使用scrapy爬取金庸小说目录和章节url
刚接触使用scrapy的时候,如果一开始就想实现特别复杂的配置,显然是不太现实的,用一些小的例子可以帮助自己理解各个模块。
今天的目标:爬取http://www.luoxia.com/shendiao/ 网站金庸小说神雕侠侣目录及各章节链接,并且保存到mongoDB数据库
分析:使用scrapy不做任何处理,实际上就可以得到原网页,但是我需要得到的目录名字和名录的url地址,所以需要对response进行解析(在spiders模块完成),
然后我需要保存到数据库,需要在itempipeline里面完成。(各模块功能可参见:上一篇文章)
开始编写代码前需要先生成项目爬虫
1、首先通过scrapy startproject shendiaoSpider命令,创建一个项目shendiaoSpider,但是这个时候项目只是一个空壳,还需要生成一个爬虫
2、通过cd shendiaoSpider命令进入目标文件夹,然后通过scrapy genspider shendiao www.luoxia.com/shendiao 生成一个爬虫,爬虫名叫shendiao
正式开始编写代码,我们需要编写的文件是shendiao.py(用来解析response生成我们需要的item),items.py(定义需要的item字段),pipelines.py(用来存储到数据库),settings.py(配置pipeline以及mongoDB的数据库名和表名):
一、编写items.py,定义两个字段,一个title各章节的标题,一个url各章节的url
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ShendiaospiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
二、编写shendiao.py,这里主要是做一个信息提取,把title字段和章节url字段提取出来
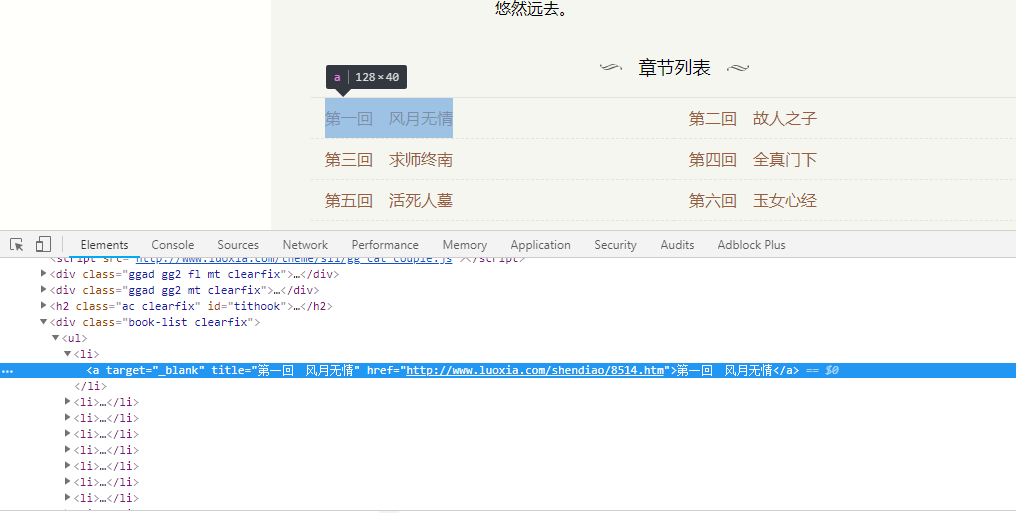
通过对目标网站分析,很容易看出来,所有的章节信息都包含在li标签里的a标签里,我们可以使用css选择器或者xpath进行信息提取,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from shendiaoSpider.items import ShendiaospiderItem class ShendiaoSpider(scrapy.Spider):
name = 'shendiao'
allowed_domains = ['www.luoxia.com/shendiao']
start_urls = ['http://www.luoxia.com/shendiao/'] def parse(self, response):
#对于class属性中有空格的,使用css时需要用.进行连接
book_lists = response.css('.book-list.clearfix li')
for book_list in book_lists:
item = ShendiaospiderItem()
item['title'] = book_list.css('a::text').extract_first()
item['url'] = book_list.css('a::attr(href)').extract_first()
yield item
上面就可以提取出目标字段,保存到item中,如果对于选择器不是很理解,可以看:选择器使用
这个时候在cmd命令行使用scrapy crawl shendiao运行已经可以显示出结果了
三、编写pipelines.py,代码如下:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo #默认的pipeline,只是返回item信息
class ShendiaospiderPipeline(object):
def process_item(self, item, spider):
return item #使用这个Pipeline将数据item保存到mongoDB
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db): #初始化方式定义两个变量,一个是数据库地址,一个是具体数据库database名称
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler): #定义个类方法,使用这个方法找到settings里面MONGO_URI和MONGO_DB设定的值
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri) #创建一个到MongoDB位置的连接
self.db = self.client[self.mongo_db] #连接到数据库 def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item)) #把item信息以字典形式插入到数据库的表中 def close_spider(self, spider):
self.client.close() #关闭到数据库的连接
为了方便理解,上面的代码我写了大量的注释,实际写的代码如果这样搞,估计要被人吐死。
四、编写settings.py文件,代码修改部分如下,应该很容易理解:
ITEM_PIPELINES = {
'shendiaoSpider.pipelines.ShendiaospiderPipeline': 300,
'shendiaoSpider.pipelines.MongoPipeline': 400,
}
MONGO_URI = 'localhost'
MONGO_DB = 'shendiao'
这样再次运行这个爬虫,就可以把数据存入到mongoDB数据库了,最后打开可视化工具看一下。

