intellij-idea打包Scala代码在spark中运行
、创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容:
<properties>
<spark.version>2.1.</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
其中保存之后,需要点击下面的import change,这样相当于是下载jar包
二、编写一个Scala程序,统计单词的个数
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object WordCount {
def main(args: Array[String]) {
if (args.length == ) {
System.err.println("Usage: spark.example.WordCount <input> <output>")
System.exit()
} val input_path = args().toString
val output_path = args().toString val conf = new SparkConf().setAppName("WordCount")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc = new SparkContext(conf)
val inputFile = sc.textFile(input_path)
val countResult = inputFile.flatMap(line => line.split(" "))
.map(word => (word, ))
.reduceByKey(_ + _)
.map(x => x._1 + "\t" + x._2)
.saveAsTextFile(output_path)
}
}
三、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
然后填写定义的类名,选择copy to..选项(打包这一个类)

点击ok之后,然后build->build Artifacts->build,等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包

四、运行在spark集群上面
1. 把jar包放到能访问spark集群的机器上面
2. 运行
/usr/local/spark/bin/spark-submit --class WordCount --master spark://master:7077 /data/wangzai/package/WordCount.jar \
hdfs://master:9000/spark/test.data hdfs://master:9000/spark_output/spark_wordcount \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 10
3. 结果

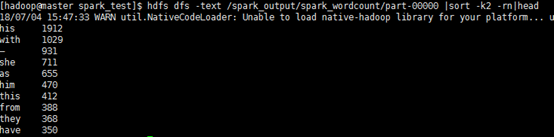
intellij-idea打包Scala代码在spark中运行的更多相关文章
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- IntelliJ IDEA开发Scala代码,与java集成,maven打包编译
今天尝试了一下在IntelliJ IDEA里面写Scala代码,并且做到和Java代码相互调用,折腾了一下把过程记录下来. 首先需要给IntelliJ IDEA安装一下Scala的插件,在IDEA的启 ...
- pycharm中运行成功的python代码在jenkin中运行问题总结
我们在用selenium+python完成了项目的UI自动化后,一般用jekins持续集成工具来定期运行,python程序在pycharm中编辑运行成功,但在jenkins中运行失败的两个问题,整理如 ...
- 使用IDEA打包scala程序并在spark中运行
一.首先配置ssh无秘钥登陆, 先使用这条命令:ssh-keygen,然后敲三下回车: 然后使用cd .ssh进入 .ssh这个隐藏文件夹: 再创建一个文件夹authorized_keys,使用命令t ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- maven 打包Scala代码到jar包
idea的pom.xml文件配置 <dependencies> <dependency> <groupId>org.scala-lang</groupId&g ...
- .NetCore下利用Jenkins如何将程序自动打包发布到Docker容器中运行
说道这一块纠结了我两天时间,感觉真的很心累,Jenkins的安装就不多说了 这里我们最好直接安装到宿主机上,应该pull到的jenkins版本是2.6的,里面很多都不支持,我自己试了在容器中安装的情况 ...
- intellij idea打包出来的jar包,运行时中文乱码
比如以下代码: import javax.swing.*; public class addJarPkg { public static void main(String[] args) { JFra ...
- eclipse将项目打包成jar在linux中运行
最近因为项目需要,做了几个外挂程序做数据传输,涉及到项目打包操作,在此记录一下打包步骤和其中出现的问题. 1.首先右键项目文件夹,点击export,弹出如下选择框,在其中输入jar搜索,并选择JAR ...
随机推荐
- MyEclipse------如何添加jspsmartupload.jar,用于文件上传
方法: 右键“Web”工程->properties->Libraries->Add External JARs...->找到“jspsmartupload.jar”,添加进去 ...
- java并发容器(Map、List、BlockingQueue)具体解释
Java库本身就有多种线程安全的容器和同步工具,当中同步容器包含两部分:一个是Vector和Hashtable.另外还有JDK1.2中增加的同步包装类.这些类都是由Collections.synchr ...
- iOS开发之--svn工具Cornerstone上传忽略.a文件的处理方法
工程文件上传到svn中,.a文件会自动屏蔽(应该叫屏蔽,反正就是上传不上去) 用Cornerstone工具,解决这个问题 1.打开Cornerstone左上角,点Cornerstone->Pre ...
- Android Fragment Base
public class FragmentTabsActivity extends FragmentActivity implements OnClickListener { //定义Fragment ...
- 厚积薄发系列之JDBC详解
创建一个以JDBC链接数据库的程序,包含七个步骤 1.加载JDBC驱动 加载要连接的数据库的驱动到JVM 如何加载?forName(数据库驱动) MySQL:Class.forName("c ...
- 一百本英文原著之旅 ( 15 finished )
记得去年毕业的时候,突然想看英文原著(小说.文学.技术 etc.)来提高自己的英文水平.并且那时候愣愣的有了个宏伟的目标 --> 一百本. 不过也就去年下半年断断续续的看了些页数在200左右的 ...
- HBase-MR
一.需求1:对一张表的rowkey进行计数 官方HBase-Mapreduce 需求1:对一张表的rowkey进行计数 1)导入环境变量 export HBASE_HOME=/root/hd/hbas ...
- Django REST framework 理解
Web应用模式 1 .前后端不分离:在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示,前端与厚度那的耦合度很高. 这种应用模式比较 ...
- Python多线程、多进程和协程的实例讲解
线程.进程和协程是什么 线程.进程和协程的详细概念解释和原理剖析不是本文的重点,本文重点讲述在Python中怎样实际使用这三种东西 参考: 进程.线程.协程之概念理解 进程(Process)是计算机中 ...
- python爬虫防止IP被封的一些措施
在编写爬虫爬取数据的时候,因为很多网站都有反爬虫措施,所以很容易被封IP,就不能继续爬了.在爬取大数据量的数据时更是瑟瑟发抖,时刻担心着下一秒IP可能就被封了. 本文就如何解决这个问题总结出一些应对措 ...