使用IDEA打包scala程序并在spark中运行
一、首先配置ssh无秘钥登陆,
先使用这条命令:ssh-keygen,然后敲三下回车;
然后使用cd .ssh进入 .ssh这个隐藏文件夹;
再创建一个文件夹authorized_keys,使用命令touch authorized_keys;
然后使用cat id_rsa.pub > authorized_keys 即可;
最后使用 chmod 600 authorized_keys修改权限就完成了。
二、创建spark项目
idea创建spark项目的过程这里就略过了,具体可以看这里https://www.cnblogs.com/xxbbtt/p/8143441.html
三、在pom.xml加入相关的依赖包
在pom.xml文件中添加:
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
然后等待就好了。。。
四、编写一个示范程序
创建一个scala类,并写以下代码,也可以是其他的,这里只是测试而已
object first {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount")
val sc = new SparkContext(conf)
val input = sc.textFile("/home/cjj/testfile/helloSpark.txt")
val lines = input.flatMap(line => line.split(" "))
val count = lines.map(word => (word, 1)).reduceByKey { case (x, y) => x + y }
val output = count.saveAsTextFile("/home/cjj/testfile/helloSparkRes")
}
}
这里使用了Spark实现的功能是,计算helloSpark.txt这个文件各个单词出现的次数,并保存在helloSparkRes文件夹中。
五、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
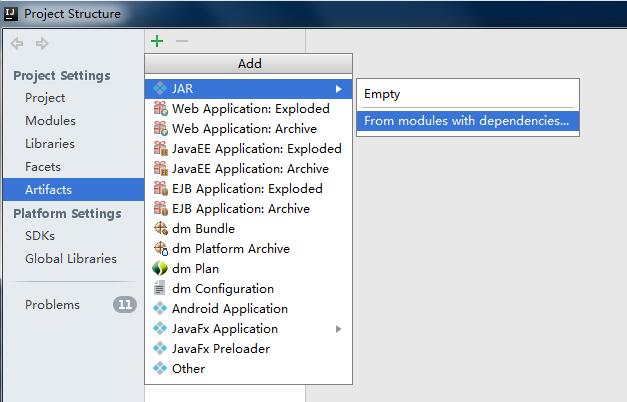
跳出以下对话框,选择要打包的类,然后选择copy to.....选项,这里的意思是只打包这一个类。
然后点击ok,然后ok。然后build->build Artifacts
再然后点击build
等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包
