软工之词频统计器及基于sketch在大数据下的词频统计设计
摘要
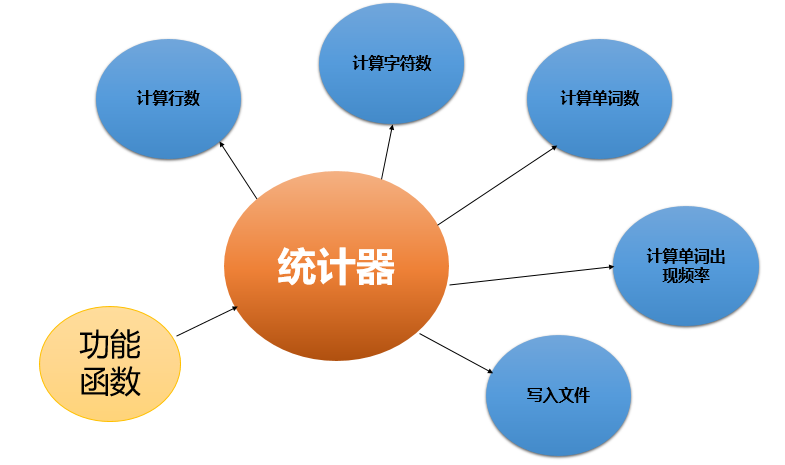
- 本词频统计器包括行数统计、字符数统计、单词数统计、词频统计功能。基于红8黑树算法和稳定排序实现,其中红黑树算法为本词频统计器提供良好的效率、提供性能下限保证、提供词频统计的高性能、提供较小的资源开销,而稳定排序算法提供了排序的稳定性,保证了词频统计结果按照字典序生成。本词频统计器基于C++实现,如下图所示,统计器作为对象,具有五个成员函数,分别实现统计器的五个功能,而功能函数提供了稳定排序等功能。并设计了异常处理函数,解决一定场景下的异常问题。
算法关键
红黑树
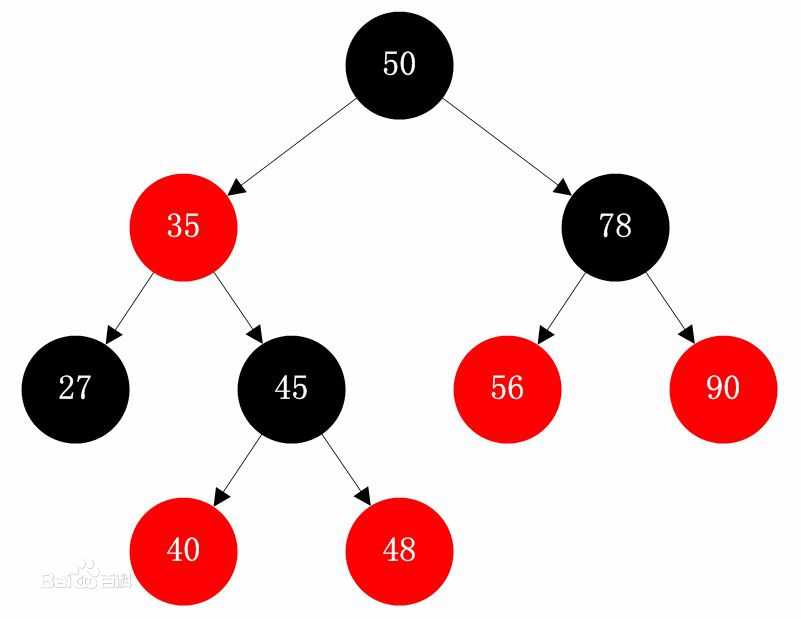
红黑树是一种自平衡的二叉查找树,是一种高效的查找树。
本词频统计器基于红黑树算法,具有以下优点:
提供良好的效率:可在O(logN)时间内完成查找、增加、删除等操作,能保证在最坏情况下,基本的动态几何操作的时间均为O(lgn)。只要求部分地达到平衡要求,降低了对旋转的要求,任何不平衡都会在三次旋转之内解决,从而提高了效率。本词频统计器设计大量增删改查操作,红黑树算法提供了良好的效率支撑。
提供性能下限保证:相比于BST,红黑树可以能确保树的最长路径不大于两倍的最短路径的长度,可见其查找效果的最低保证。最坏的情况下也可以保证O(logN)的复杂度,好于二叉查找树O(N)复杂度。在大数据量情况下,红黑树算法为词频统计器提供良好的性能保证。
提供词频统计的高性能:红黑树的算法时间复杂度和AVL树相同,但统计性能更高。插入 AVL树和红黑树的速度取决于所插入的数据。在数据比较杂乱的情况,则红黑树的统计性能优于AVL树。在词频统计时,数据分布较为杂乱,在此应用场景下,红黑树算法与词频统计器契合。
提供较小的资源开销:与基于哈希的算法相比,基于红黑树方法带来更小的资源开销,程序消耗内存较少。哈希的算法占用大量资源,需要维护大量的计数器,并且在哈希过程中消耗了大量的计算资源。本词频统计器消耗的资源较少。
稳定排序
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,则称这种排序算法是稳定的。本词频统计器利用了稳定排序。
- 稳定性;词频统计后,要求按字典序输出,而经过红黑树处理后,以达到字典序的要求,若使用非稳定排序,虽性能较高,但打乱了原先的字典序。经过稳定排序后,相对次序保持不变,仍为字典序,满足要求。
- 达到一定性能:本词频统计器利用了STL库中的stable_sort()函数,避免重复制造车轮。其复杂度是O(N (log N)^2)。在有足够内存时,可以达到O( N log N)。
代码框架
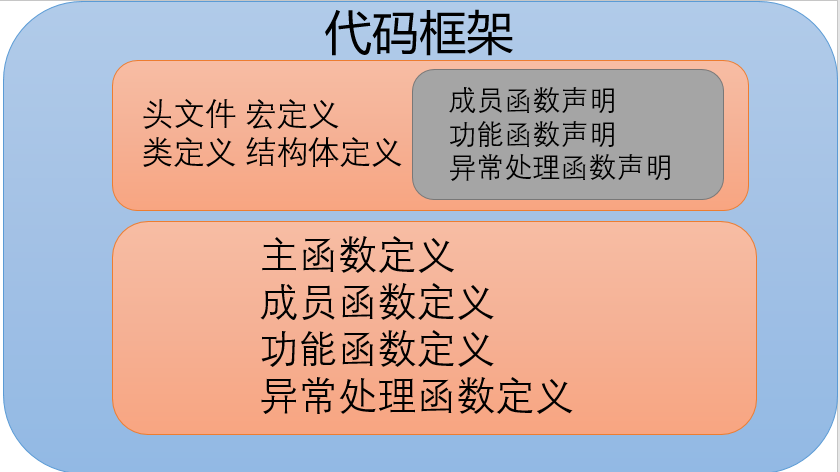
本程序代码为如上结构,分为两个部分:
- .h
- .cpp
.h文件:
定义:
- 宏定义:用于设定存储空间大小
- 类定义:定义了统计器的类
- 结构体定义:定义了存放词频统计的结构体
声明
- 成员函数声明:声明了包括行统计、字符统计、词数统计、词频统计功能的成员函数
- 功能函数声明:声明了包括字符类型转换、结构体比较的功能函数
- 异常处理函数声明:声明了三种的异常处理函数
.cpp文件
- 主函数定义:定义了主函数
- 成员函数定义:定义了包括行统计、字符统计、词数统计、词频统计功能的成员函数
- 功能函数定义:定义了包括字符类型转换、结构体比较的功能函数
- 异常处理函数定义:定义了三种的异常处理函数
