断
8.判断网站的数据库类型
端口扫描、
SQL报错注入
搭建分析
以下3种方法会导致探测数据库失败:
知识点:
ACCESS:无端口
MYSQL:3306
MSSQL:1433
ORACLE:1521
1.内网服务器 (通过内网穿透将本机的东西眏射出来,就是转发某个端口(类似于ngrok))
2.将数据库默认端口修改了
3.站库分离(网站源码和数据库不在一台服务器上)
9.判断网站架构
审查元素(F12)
判断系统的思路:
随便找一个网站的目录然后将其后缀其中一个改为大写
如果页面返回和原来一样的页面就是windows系统
如果页面返回和原来的页面不一样就是Linux系统
那我们也就可以知道了,返回也面的字节是不一样的
我们就可以写一个判断了
证实:
原来的页面
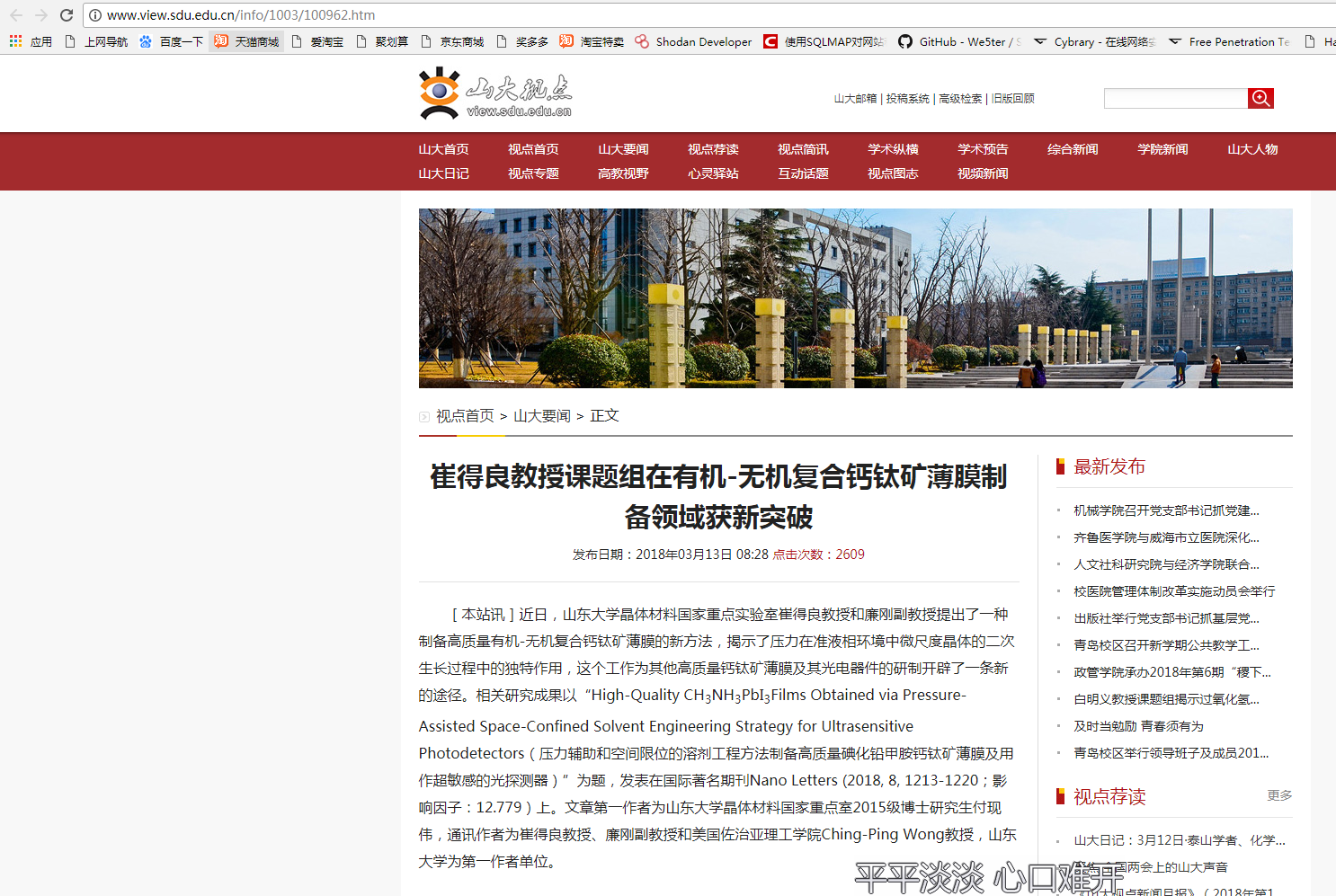
更改后缀最后一个字符

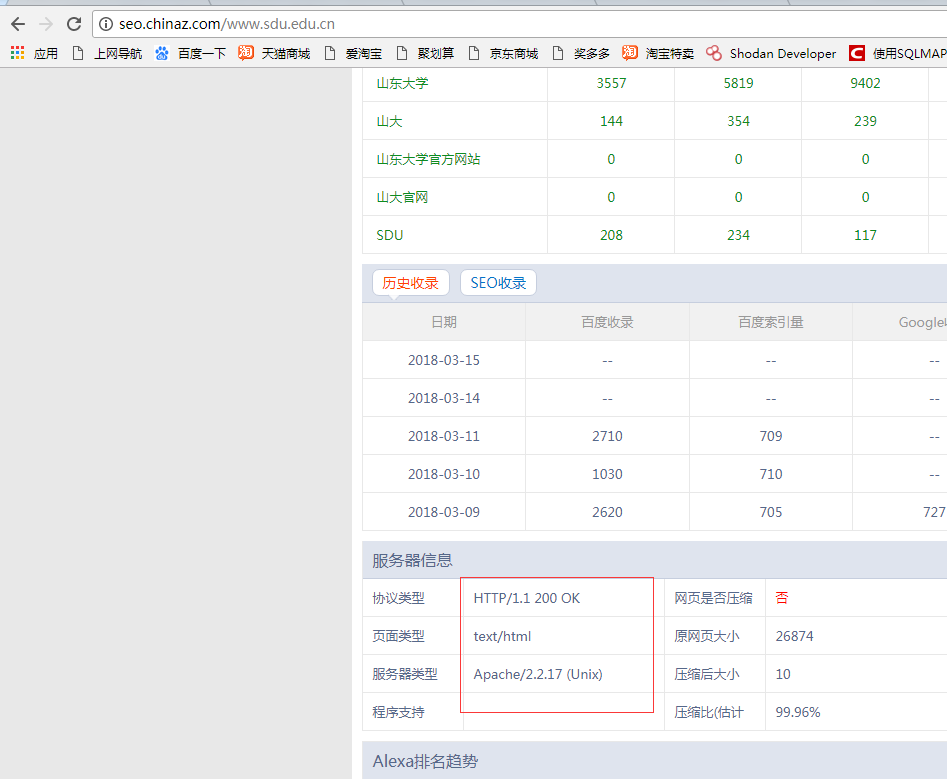
结果:返回的页面不一样,是Linux或者Unix
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