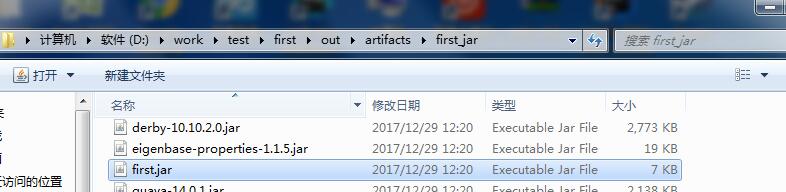
这里的first的我的项目名。
六、启动集群
先将刚才打包的jar包复制到虚拟机中,
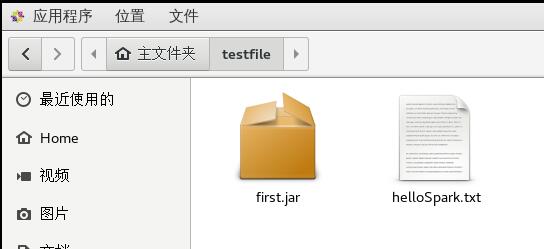
helloSpark.txt是我将要操作的文件。接着就是启动集群,分为三步
- 启动master ./sbin/start-master.sh
- 启动worker ./bin/spark-class
- 提交作业 ./bin/spark-submit
首先进入spark-2.2.1-bin-hadoop2.7文件夹,然后运行命令./sbin/start-master.sh
然后可以打开浏览器,进入localhost:8080,可以看到
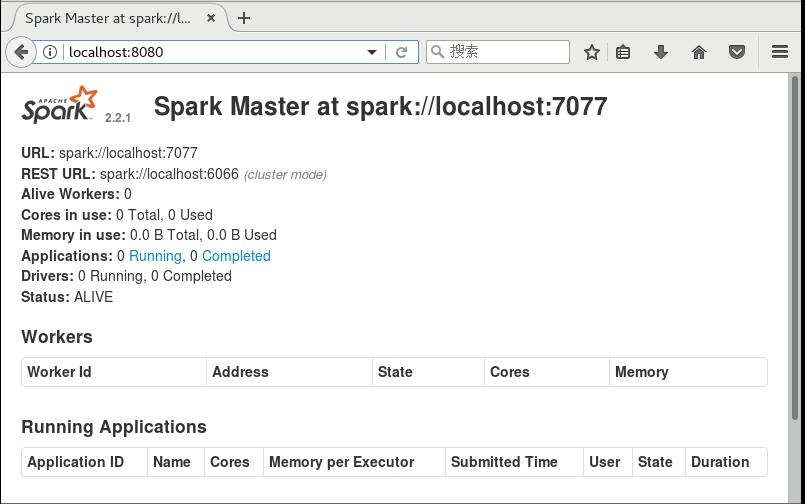
这里的URL spark://localhost:7077需要记下来下一步需要使用,下一步启动work,加上刚刚的URL,可以使用的命令是,
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
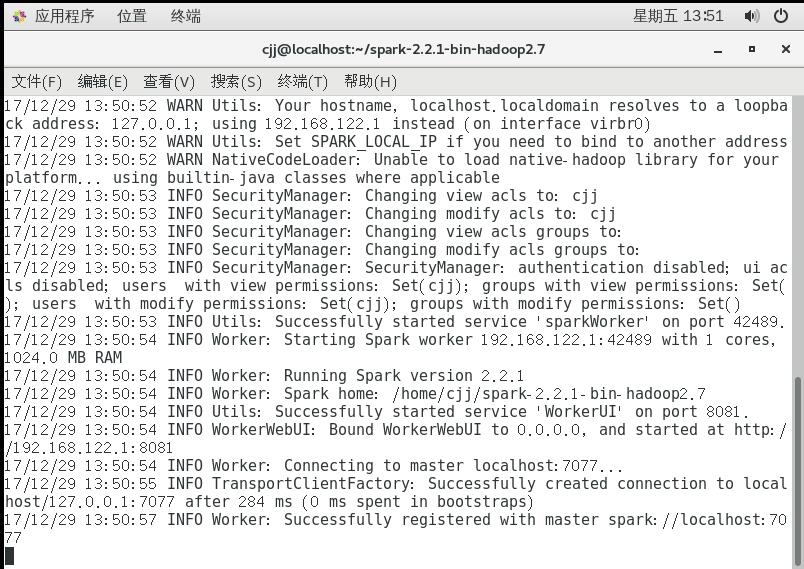
这时启动另一个窗口进行提交作业,同样需要先进入spark文件夹,然后运行命令
./bin/spark-submit --master spark://localhost:7077 --class first /home/cjj/testfile/first.jar
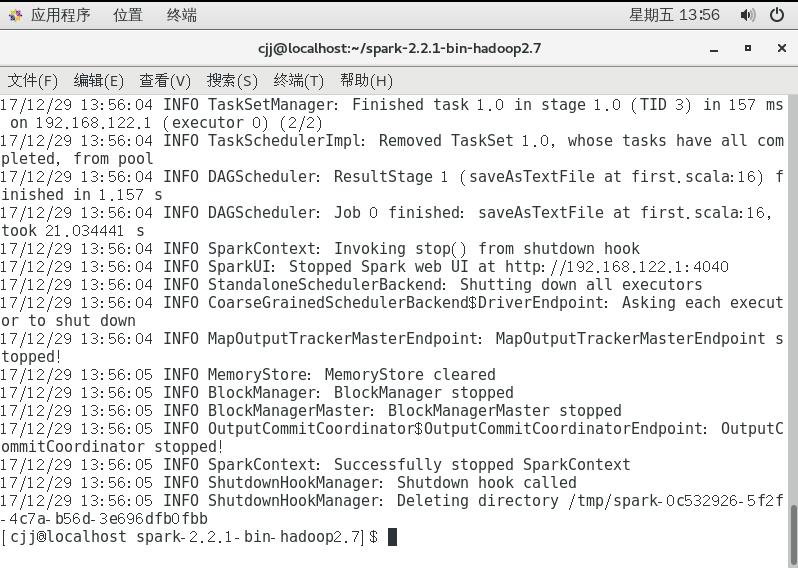
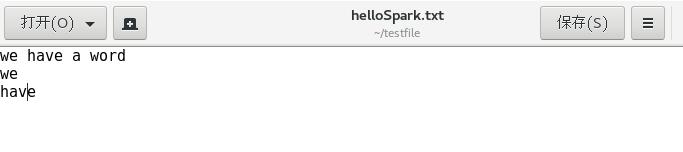
这样就算完成了,我们可以来看看结果,看结果之前需要先看一看helloSpark.txt的内容
结果保存在helloSparkRes中,下面是结果
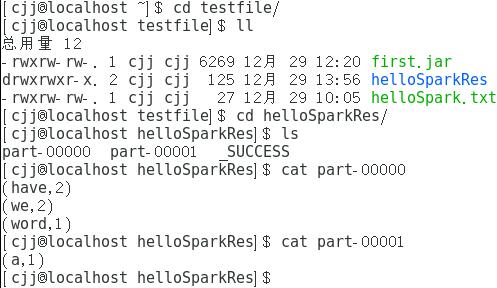
这里的结果告诉我们have和word的个数为2,word和a的个数为1。
使用IDEA打包scala程序并在spark中运行的更多相关文章
- docker 运行jenkins及vue项目与springboot项目(五.jenkins打包springboot服务且在docker中运行)
docker 运行jenkins及vue项目与springboot项目: 一.安装docker 二.docker运行jenkins为自动打包运行做准备 三.jenkins的使用及自动打包vue项目 四 ...
