图论——最短路径 Dijkstra算法、Floyd算法
1.弗洛伊德算法(Floyd)
弗洛伊算法核心就是三重循环,M [ j ] [ k ] 表示从 j 到 k 的路径,而 i 表示当前 j 到 k 可以借助的点;红色部分表示,如果 j 到 i ,i 到 k 是通的,就将 j 到 k 的值更新为
M[j][i] + M[i][k] 和 M[j][k] 较短的一个。
<<;
; i <= n; i++) {
; j <= n; j++) {
; k <= n; k++) {
if (j!=k) {
M[j][k] = min(M[j][i] + M[i][k] , M[j][k]);
}
}
}
}
给个题目链接,写完可以交试一下:http://www.dotcpp.com/oj/problem1709.html
完整代码:
#include <iostream>
#include <queue>
using namespace std;
#define inf 2147483647
][];
int main() {
int n;
queue<int>q;
cin >> n;
; i <= n; i++) {
; j <= n; j++) {
cin >> M[i][j];
&& i != j)M[i][j] = inf;
}
}
; i <= n; i++) {
; j <= n; j++) {
; k <= n; k++) {
) {
if (M[j][i] != inf && M[i][k] != inf) {
M[j][k] = M[j][i] + M[i][k] < M[j][k] ? M[j][i] + M[i][k] : M[j][k];
}
}
}
}
}
; i <= n; i++) {
; j <= n; j++) {
<< " ";
else
cout << M[i][j] << " ";
}
cout << endl;
}
;
}
2.迪杰斯特拉
Floyd只要暴力的三个for就可以出来,代码很好理解,但缺点就是时间复杂度高是O(n³)。Dijkstra的时间复杂度是O(n²),要快很多。
不过要注意这个算法所求的是单源最短路。所以说,如果题目是求任意一对顶点间的最短路径问题,那就需要对每个顶点进行一遍迪杰斯特拉算法,这种情况就适合弗洛伊德算法了。
思想图解:
用dis数组实时记录起始点(起始点取1) 到达的所有节点的距离。(自己到自己的路径长度 0,到不了的点是 inf(极大值))
dis数组初始值是这样的,4是当前距离节点1最近的点。(已经访问过的,我们标记上不再次访问)
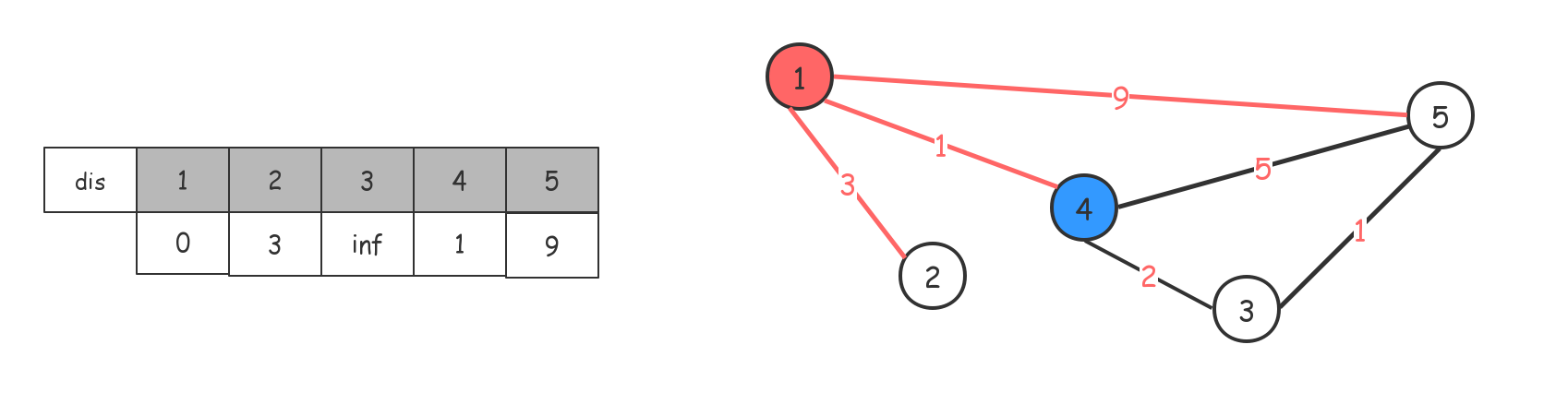
借助4节点,对dis数组进行更新(如果有更短的路径,就对dis数组进行值替换),走到2,无操作。
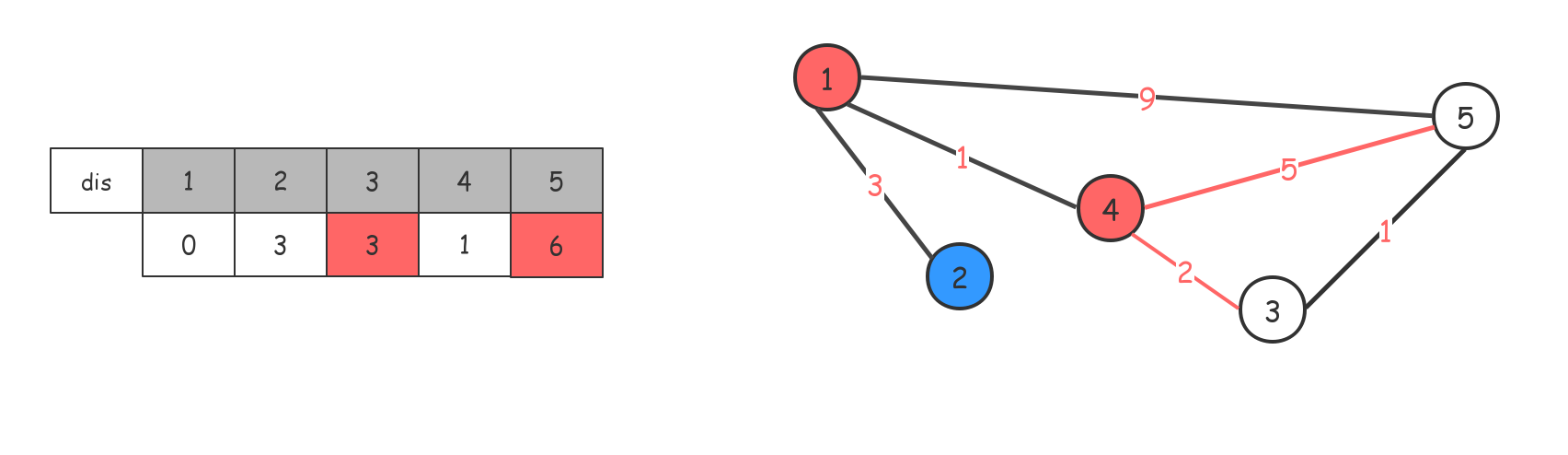
借助3节点,对dis数组进行更新,最后走到5节点,退出。(实际过程中,走到最后一个节点,别的节点都访问过,进行标记了,什么也不会做)。
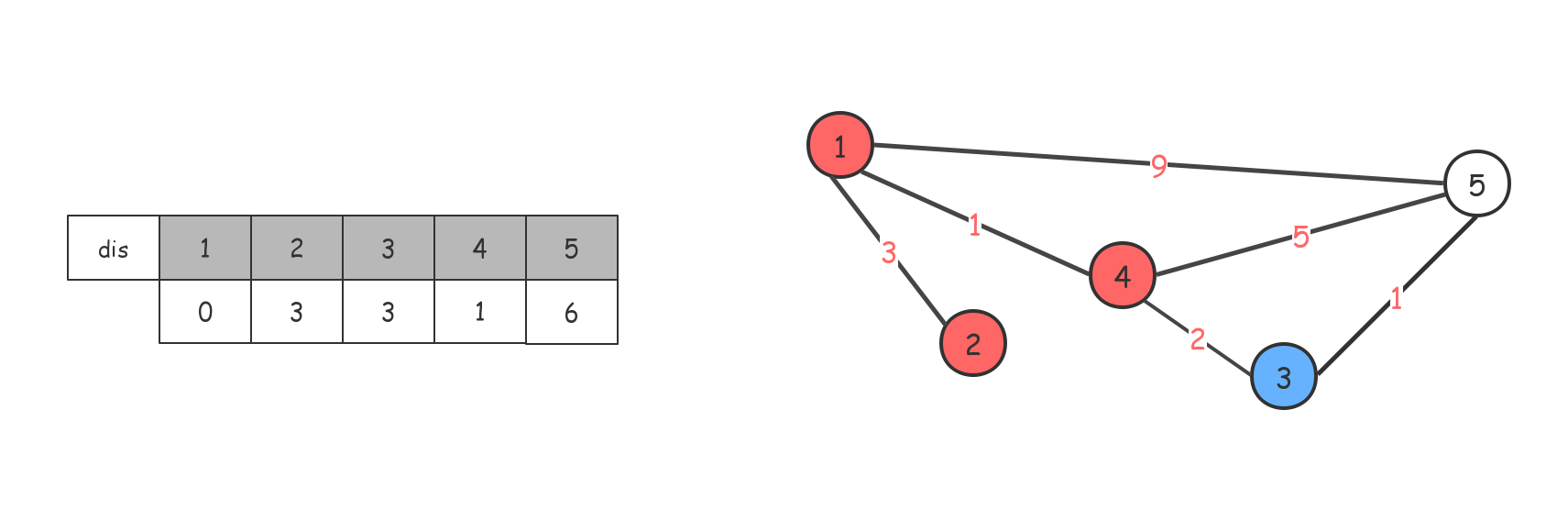
借助3节点,对dis数组进行更新