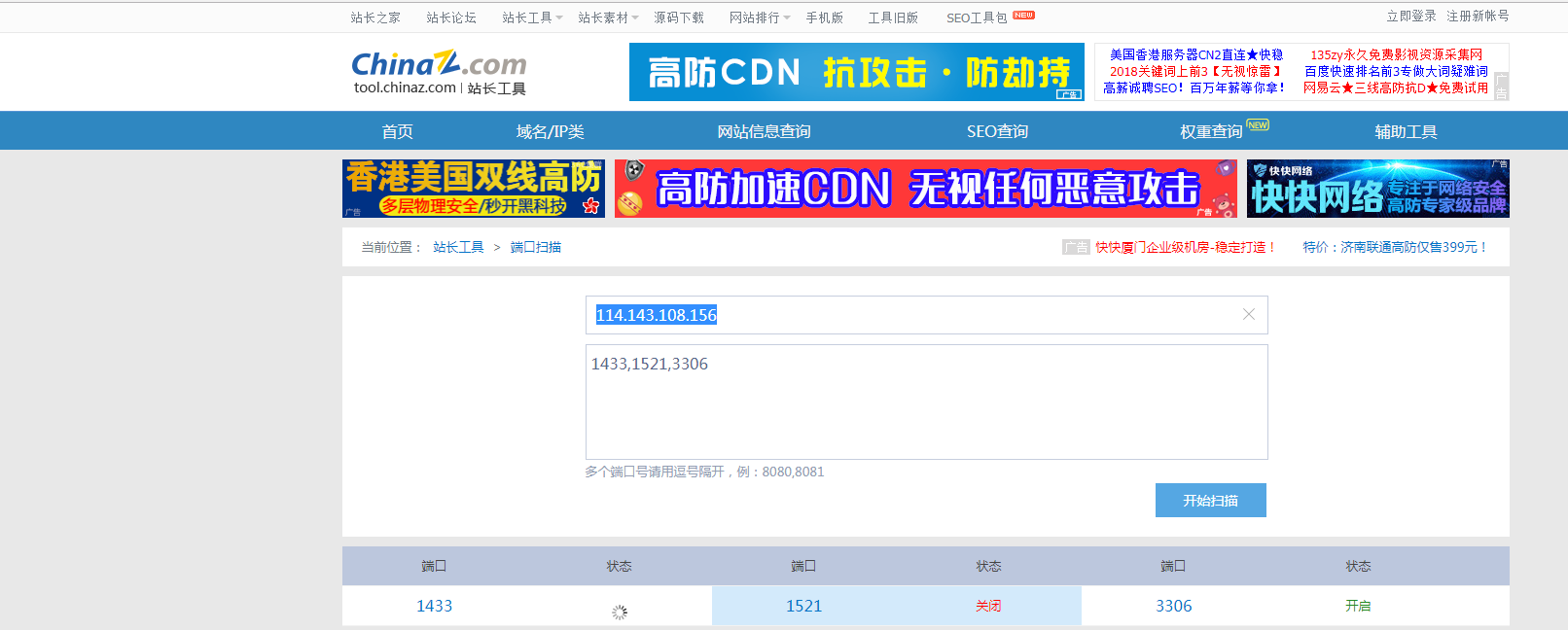
判断数据库类型思路:这里我采用端口判断,如果目标网站改了默认端口或站库分离是识别不出来的,到时候写个SQL注入的判断的脚本。
端口扫描用socket就能实现。
ACCESS:无端口
MYSQL:3306
MSSQL:1433
ORACLE:1521
--------------------------------------------------------------------------------------------------------------------------
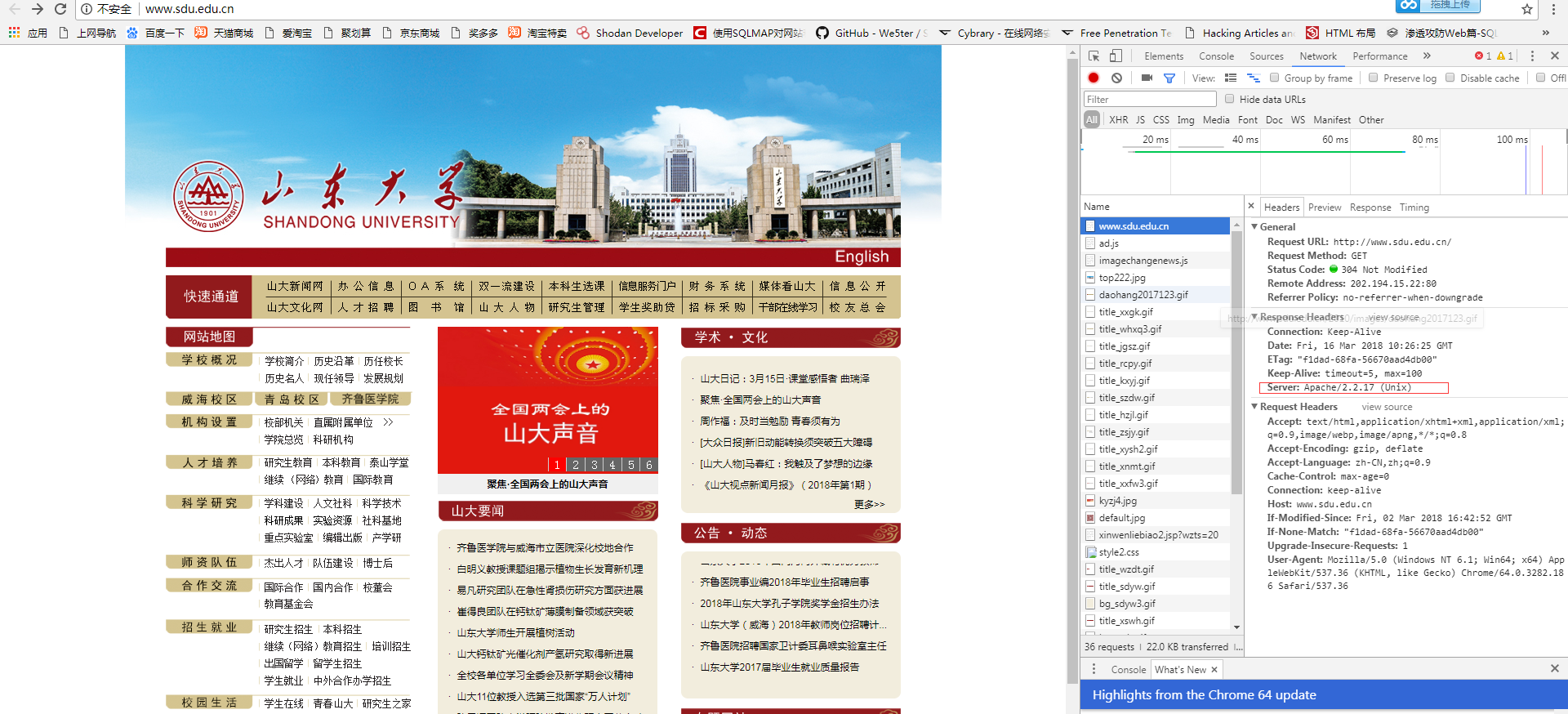
判断服务架构思路:看http响应头就行
0x03代码:
import requests
import os
import socket
import time
import optparse
from bs4 import BeautifulSoup