频率统计器的实现
下列过程中,从上到下为词频统计的实现大致过程:
- 打开文件
- 异常检测
- 文件流按行读取到字符串数组
- 特殊符号处理
- 大写字母处理
- 行数组单词化
- 单词筛选
- 构造红黑树
- 提取键值对至结构体数组
- 稳定排序
- 重构字符流
接口设计与实现
接口设计
- 设计了一个Counter类,和构造函数。构造函数从外部获取的源文件名和目的文件名,进行文件流操作。
- 设计了四个具有统计功能的成员函数,通过获取的源、目的文件名,对文件进行读写,统计行数、字符、单词、频率。不在函数中直接输出,或者直接写入文件,而是返回一个整型值,将输出与功能解耦,降低了函数之间的耦合度。
- 设计了一个Write()函数直接用于文件读写,专门完成该功能。
class Counter
{
private:int Line;
int Ch;
int Words;
string Freq;
string sfn, dfn;
public:Counter(){}
Counter(string sfn,string dfn)
{
this->sfn = sfn;
this->dfn = dfn;
Line = 0;
Ch = 0;
Words = 0;
Freq = "\0";
}
int LineCount();
int CharCount();
int WordCount();
string WordFreq();
void Write();
};
- 定义了宏,便于更改内存空间使用大小:
#define Linethreshold 5000
#define Charthreshold 50000
#define Wordthreshold 20000
- 设计了异常处理函数,便于在需要检验之处加入检验功能:
- 设计了类型转换函数,本统计器多处涉及类型转换,简化了实现:
int DetectFileOpen(ifstream &infile);
int DetectOutfileOpen(ofstream &outfile);
string Conventor(int src);
核心功能词频统计器流程
- 打开文件
- 异常检测
- 文件流按行读取到字符串数组
- 特殊符号处理:处理非字母和数字字符。
- 大写字母处理:使用函数将大写字母处理为小写。
- 行数组单词化:提取单词。
- 单词筛选:将单词筛选进一个字符串数组。
- 构造红黑树:将单词和频数构成键值对,
- 提取键值对至结构体数组:将键值对提取到自设计的结构图数组。
- 稳定排序:对数组进行稳定排序,保持字典序。
- 重构字符流:将排序后的前十位输出到字符流中。
string Counter::WordFreq()
- 特殊符号处理
for (int i = 0; i<line; i++)//特殊符号处理
{
int j = 0;
while (str[i][j] != '\0')
{
if (ispunct(str[i][j]))str[i][j] = ' ';//特殊符号处理为空格
else
{
str[i][j] = tolower(str[i][j]);//化为小写
}
j++;
}
}
- 单词提取
for (int i = 0; i<line; i++)//将空格处理后的文档转化为单词
{
if (str[i]!="\0") {
istringstream stream(str[i]);
while (stream)stream >> str1[j];
j++;
}
}
- 单词筛选
for (int i = 0; i<j; i++)//单词筛选
