一些排序 (python实现)
►快速排序 <时间复杂度O(n㏒n)>
def partition(li,left,right):
tmp = li[left]
while left < right:
while left<right and li[right]>=tmp: #从最右面开始找比tmp小的数
right -= 1
li[left] = li[right] #把右边的值写到左边空位上
while left<right and li[left]<=tmp:
left += 1
li[right] = li[left] #把右边的值写到左边空位上
li[left] = tmp #把tmp归为
return left #这个是分成两部分的值的下标 def quick_sort(li,left,right):
if left < right:
mid = partition(li,left,right)
quick_sort(li,left,mid-1)
quick_sort(li,mid+1,right)
►堆排序 <时间复杂度O(n㏒n)> (不用递归)
def sift(li,low,high):
i = low #i最开始指向根节点
j = 2*i+1 #把堆顶存起来
tmp = li[low]
while j<=high:#只要j位置有数
if j+1 <= high and li[j+1] > li[j]: #如果右孩子有并且比较大
j = j+1 #j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j #往下看一层
j = 2*i+1
else: #tmp更大,把tmp放到i的位置上
# li[i] = tmp #把tmp放到某一级领导位置上
break
li[i] = tmp #把tmp放到叶子节点上 此i已经2*i+1了 def head_sort(li):
n = len(li)
for i in range((n-2)//2,-1,-1):
# i表示建堆的时候调整的部分的根的下标
sift(li,i,n-1)
#建堆完成了
for i in range(n-1,-1,-1):
#i 指向当前堆的最后一个元素
li[0],li[i] = li[i],li[0]
sift(li,0,i-1)#i-1是新的high
►归并排序 <时间复杂度O(n㏒n)>
def merge(li,low,mid,high):
i = low
j = mid+1
ltmp = []
while i<=mid and j<=high: #只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i+=1
else:
ltmp.append(li[j])
j+=1
while i <= mid:
ltmp.append(li[i])
i+=1
while j <= high:
ltmp.append(li[j])
j+=1
li[low:high+1] = ltmp def merge_sort(li,low,high):
if low < high:
mid = (low+high)//2
merge_sort(li,low,mid) #把左边排好序
merge_sort(li,mid+1,high) #把右边排好序
merge(li,low,mid,high)
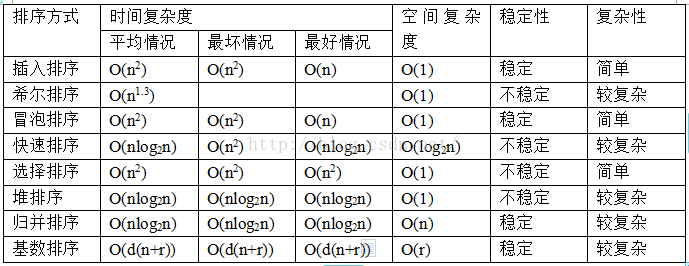
优劣顺序:快速排序 > 归并排序 > 堆排序
其他一些low逼
►冒泡排序 <时间复杂度O(n²)>
def bubble_sort(li):
for i in range(len(li)-1): #i=趟数
exchange = False
for j in range(len(li)-i-1): #无序区
if li[j] < li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
exchange = True
if not exchange:
return
►选择排序 <时间复杂度O(n²)> 新建列表,内存占用×2
def select_sort_simple(li):
li_new = []
for i in range(len(li)):
min_val = min(li)
li_new.append(min_val)
li.remove(min_val) # O(n)操作,删除之后列表元素需要挪位
return li_new
►插入排序 <时间复杂度O(n²)>
def insert_sort(li):
for i in range(1,len(li)):
tmp = li[i]
j = i-1 #最后一张牌的下标
while j >= 0 and li[j] > tmp:
li[j+1] = li[j]
j -= 1
li[j+1] = tmp
►希尔排序
►计数排序 <时间复杂度O(n)>
def count_sort(li,max_count=100):
count = [0 for _ in range(max_count+1)]
for val in li:
count[val] += 1
li.clear()
for index,val in enumerate(count):
for i in range(val):
li.append(index)
►桶排序
►基数排序
一些排序 (python实现)的更多相关文章
- 选择排序-Python与PHP实现版
选择排序Python实现 import random # 生成待排序数组 a=[random.randint(1,999) for x in range(0,36)] # 选择排序 def selec ...