def main():
usage='-x 判断系统类型' \
'-t 判断数据库类型' \
'-g 判断服务架构' \
'-j 判断网站语言'
parser=optparse.OptionParser(usage)
parser.add_option('-x',dest='system',help='判断系统,判断原理通过目录来判断例:https://www.btime.com/finance')
parser.add_option('-t',dest='database',help='判断数据库,通过端口来判断数据库类型')
parser.add_option('-g',dest='headerss',help='判断架构')
parser.add_option('-j',dest='language',help='判断语言')
(options,args)=parser.parse_args()
if options.system:
system=options.system
SYSTEM(system)
elif options.database:
database=options.database
DATABASE(database)
elif options.language:
language=options.language
LANGUAGE(language)
elif options.headerss:
headerss=options.headerss
HEADERSS(headerss)
else:
parser.print_help()
exit()
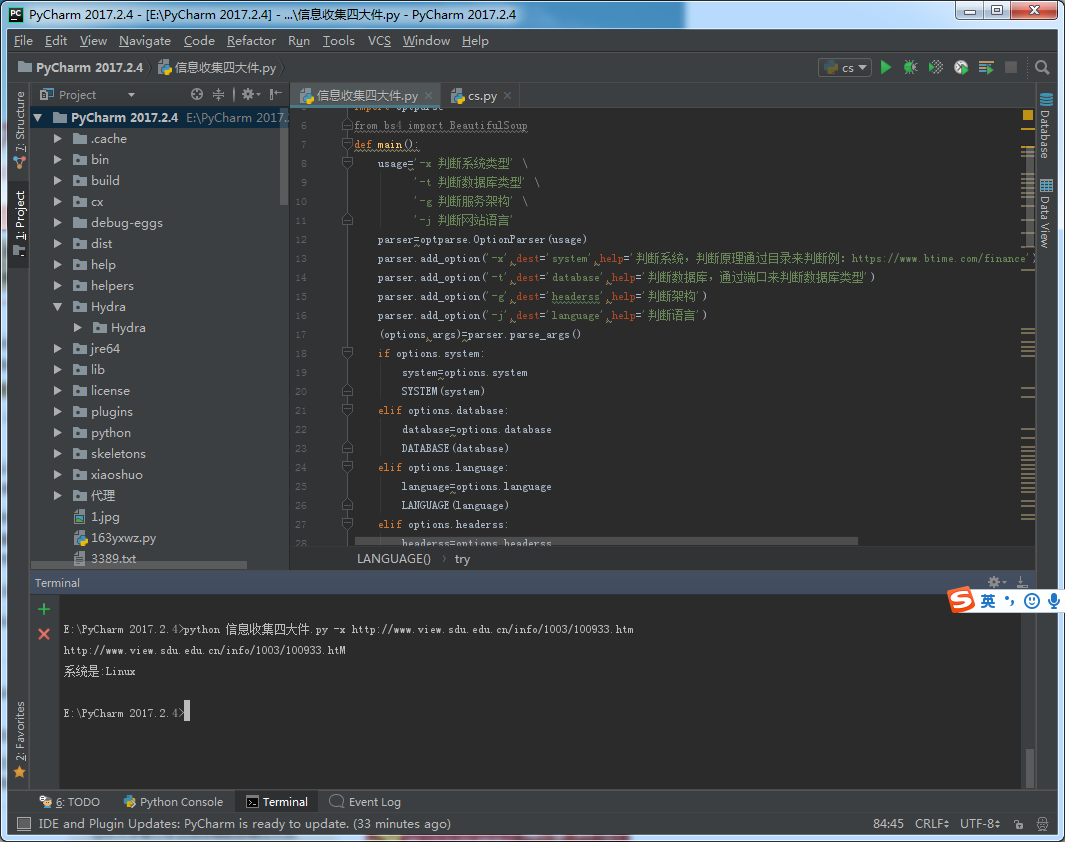
def SYSTEM(system):
sc = "{}".format(system)
gs = sc[-1].capitalize()
sw = sc.strip(sc[-1])
url = sw + gs
sg = requests.get(url)
print(sg.url)
a = requests.get(sc).content
b = requests.get(url).content
if a != b:
print('系统是:Linux')