{
isword = true;
for (k = 0; k<4; k++)//除去数字开头
{
if (str1[i][0] == '\0')
{
isword = false;
break;
}
if (str1[i][k] == '\0')break;
else if (!isalpha(str1[i][k])) {
isword = false;
break;
}
}
if (!isword) {
str1[i] = '\0';
}
}
- 构造红黑树
map<string, int> mymap;
map<string, int>::iterator it;
for (int i = 0; i<j ; i++)
{
//查找 是否有key 有的话 value++
//否则加入这个key
it = mymap.find(str1[i]);
if (it == mymap.end())
{
mymap.insert(map<string, int> ::value_type(str1[i], 1));
}
else
{
mymap[str1[i]]++;
}
}
it = mymap.begin();
string temps = "\0";
stringstream ss;
int i = 0;
WF a[100];
for (i = 0; it != mymap.end(); it++, i++)
{
a[i].key = it->first;
a[i].value = it->second;
}
stable_sort(&a[0], &a[i+1], cmp);
for (j = 0; j<i; j++)
{
ss.clear();
temps = "\0";
str[j] = "\0";
ss << a[j].value;
ss >> temps;
str[j] = "<" + a[j].key + "" + ">: " + temps;
}
- 重构字符流
for (i = 0; str[i] != "\0"; i++)
{
if (i >= 10)break;
if(str[i][0]=='<')
result += str[i] + "\n";
else break;
}
//cout << result;
infile.close();
return result;
}
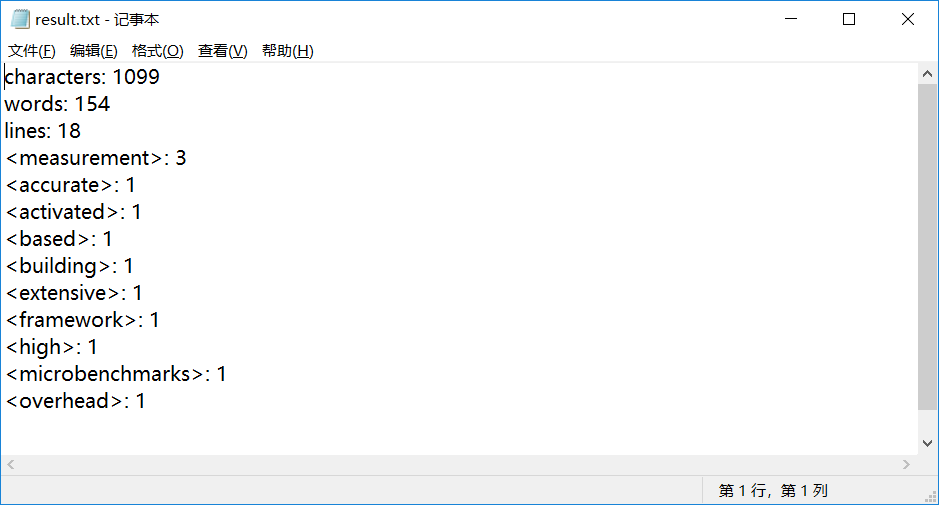
效果
- 对一段论文的摘要进行测试:

- 效果如下
单元测试
- 单元测试应该在最低的功能/参数上验证程序的正确性。
- 单元测试必须由最熟悉代码的人(程序的作者)来写。
- 单元测试过后,机器状态保持不变。
- 单元测试要快(一个测试运行时间是几秒钟,而不是几分钟)。
- 单元测试应该产生可重复、一致的结果。
- 单元测试应该覆盖所有代码路径,包括错误处理路径,为了保证单元测试的代码覆盖率,单元测试必须测试公开的和私有的函数/方法。
基于以上要求,设计了以下单元测试:
| 序号 | 测试用例 | 测试对象 | 测试结果 |
|---|---|---|---|
| 1 | 有空白字符的行 | LineCount() | 通过 |
| 2 | 存在各种样式的字符 | CharCount() | 通过 |
| 3 | 数字和单词正确判断 | WordCount() | 少算一个,更改后通过 |
| 4 | 处理特殊字符 | WordCount() | 通过 |
| 5 | 处理大写字母 | WordFreq() | 通过 |