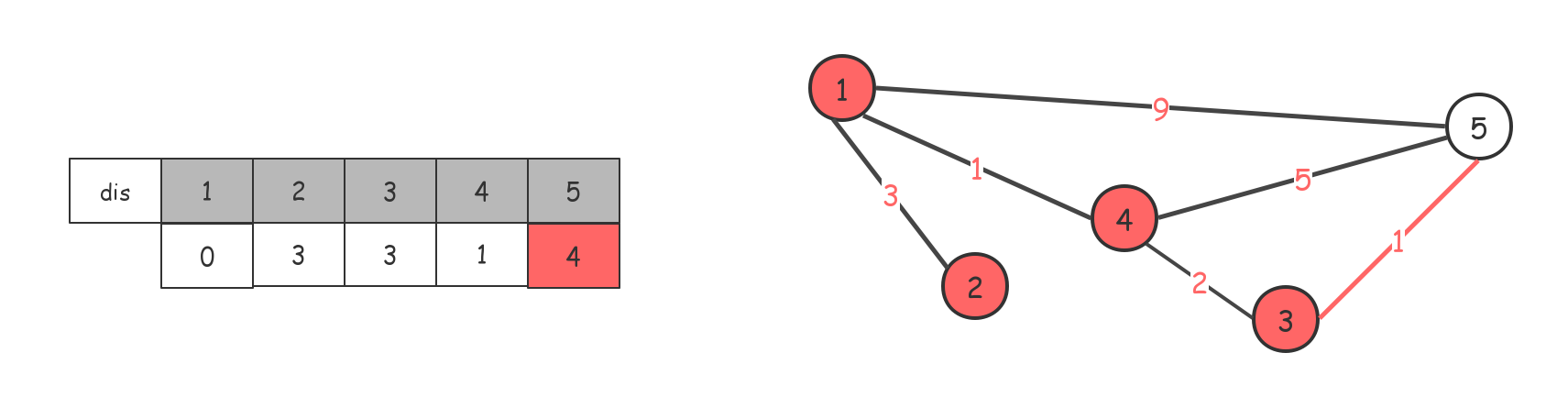
测试题目:http://acm.hdu.edu.cn/showproblem.php?pid=2544 (数据很弱,AC了,实现也不一定是正确的,强烈建议再做后面一题)
#include <iostream>
#include <algorithm>
#include <string.h>
using namespace std;
<< ;
int n, m;
];
][];
];
void initialize() {
memset(book, , sizeof(book));
; i <= n; i++) {
; j <= n; j++) {
if (i != j)M[i][j] = inf;
}
}
}
void dijkstra() {
while (true) {
;
; i <= n; i++) {
|| dis[i] < dis[v])) v = i;//从dis数组中找出当前距离起点最短的节点
}
) break;
book[v] = true;
; i <= n; i++) {
dis[i] = min(dis[i], dis[v] + M[v][i]);
}
}
}
int main() {
while (cin >> n >> m) {
&& m == )break;
initialize();
; i < m; i++) {
int A, B, C;
cin >> A >> B >> C;
M[A][B] = C;
M[B][A] = C;
}
book[] = true;
; i <= n; i++) {
dis[i] = M[][i];
}
dijkstra();
cout << dis[n] << endl;
}
;
}
使用优先级队列优化查找过程(理论上是要更快的,但是我交上去,时间反而更慢了 ):
):
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
<< ;
int n, m;
][];
];
class Node {
public:
int to,distance;
Node(int t, int d) {
to = t; distance = d;
}
bool operator< (Node a) const{
return a.distance < distance;
}
};
priority_queue<Node>q;
void initialize() {
; i <= n; i++) {
; j <= n; j++) {
if (i != j)M[i][j] = inf;
}
}
}
void dijkstra() {
while (!q.empty()) {
int min; min = q.top().to;q.pop();
//处理掉之前push进去的,距离较长的边,不写不会错,效率会降低。
while (!q.empty() && q.top().to == min) {
q.pop();
}
; i <= n; i++) {
if (dis[i] > dis[min] + M[min][i]) {