else:
print('系统是:windows')
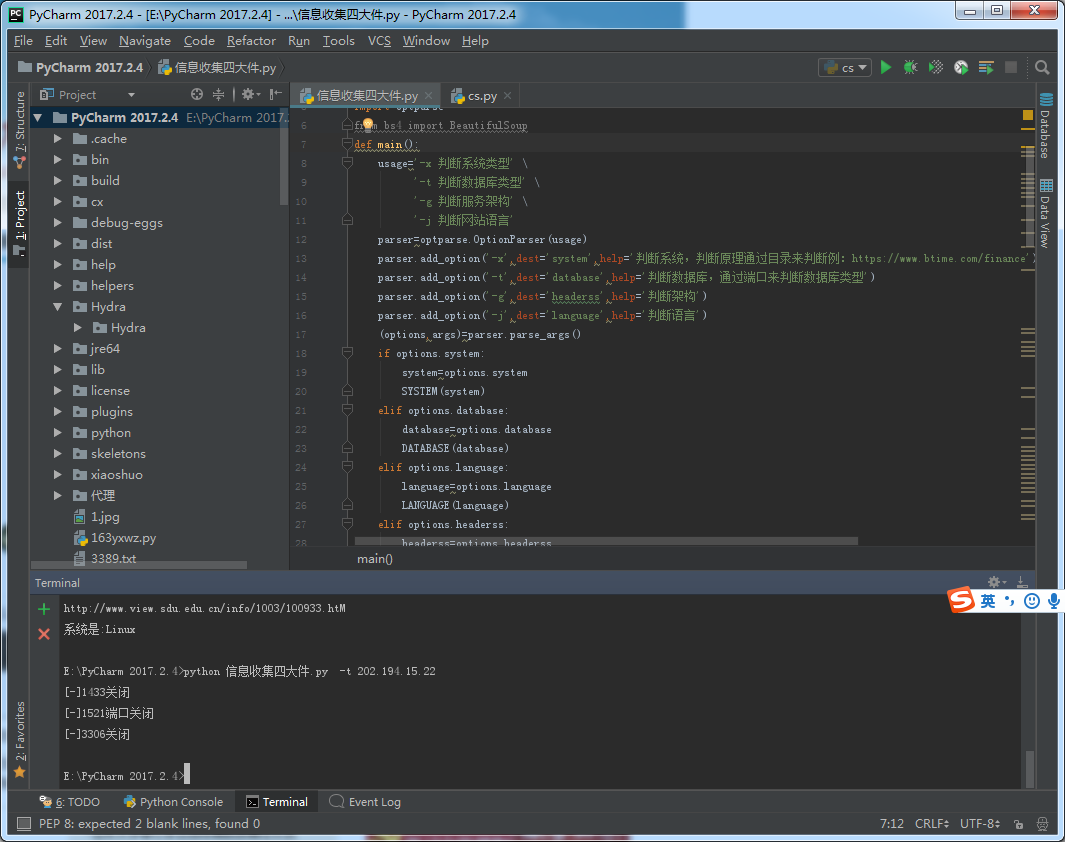
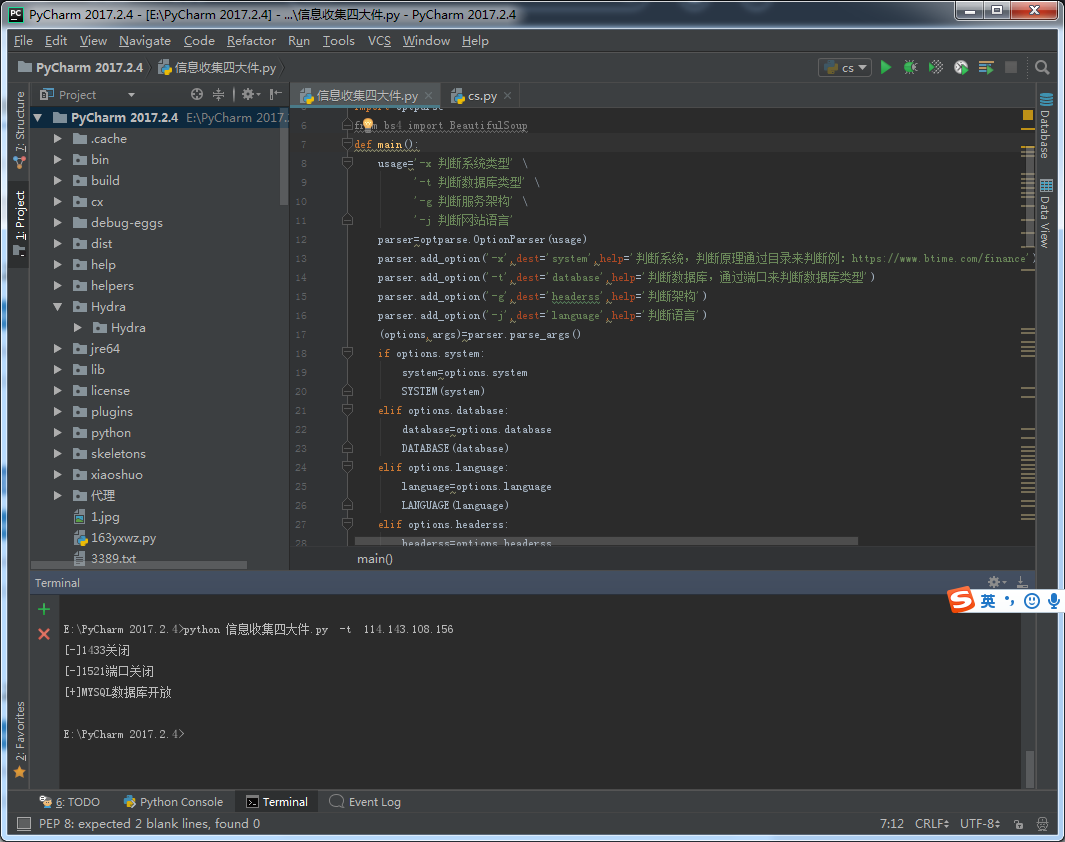
def DATABASE(database):
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
s.settimeout(3)
s.connect((database,1433))
print('[+]MSSQL数据库开放')
except:
print('[-]1433关闭') time.sleep(0.1) try:
s.settimeout(3)
s.connect((database,1521))
print('[+]oracle数据库开放')
except:
print('[-]1521端口关闭') time.sleep(0.1) try:
s.settimeout(3)
s.connect((database,3306))
print('[+]MYSQL数据库开放')