- 计数排序与桶排序python实现
计数排序与桶排序python实现 计数排序 计数排序原理: 找到给定序列的最小值与最大值 创建一个长度为最大值-最小值+1的数组,初始化都为0 然后遍历原序列,并为数组中索引为当前值-最小值的值+1 ...
- python内置数据类型-字典和列表的排序 python BIT sort——dict and list
python中字典按键或键值排序(我转!) 一.字典排序 在程序中使用字典进行数据信息统计时,由于字典是无序的所以打印字典时内容也是无序的.因此,为了使统计得到的结果更方便查看需要进行排序. Py ...
- 选择排序——Python实现
选择排序: 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小( ...
- 希尔排序——Python实现
一.排序思想 希尔排序思想请参见:https://www.cnblogs.com/luomeng/p/10592830.html 二.python实现 def shellSort(arr): &quo ...
- 计数排序、桶排序python实现
计数排序在输入n个0到k之间的整数时,时间复杂度最好情况下为O(n+k),最坏情况下为O(n+k),平均情况为O(n+k),空间复杂度为O(n+k),计数排序是稳定的排序. 桶排序在输入N个数据有M个 ...
- 经典排序 python实现
稳定的排序算法:冒泡排序.插入排序.归并排序和基数排序. 不是稳定的排序算法:选择排序.快速排序.希尔排序.堆排序. 冒泡 def bobble(arr): length = len(arr) for ...
- 选择排序python实现
选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完.注意每次查找 ...
- 希尔排序--python
import random import time # 插入排序 def insertion_sort(arr, step): for i in range(step, len(arr)): for ...
随机推荐
- Linux ls命令详解-乾颐堂CCIE
ls命令用法举例: 例一:列出/home文件夹下的所有文件和目录的详细资料: 1 ls -l -R /home 命令参数之前要有一短横线“-”, 上面的命令也可以这样写: 1 ls -lR /ho ...
- scp 的时候提示WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
摘自:https://blog.csdn.net/haokele/article/details/72824847 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ ...
- 样条曲线catmull rom转bezier
b0,..,b3是贝塞尔,c-1, c2是catmull rom控制点 [b0] = 1 [ 0 6 0 0] [c_1] [b1] - [-1 6 1 0] [c0] [b2] 6 [ 0 1 6 ...
- org.springframework.beans.factory.xml.XmlBeanDefinitionReader.loadBeanDefinitions:323) | Loading XML bean definitions from class path resource [
今天遇到一个这样的错误,这个错误是说我的spring的框架的文档没有写正确.但是反复检查,文档没有错误,原因是我使用了自己只做的user library,而且使用了 下边的System library ...
- 浅说Java反射机制
工作中遇到,问题解决: JAVA语言中的反射机制: 在Java 运行时 环境中,对于任意一个类,能否知道这个类有哪些属性和方法? 对于任意一个对象,能否调用他的方法?这些答案是肯定的,这种动态获取类的 ...
- msf、armitage
msfconsole的命令: msfconsole use module :这个命令允许你开始配置所选择的模块. set optionname module :这个命令允许你为指定的模块配置不同的选项 ...
- “undefined reference to JNI_GetCreatedJavaVM”和“File format not recognized”错误原因分析
"undefined reference to JNI_GetCreatedJavaVM"和"File format not recognized"错误原因分析 ...
- 在iOS中使用百度地图
就如同在百度地图的文档中所说的一样,这么来.但是,有一个小疏忽. 到添加完所需要的framework之后,一定要记得把你的(Class-Prefix)AppDelegate的后缀改成mm. 估计百度的 ...
- Python3常见Exception
异常 描述BaseException 新的所有异常类的基类Exception ...
- spring源码研究之IoC容器在web容器中初始化过程
转载自 http://ljbal.iteye.com/blog/497314 前段时间在公司做了一个项目,项目用了spring框架实现,WEB容器是Tomct 5,虽然说把项目做完了,但是一直对spr ...