dis[i] = dis[min] + M[min][i];
q.push(Node(i, dis[i]));
}
}
}
}
int main() {
while (cin >> n >> m) {
&& m == )break;
initialize();
; i < m; i++) {
int A, B, C;
cin >> A >> B >> C;
M[A][B] = C;
M[B][A] = C;
}
; i <= n; i++) {
dis[i] = M[][i];
&& dis[i] != inf) {
q.push(Node(i, dis[i]));
}
}
dijkstra();
cout << dis[n] << endl;
}
;
}
邻接表+优先级队列:(邻接表的迪杰斯特拉实现起来,要复杂得多,但是跑起来确实比较快)
#include <iostream>
#include <stdio.h>
#include <queue>
using namespace std;
];
<< ;
];
class ENode {
public:
int to;
int dis;
ENode *next = NULL;
ENode() {};
ENode(int t, int d) {
dis = d; to = t;
}
void push(int t, int d) {
ENode *p = new ENode;
p->to = t; p->dis = d;
p->next = next;
next = p;
}
bool operator<(ENode e)const {
return e.dis < dis;
}
}head[];
int main() {
priority_queue<ENode>q;
int n, m, c1, c2, c3;
while (cin >> n >> m) {
&& m == )break;
; i <= n; i++) {
dis[i] = inf;
fuck[i] = false;
}
; i < m; i++) {
scanf("%d%d%d", &c1, &c2, &c3);
head[c1].push(c2, c3);
head[c2].push(c1, c3);
|| c2 == ) {
dis[c1 == ? c2 : c1] = c3;
q.push(*head[c1].next);
}
}
fuck[] = true;
while (!q.empty()) {
int fm = q.top().to; q.pop();
if (fuck[fm])continue;
fuck[fm] = true;
ENode *p = head[fm].next;
while (p) {
int me = p->to;
if (dis[me] > dis[fm] + p->dis) {
dis[me] = dis[fm] + p->dis;
q.push(ENode(me, dis[me]));
}
p = p->next;
}
}
printf("%d\n", dis[n]);
; i <= n; i++) {
