intellij-idea打包Scala代码在spark中运行
、创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容:
<properties>
<spark.version>2.1.</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
其中保存之后,需要点击下面的import change,这样相当于是下载jar包
二、编写一个Scala程序,统计单词的个数
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object WordCount {
def main(args: Array[String]) {
if (args.length == ) {
System.err.println("Usage: spark.example.WordCount <input> <output>")
System.exit()
} val input_path = args().toString
val output_path = args().toString val conf = new SparkConf().setAppName("WordCount")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc = new SparkContext(conf)
val inputFile = sc.textFile(input_path)
val countResult = inputFile.flatMap(line => line.split(" "))
.map(word => (word, ))
.reduceByKey(_ + _)
.map(x => x._1 + "\t" + x._2)
.saveAsTextFile(output_path)
}
}
三、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
然后填写定义的类名,选择copy to..选项(打包这一个类)

点击ok之后,然后build->build Artifacts->build,等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包

四、运行在spark集群上面
1. 把jar包放到能访问spark集群的机器上面
2. 运行
/usr/local/spark/bin/spark-submit --class WordCount --master spark://master:7077 /data/wangzai/package/WordCount.jar \
hdfs://master:9000/spark/test.data hdfs://master:9000/spark_output/spark_wordcount \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 10
3. 结果

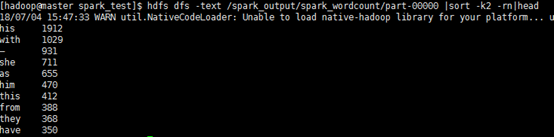
intellij-idea打包Scala代码在spark中运行的更多相关文章
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- IntelliJ IDEA开发Scala代码,与java集成,maven打包编译
今天尝试了一下在IntelliJ IDEA里面写Scala代码,并且做到和Java代码相互调用,折腾了一下把过程记录下来. 首先需要给IntelliJ IDEA安装一下Scala的插件,在IDEA的启 ...
- pycharm中运行成功的python代码在jenkin中运行问题总结
我们在用selenium+python完成了项目的UI自动化后,一般用jekins持续集成工具来定期运行,python程序在pycharm中编辑运行成功,但在jenkins中运行失败的两个问题,整理如 ...
- 使用IDEA打包scala程序并在spark中运行
一.首先配置ssh无秘钥登陆, 先使用这条命令:ssh-keygen,然后敲三下回车: 然后使用cd .ssh进入 .ssh这个隐藏文件夹: 再创建一个文件夹authorized_keys,使用命令t ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- maven 打包Scala代码到jar包
idea的pom.xml文件配置 <dependencies> <dependency> <groupId>org.scala-lang</groupId&g ...
- .NetCore下利用Jenkins如何将程序自动打包发布到Docker容器中运行
说道这一块纠结了我两天时间,感觉真的很心累,Jenkins的安装就不多说了 这里我们最好直接安装到宿主机上,应该pull到的jenkins版本是2.6的,里面很多都不支持,我自己试了在容器中安装的情况 ...
- intellij idea打包出来的jar包,运行时中文乱码
比如以下代码: import javax.swing.*; public class addJarPkg { public static void main(String[] args) { JFra ...
- eclipse将项目打包成jar在linux中运行
最近因为项目需要,做了几个外挂程序做数据传输,涉及到项目打包操作,在此记录一下打包步骤和其中出现的问题. 1.首先右键项目文件夹,点击export,弹出如下选择框,在其中输入jar搜索,并选择JAR ...
随机推荐
- 剑指 offer set 19 翻转单词顺序 && 字符串左旋
题目 1. 翻转单词 student. a am I 转换成 I am a student. 2. 字符串左旋 abba 1 转成 bbaa 总结 1. 先对每个单词旋转, 再整齐旋转 2. 先翻转一 ...
- 第四篇:使用 CUBLAS 库给矩阵运算提速
前言 编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时.那么有没有一些现成的 CUDA 库来调用呢? 答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库. 本文将 ...
- will-change
目的: 让GPU分担CPU的工作,从而优化和分配内存,告知浏览器做好动画的准备. 背景: 注意事项: 1,will-change虽然可以加速,但是,一定一定要适度使用: 2,使用伪元素,独立渲染: 不 ...
- HYSBZ 2243(染色)
题目链接:传送门 题目大意:中文题,略 题目思路:树链剖分,区间更新,区间查询. 闲谈: 只想说这道题做的好苦逼..去长春现场赛之前就没A,回来后又做了2天才A掉,蒟蒻太菜了 这道题也没有想 ...
- 【BZOJ2973】石头游戏 矩阵乘法
[BZOJ2973]石头游戏 Description 石头游戏的规则是这样的. 石头游戏在一个n行m列的方格阵上进行.每个格子对应了一个编号在0~9之间的操作序列. 操作序列是一个长度不超过6且循环执 ...
- Node.js 搭建Web
Express Express 是整个 Node.js 之中最为常见的一个框架(开发包),可以帮助我们快速构建一个WEB项目.(http://expressjs.com) 1.在 F 盘新建 node ...
- Spring Security OAuth2 源码分析
Spring Security OAuth2 主要两部分功能:1.生成token,2.验证token,最大概的流程进行了一次梳理 1.Server端生成token (post /oauth/token ...
- 170328、Maven+SpringMVC+Dubbo 简单的入门demo配置
之前一直听说dubbo,是一个很厉害的分布式服务框架,而且巴巴将其开源,这对于咱们广大程序猿来说,真是一个好消息.最近有时间了,打算做一个demo把dubbo在本地跑起来先. 先copy一段dubbo ...
- python2--升级python3
先安装开发工具包: yum -y group install "Development Tools" 安装Python的依赖包: yum -y install openssl-de ...
- FW:主流RPC框架
主流RPC框架 2015年10月27日 zman RPC 介绍目前在互联网公司比较流行的开源的RPC框架. RPC框架比较 语言 协议 服务治理 社区 机构 Hessian 多语言 he ...