except:
print('[-]3306关闭')
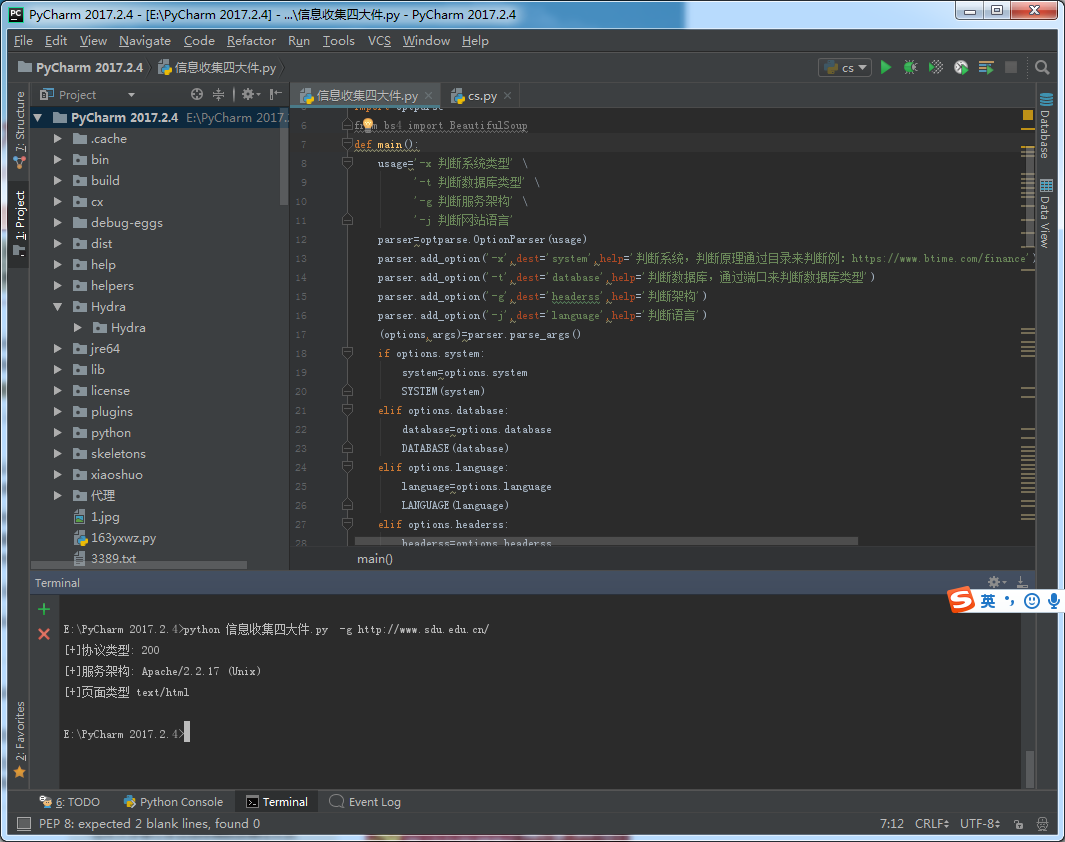
def HEADERSS(headerss):
url="{}".format(headerss)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
r=requests.get(url,headers=headers)
print('[+]协议类型:',url[0],url[1],url[2],url[3],'/',r.status_code)
print('[+]服务架构:',r.headers['Server'])
print('[+]页面类型',r.headers['Content-Type'])
def LANGUAGE(language):
url="{}".format(language)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
g=requests.get(url,headers=headers)
try:
print('[+]程序支持',g.headers['X-Powered-By'])
except:
print('[-]没有找出该网站的程序支持')
if __name__ == '__main__':
main()
脚本运行:
python写一个信息收集四大件的脚本的更多相关文章
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- [py]python写一个通讯录step by step V3.0
python写一个通讯录step by step V3.0 参考: http://blog.51cto.com/lovelace/1631831 更新功能: 数据库进行数据存入和读取操作 字典配合函数 ...
- 【Python】如何基于Python写一个TCP反向连接后门
首发安全客 如何基于Python写一个TCP反向连接后门 https://www.anquanke.com/post/id/92401 0x0 介绍 在Linux系统做未授权测试,我们须准备一个安全的 ...