ENode *p = head[i].next;
while (p) {
ENode *t = p->next;
delete p;
p = t;
}
head[i].next = NULL;
}
}
;
}
理解不深刻,实现出来的错误版本,能出来正确的答案,但升高了复杂度:
#include <iostream>
#include <stdio.h>
#include <queue>
using namespace std;
];
];
<< ;
class ENode {
public:
int to;
int dis;
ENode *next = NULL;
void push(int t, int d) {
ENode *p = new ENode;;
p->to = t; p->dis = d;
p->next = next;
next = p;
}
bool operator<(ENode e)const {
return e.dis < dis;
}
}head[];
int main() {
priority_queue<ENode>q;
int n, m, c1, c2, c3;
while (cin >> n >> m) {
&& m == )break;
; i <= n; i++) {
dis[i] = inf;
}
; i < m; i++) {
scanf("%d%d%d", &c1, &c2, &c3);
head[c1].push(c2, c3);
head[c2].push(c1, c3);
}
ENode *p = head[].next;
while (p) {
q.push(*p);
dis[p->to] = p->dis;
p = p->next;
}
while (!q.empty()) {
int fm = q.top().to; q.pop();
/*------------*/
/*这个是错误指定背锅店,如果不写这一句,当出现完全图的情况时,
算法会近乎退化成n^n,HDU的这题测试数据太弱了,导致我没有发现问题。
写了的话,由于下面往队列中Push的错误的,这里也就成了背锅点*/
if (fuck[fm])continue;
fuck[fm] = true;
/*------------*/
ENode *p = head[fm].next;
while (p) {
int me = p->to;
if (dis[me] > dis[fm] + p->dis) {
dis[me] = dis[fm] + p->dis;
//真正错误在这里
q.push(*p);
}
p = p->next;
}
}
printf("%d\n", dis[n]);
; i <= n; i++) {
ENode *p = head[i].next;
while (p) {
ENode *t = p->next;
delete p;
p = t;
}
head[i].next = NULL;
}
}
;
}
我为什么能发现代码实现的错误,因为我天赋过人,因为这题数据很强,https://www.luogu.org/problemnew/show/P4779 数据量很大,100000个节点,不管是时间还是空间上,不能再用邻接矩阵了;邻接表,如果实现得不恰当也是会超时的,这题如果能AC,那算法实现的肯定是没有问题了。