| 6 | 单词种类超过十个 | WordFreq() | 通过 |
| 7 | 只有字母 | WordCount() | 迭代器崩溃,更改后通过 |
| 8 | 单词频率是否正确排序 | WordFreq() | 符合字典序 |
| 9 | 无空行 | LineCount() | 通过 |
| 10 | 空白文本 | LineCount() | 输出为0,通过 |

- 测试覆盖率,可以看出,覆盖率极高,分析后主要未覆盖部分为异常检测函数,损失部分覆盖率。

以下列出序号1的单元测试代码:
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
Counter C("F:\\软工\\WordCount\\TEST\\1.txt", "F:\\软工\\WordCount\\TEST\\result.txt");
int re = C.LineCount();
Assert::AreEqual(re, 2);
}
};
}
性能分析
性能分析图
- 可以看出,红框内的词频统计功能,占用了最多的CPU资源:


问题发现


- 从以上两图可以看出,在申请内存空间和返回字符串时,性能开销最大。所以考虑从内存分配入手,优化性能。
解决方案
法一
- 为了更加灵活高效申请内存空间,设计了宏。
- 可以方便定义内存空间使用,并且节省CPU消耗。
- 修改时,只需要修改宏即可。
#define Linethreshold 5000
#define Charthreshold 50000
#define Wordthreshold 20000
法二
- 当数据量非常大的时候,内存将成为性能瓶颈,提出基于sketch在大数据下的词频统计设计,利用算法Count-min sketch解决内存消耗过大的问题。(具体见下文)
异常处理
- 设计了三个应用场景的异常处理,包括:
- 读文件未正常开启:
int DetectFileOpen(ifstream &infile)
{
if (!infile.is_open())
{
cout << "Cannot open the file, please input right filename!";
system("pause");
return 0;
}
}
- 写文件未能正常开启:
int DetectOutfileOpen(ofstream &outfile)
{
if (outfile.is_open())
{
cout << "Cannot open the file!";
system("pause");
return 0;
}
}
- 输入错误的文件名:
if (argc != 2)
{
cout << "Uncorrect parameters, Please attach .exe and .txt file in order.";
system("pause");
}
- 文件名错误时,报错,并提供解决方案:
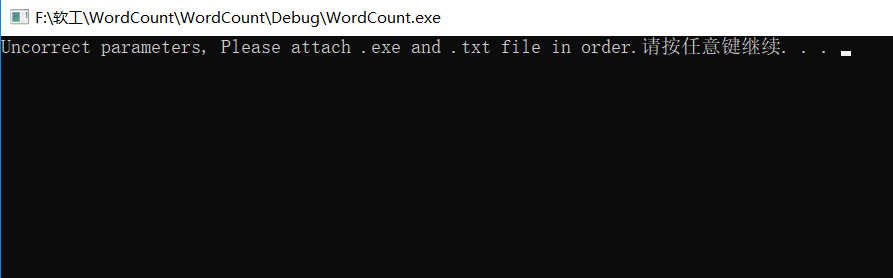
PSP表格记录
| PSP2.1 | header 2 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 30 |
| · Estimate | ·估计这个任务需要多少时间 | 15 | 5 |
| Development | 开发 | 645 | 1220 |
| · Analysis | 需求分析(包括学习新技术) | 40 | 50 |