- 十行代码--用python写一个USB病毒 (知乎 DeepWeaver)
昨天在上厕所的时候突发奇想,当你把usb插进去的时候,能不能自动执行usb上的程序.查了一下,发现只有windows上可以,具体的大家也可以搜索(搜索关键词usb autorun)到.但是,如果我想, ...
- Python写一个自动点餐程序
Python写一个自动点餐程序 为什么要写这个 公司现在用meican作为点餐渠道,每天规定的时间是早7:00-9:40点餐,有时候我经常容易忘记,或者是在地铁/公交上没办法点餐,所以总是没饭吃,只有 ...
- 用python写一个自动化盲注脚本
前言 当我们进行SQL注入攻击时,当发现无法进行union注入或者报错等注入,那么,就需要考虑盲注了,当我们进行盲注时,需要通过页面的反馈(布尔盲注)或者相应时间(时间盲注),来一个字符一个字符的进行 ...
- python写一个能变身电光耗子的贪吃蛇
python写一个不同的贪吃蛇 写这篇文章是因为最近课太多,没有精力去挖洞,记录一下学习中的收获,python那么好玩就写一个大一没有完成的贪吃蛇(主要还是跟课程有关o(╥﹏╥)o,课太多好烦) 第一 ...
- 用python写一个非常简单的QQ轰炸机
闲的没事,就想写一个QQ轰炸机,按照我最初的想法,这程序要根据我输入的QQ号进行轰炸,网上搜了一下,发现网上的案列略复杂,就想着自己写一个算了.. 思路:所谓轰炸机,就是给某个人发很多信息,一直刷屏, ...
- python写一个双色球彩票计算器
首先声明,赌博一定不是什么好事,也完全没有意义,不要指望用彩票发财.之所以写这个,其实是用来练手的,可以参考这个来预测一些其他的东西,意在抛砖引玉. 啰嗦完了,马上开始,先上伪代码 打开网址 读取内容 ...
随机推荐
- IM开发基础知识补课:正确理解前置HTTP SSO单点登陆接口的原理
1.前言 一个安全的信息系统,合法身份检查是必须环节.尤其IM这种以“人”为中心的社交体系,身份认证更是必不可少. 一些PC时代小型IM系统中,身份认证可能直接做到长连接中(也就是整个IM系统都是以长 ...
- Springmvc 中org.springframework.http.converter.json.MappingJackson2HttpMessageConverter依赖jackson包
1,问题详情:Spring使用4.3.5.Release版本后 在SpringMvc配置文件中配置json 解析器后出现报错信息 [org.springframework.web.context.Co ...
- Js比较对Object类型进行排序
<script> var data=[{name:"121",age:"18",year:"2018"},{name:" ...
- Mysql根据指定字段的int值查出在当前列表的排名
先看表结构和数据: DROP TABLE IF EXISTS `ndb_record`; CREATE TABLE `ndb_record` ( `id` bigint(20) NOT NULL AU ...
- HttpClient读取数据乱码的解决方案
博主是一个近十年的老书虫了,从高中那会儿就开始看网络小说.每天半天看晚上看啊,终于眼睛也近视了,成绩也下降了(....好像说远了) 最近在追辰东的<圣墟>,最近写到精彩部分了,一直等更新. ...
- 10分钟入门spark
Spark是硅谷各大公司都在使用的当红炸子鸡,而且有愈来愈热的趋势,所以大家很有必要了解学习这门技术.本文其实是笔者深入浅出hadoop系列的第三篇,标题里把hadoop去掉了因为spark可以不依赖 ...
- WEB开发-动态验证码
1.基于Python实现,用到了django后台处理,刷新验证码功能,其他语言大同小异 2.登录界面 login.html <!DOCTYPE html> <html lang=&q ...
- Redis持久化存储
Redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化.redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式:二是Appen ...
- Jpa中设置OneToMany插入报异常解决办法
在Jpa中如果设置@OneToMany,但使用的时候,如果没有赋值,会报异常出现,这时只需要实例化一个空数组即可, 但类型一定要对应: 实例如下: newField.setxxxxxList(new ...
- 在U-boot中添加以太网驱动
当定义CONFIG_CMD_NET和CONFIG_CMD_PING,编译之后执行ping命令,告警没有找到以太网. 因此,需要打开U-boot的网络功能, u-boot-sunxi-sunxi中没有找 ...