邻接表+优先级队列:
#include <iostream>
#include <stdio.h>
#include <queue>
using namespace std;
];
];
<< ;
class ENode {
public:
int to;
int dis;
ENode *next = NULL;
void push(int t, int d) {
ENode *p = new ENode;;
p->to = t; p->dis = d;
p->next = next;
next = p;
}
bool operator<(ENode e)const {
return e.dis < dis;
}
}head[];
int main() {
priority_queue<ENode>q;
int n, m, s, c1, c2, c3;
cin >> n >> m >> s;
; i < m; i++) {
//cin >> c1 >> c2 >> c3;
scanf("%d%d%d", &c1, &c2, &c3);
head[c1].push(c2, c3);
}
; i <= n; i++) {
if (i != s) {
dis[i] = inf;
}
}
ENode *p = head[s].next;
while (p) {
|| (p->dis < dis[p->to])) {
q.push(*p);
dis[p->to] = p->dis;
}
p = p->next;
}
while (!q.empty()) {
//获得当期距离 源点 最近的点
int min = q.top().to; q.pop();
if (fuck[min])continue;
fuck[min] = true;
ENode *p = head[min].next;
while (p) {
int to = p->to;
if (dis[to] > dis[min] + p->dis) {
dis[to] = dis[min] + p->dis;
ENode e = *p;
e.dis = dis[to];
q.push(e);
}
p = p->next;
}
}
; i <= n; i++) {
printf("%d ", dis[i]);
}
cout << endl;
;
}

3、Bellman-Ford算法
Bellman - ford效率较低,代码难度较小。重要的是若给定的图存在负权边,Dijkstra算法便没有了用武之地,Bellman - ford算法便派上用场了。
图论——最短路径 Dijkstra算法、Floyd算法的更多相关文章
- 算法学习笔记(三) 最短路 Dijkstra 和 Floyd 算法
图论中一个经典问题就是求最短路.最为基础和最为经典的算法莫过于 Dijkstra 和 Floyd 算法,一个是贪心算法,一个是动态规划.这也是算法中的两大经典代表.用一个简单图在纸上一步一步演算,也是 ...