| · Design Spec | · 生成设计文档 | 40 | 60 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 240 | 600 |
| · Code Review | · 代码复审 | 10 | 10 |
| · Test | ·测试(自我测试,修改代码,提交修改) | 240 | 360 |
| Reporting | 报告 | 245 | 145 |
| · Test Repor | · 测试报告 | 240 | 120 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
|合计||935|1400
感想
- 软工作业的量,真是超乎了我的想象,从PSP表中可以看出,我的预估严重不准。而且表中的记录只可能小于实际值,还不包括写博客的时间。这次统计器的实现,不算难,但也走了不少弯路,例如需求分析没有做到位,设计的大局观不足,导致后期代码反复迭代差错,浪费大量时间。其中从《构建之法》中,学到了单元测试要求,很好地帮我解决了设计问题,让我设计出的单元测试更加合理。最有意思的是单元测试还有强大的性能分析工具,在单元测试后,我查出了许多代码中的不足,并加以修改。在性能分析后,我可以准确找到我设计中性能的不足和导致不足相应的代码段,进行优化,应用于之后的程序设计及框架设计,将是一大利器。本次也是代码规范化的一大训练,可以体会一些,在实际开发中的方法和思想,回想到之前实际大型开源项目代码的阅读,对其中代码的规范化、接口的设计体会便更加深刻了。在设计过程中,也偶有灵感扇动,也一并记录下来。
基于sketch在大数据下的词频统计设计
引言
- 在海量数据的下,要对数据中的单词的词频进行统计分析,需要对数据存储、处理,并且维护大量的计数器,将消耗极大资源空间。在本设计中,需要对单词进行分析、处理、稳定排序,最后得出精确的统计结果,而在大数据下,消耗的时间和内存资源是不可接受的。在数据足够多的情况下,要了解单词出现的频率和频率排序,其实没有必要了解词频的精确值,只需提供单词出现的估计值和排序即可。对此,通过在网络测量中相关文献的阅读,提出基于sketch在大数据下词频统计,以达到**节省资源*的目的。
背景
- 在网络测量中,常使用基于sketch的方法,在高速条件下对网络流的数据进行估计,达到节约资源的目的。在网络中存在各种各样的包,若按精确的分类方法,对每一种包都分配一个计数器储存,虽然测量准确,但存放计数器的空间开销会非常大。故使用哈希的方法,根据哈希值的范围确定的所需的存储空间,各种包根据哈希值再次归类,可以大大减少存储空间*。这样使用哈希来估计流的方法称为Sketch-based方法。
- 相似的,在大数据下,如果对所有单词都进行准确存储统计,不仅没有必要,而且占用大量内存资源。对此,提出基于sketch在大数据下词频统计,在达到需求的条件下,达到节省资源目的。
解决方案
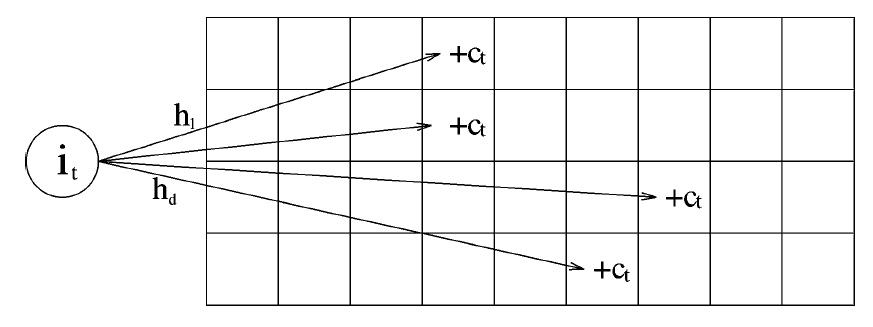
- 使用哈希的方法会产生冲突,多个种类的单词哈希到同一个桶内,那么这个桶的计数值就会偏大,为了减少误差,可以使用count-min sketch*。
- Count-min sketch:设置多个哈希函数,开辟一个二维地址空间,包经过不同哈希函数的处理,得到对应的哈希值,而这个哈希值就是sketch(概要)。这些哈希值可能产生冲突,多个种类单词可能有相同的哈希值,根据哈希值来确定单词出现的次数则会偏大,所以设置多个哈希函数,取最小的哈希值,则最接近实际包数据。
- 得到每个种类包的估计值后,对sketch进行排序,取前十种类的包,即可得到词频统计结果。