可以看到这个数据库名字叫shendiao,它下面有个表名字ShendiaospiderItem,信息也被存了进去。
好了,关于使用scrapy下载数据并存入到mongoDB的方法就先到这。
使用scrapy爬取金庸小说目录和章节url的更多相关文章
- python3爬虫爬取金庸小说所有角色
# -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup url = 'http://www.jinyongwang.c ...
- Scrapy爬取小说简单逻辑
Scrapy爬取小说简单逻辑 一 准备工作 1)安装Python 2)安装PIP 3)安装scrapy 4)安装pywin32 5)安装VCForPython27.exe ........... 具体 ...
- 小说免费看!python爬虫框架scrapy 爬取纵横网
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 风,又奈何 PS:如有需要Python学习资料的小伙伴可以加点击下方 ...
- scrapy 爬取纵横网实战
前言 闲来无事就要练练代码,不知道最近爬取什么网站好,就拿纵横网爬取我最喜欢的雪中悍刀行练手吧 准备 python3 scrapy 项目创建: cmd命令行切换到工作目录创建scrapy项目 两条命 ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
随机推荐
- BZOJ4557 JLOI2016侦察守卫(树形dp)
下称放置守卫的点为监控点.设f[i][j]为i子树中深度最大的未被监视点与i的距离不超过j时的最小代价,g[i][j]为i子树中距离i最近的监控点与i的距离不超过j且i子树内点全部被监视时的最小代价. ...
- axios超时重发
axios的超时是在response中处理的,所以要在response中添加拦截器: axios.interceptors.response.use(undefined, function axios ...
- [COGS 622] [NOIP2011] 玛雅游戏 模拟
整个模拟的关键除了打出来就是一个剪枝:对于两个左右相邻的块你不用再走←,因为走→是等效的 #include<cstdio> #include<cstring> #include ...
- nm用法小记
nm用于显示目标文件的符号,也是二进制工具集(info binutils)里的一员 先来看一个例子,源码和对应的命令结果 四部分分别表示的意义 符号所在的obj文件名 符号的值,这里应该是指符号所在段 ...
- 使用XTU降低CPU功耗,自动执行不失效
INTEL出品的XTU可以用来做软超频操作,给CPU/GPU加电压超频,也可以通过降低CPU/GPU电压来减少功耗. 以前用XTU设置好了之后,过一段时间就自动失效了,最近失效的频率突然很高,于是找了 ...
- flume高级组件及各种报错
1,one source two channel 创建conf文件,内容如下: #定义agent名, source.channel.sink的名称 access.sources = r1 access ...
- vivo面试学习3(git和svn的区别)
git和svn有什么区别? svn: 系统特点: 1).集中式版本控制系统(存在一个中央版本库,所有开发人员所使用的代码都是来源于版本库,提交代码也是这个中央版本库) 2).企业内部并行集中开发 3) ...
- 【Python实例二】之前期准备:Windows下的BeautifulSoup安装
前言 一直久闻Python的爬虫很高效,而且操作便捷,因此决定开始练习爬虫的相关内容. 首先尝试的是Python的爬虫利器之一:BeautifulSoup.(这名字听起来就有种想要去探究的兴趣.... ...
- 计算Linux权限掩码umask值
创建文件默认最大权限为666 (-rw-rw-rw-),默认创建的文件没有可执行权限x位. 创建目录默认最大权限777(-rwx-rwx-rwx),默认创建的目录属主是有x权限,允许用户进入. 简单的 ...
- Invalidate()(转)
原文转自 http://m.blog.csdn.net/blog/piaopiaopiaopiaopiao/41521211 使用Invalidate(TRUE)函数时,它会向消息队列中添加了WM_E ...