- intellij-idea打包Scala代码在spark中运行
.创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容: <properties> <spark.version></spar ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- 判断Java程序是否在jar中运行
URL url = TextRenderer.class.getResource(""); String protocol = url.getProtocol(); boolean ...
- 关于python程序在VS code中运行时提示文件无法找到的报错
经过测试,在设置文件夹目录时,可以找到当前目录下的htm文件,采用with open()语句可以正常执行程序,如下图. 而当未设置当前目录,直接用vscode执行该程序时,就会报错文件无法找到File ...
- C编译器MinGW安装、下载及在notepad++中运行C程序
一.C编译器MinGW的下载及安装步骤 打开MinGW官网:http://www.mingw.org/ 图一 图二 图三 图四 图五 图六 系统中配置环境变量: 图七 验证是否安装成功: CMD中运行 ...
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
随机推荐
- SpringBoot 的过滤器
在Springboot里面读封装的一些常用的API,当然对过滤器也不类外了. 首先讲下Spring中的AOP的理解: AOP不是一种具体的技术,而是一种编程思想.在面向对象编程的过程中,我们很容易通过 ...
- pod update更新error: RPC failed; curl 18 transfer closed with outstanding read data remaining
1. pod update 的时候出现下边的错误 error: RPC failed; curl 18 transfer closed with outstanding read data remai ...
- orm的操作
ORM的对应关系 类 —— > 表 对象 ——> 记录(数据行) 属性 ——> 字段 class Book(model.Model): title=models.Char ...
- Oracle修改字段类型报错:“ORA-01439:要更改数据类型,则要修改的列必须为空”
在oracle修改user表字段name类型时遇到报错:“ORA-01439:要更改数据类型,则要修改的列必须为空”,是因为要修改字段的新类型和原来的类型不兼容. 如果要修改的字段数据为空时,则不会报 ...
- 剑指offer第二版-8.二叉树的下一个节点
描述:给定一棵二叉树和其中的一个节点,找出中序遍历序列的下一个节点.树中应定义指向左节点.右节点.父节点的三个变量. 思路: 1.如果输入的当前节点有右孩子,则它的下一个节点即为该右孩子为根节点的子树 ...
- 详细记录登录过程的用户、IP地址、shell命令以及详细操作时间
将下面的代码添加到/etc/profile #history USER_IP=`>/dev/null|awk '{print $NF}'|sed -e 's/[()]//g'` HISTDIR= ...
- Ray-基础部分目录
基础部分: 引言 Actor编写-ESGrain与ESRepGrain 消息发布器与消息存储器 Event编写 Handler之CoreHandler编写 Handler之ToReadHandler编 ...
- mysql -h139.129.205.80 -p test_db_dzpk < db.dump
mysqldump -h139.129.205.80 -uroot -p db_a > db_dzpk.dump mysql -h139.129.205.80 -p test_db< db ...
- blog更新
特别感谢: yu__xuan (啊这位着重感谢,多次帮助,于是帮他宣传一下https://www.cnblogs.com/poi-bolg-poi/) widerg 为两位大佬撒花~
- [PTA] 数据结构与算法题目集 6-2 顺序表操作集
//创建并返回一个空的线性表: List MakeEmpty() { List L; L = (List)malloc(sizeof(struct LNode)); L->Last = -1; ...