总结
- Sketch是使用哈希来进行估计网络流的一种测量方法,可以减少存储开销,相似地,应用于大数据下的词频统计,可以减少内存开销。
- 可以使用Count-Min Sketch对文本数据进行处理,多个哈希函数的最小哈希值作为词频的估计,实现简单,空间开销较少,
参考文献:
- SketchVisor: Robust Network Measurement for Software Packet Processing
- An improved data stream summary: the count-min sketch and its applications
- https://www.cnblogs.com/fxjwind/p/3289221.html
- https://blog.csdn.net/lzuacm/article/details/52691450
- http://www.runoob.com/cplusplus/cpp-files-streams.html
- https://baike.baidu.com/item/tolower/6389989?fr=aladdin
- https://baike.baidu.com/item/ctype.h/8497240?fr=aladdin
- https://blog.csdn.net/sophia1224/article/details/53054698
- https://bbs.csdn.net/topics/392186748
- http://www.runoob.com/cplusplus/cpp-stl-tutorial.html
- https://blog.csdn.net/ajianyingxiaoqinghan/article/details/78540736
- https://blog.csdn.net/shinetzh/article/details/65660128
- https://blog.csdn.net/beyongwang/article/details/53074704
- https://blog.csdn.net/qq_31828515/article/details/52056779
- http://www.cnblogs.com/xinz/archive/2011/11/20/2255830.html
- https://www.cnblogs.com/SivilTaram/p/software_pretraining_cpp.html
- https://www.cnblogs.com/nullllun/p/8214599.html
- https://www.cnblogs.com/wuchanming/p/4444961.html
- http://blog.sina.com.cn/s/blog_667cddfc0100wet3.html
软工之词频统计器及基于sketch在大数据下的词频统计设计的更多相关文章
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 高速基于echarts的大数据可视化
[Author]: kwu 高速基于echarts的大数据可视化,echarts纯粹的js实现的图表工具.高速开发的过程例如以下: 1.引入echarts的依赖js库 <script type= ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 一台虚拟机,基于docker搭建大数据HDP集群
前言 好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做.这个可以参考之前写得关于我大数据毕业设计的文章.这篇文章是将对之前的毕设进行优化. 个人觉得可以分为两个部分.第一个部分就是基础的平台 ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
随机推荐
- C#学习笔记(基础知识回顾)之枚举
一:枚举的含义 枚举是用户定义的整数类型.在声明一个枚举时,要指定该枚举的示例可以包含的一组可接受的值.还可以给值指定易于记忆的名称.个人理解就是为一组整数值赋予意义. 二:枚举的优势 2.1:枚举可 ...
- 【Android】15.0 UI开发(六)——列表控件RecyclerView的网格布局排列实现
1.0 列表控件RecyclerView的网格布局排列实现,关键词GridLayoutManager. LinearLayoutManager 实现顺序布局 GridLayoutManager 实现网 ...
- Java EE大作业之创造class类出现问题-------Implicit super constructor Object() is undefined for default constructor. Mu
这个学期一直在忙着考驾照的事情,眼看就要期末了.我的大学生活的最后一个大的作业也要来临了.说实话这个学期真的是没有之前的两个学期努力了.不知道是快要毕业的缘故还是真的是把心思用在了驾照上,想着在这次放 ...
- CSS3之word-wrap英文单词溢出强制换行
语法 word-wrap: normal|break-word; 所有主流浏览器都支持 word-wrap 属性. <div style="border:1px #f00 solid; ...
- Python 批量修改文件名并移动文件到指定目录
# -*- coding: utf-8 -*- import os, sys,re,shutil from nt import chdir #读取中文路径 u'' path=u"D:\\zh ...
- HDFS原理解析
一.HDFS简介 HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(computer nodes ...
- jQuery 插件封装的方法
方式1.$.fn.xxx ==>针对元素添加方法: ;(function ($) { $.fn.myPlugin = function () { //你自己的插件代码 }; })(jQuer ...
- Django 的视图层
什么是视图: 之前我们也了解了urls路由 那么路由的主要作用是决定你下一步走哪个视图函数 ,视图就是用来存放一个个的函数的python文件,主要存储的函数就是你Django主要的流程的控制 都存放在 ...
- python之内置函数,匿名函数
什么是内置函数? 就是Python给你提供的,拿来直接用的函数,比如print,input等等.其实就是我们在创建.py的时候python解释器所自动生成的内置的函数,就好比我们之前所学的作用空间 内 ...
- Python学习---django下的Session操作 180205
和Cookie一样,都是用来进行用户认证.不同的是,Cookie可以吧明文/密文的信息都会KV返回给客户段,但是session可以吧用户的Value[敏感信息]保存在服务器端,安全. Django中默 ...