- 多源最短路径算法—Floyd算法
前言 在图论中,在寻路最短路径中除了Dijkstra算法以外,还有Floyd算法也是非常经典,然而两种算法还是有区别的,Floyd主要计算多源最短路径. 在单源正权值最短路径,我们会用Dijkstra ...
- 图论-最短路径<Dijkstra,Floyd>
昨天: 图论-概念与记录图的方法 以上是昨天的Blog,有需要者请先阅读完以上再阅读今天的Blog. 可能今天的有点乱,好好理理,认真看完相信你会懂得 分割线 第二天 引子:昨天我们简单讲了讲图的概念 ...
- Dijkstra与Floyd算法
1. Dijkstra算法 1.1 定义概览 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点 ...
- [链接]最短路径的几种算法[迪杰斯特拉算法][Floyd算法]
最短路径—Dijkstra算法和Floyd算法 http://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html Dijkstra算 ...
- JS实现最短路径之弗洛伊德(Floyd)算法
弗洛伊德算法是实现最小生成树的一个很精妙的算法,也是求所有顶点至所有顶点的最短路径问题的不二之选.时间复杂度为O(n3),n为顶点数. 精妙之处在于:一个二重初始化,加一个三重循环权值修正,完成了所有 ...
- 图的最短路径算法-- Floyd算法
Floyd算法求的是图的任意两点之间的最短距离 下面是Floyd算法的代码实现模板: ; ; // maxv为最大顶点数 int n, m; // n 为顶点数,m为边数 int dis[maxv][ ...
- 最短路-SPFA算法&Floyd算法
SPFA算法 算法复杂度 SPFA 算法是 Bellman-Ford算法 的队列优化算法的别称,通常用于求含负权边的单源最短路径,以及判负权环. SPFA一般情况复杂度是O(m)最坏情况下复杂度和朴素 ...
- 只有5行代码的算法——Floyd算法
Floyd算法用于求一个带权有向图(Wighted Directed Graph)的任意两点距离的算法,运用了动态规划的思想,算法的时间复杂度为O(n^3).具体方法是:设点i到点j的距离为d[i][ ...
随机推荐
- jenkins 参数化构建过程
构建项目时我们可能需要切换到另一个分支编译,或者说每次编译版本都要加1,这时候我们可以改配置或者改脚本文件,这显然不是一个好的方式,那么如何能在编译前让用户输入参数呢?jenkins早就为我们考虑好 ...
- php中怎么导入自己写的类
如果写的类是写在当前php文件内,就直接实例化若你的类写在其他的php文件里,就要先用include或require,将类文件引入<?php include("class.php&qu ...
- Bootstrap Modal多个弹出层顺序
Bootstrap Modal多个弹出层顺序与div的顺序关联.后来者居上:即div靠后的modal层弹出的时候会在上层. 比如上图所示,模态框2弹出的时候会在模态框1上面.
- DOM操作表单(select下拉选框)
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- zookeeper安装和配置(单机+伪集群+集群)
#单机模式 解压到合适目录. 进入zookeeper目录下的conf子目录, 复制zoo_sample.cfg-->zoo.cfg(如果没有data和logs就新建):tickTime=2000 ...
- C++ 判断进程是否存在
原文:http://blog.csdn.net/u010803748/article/details/53927977?locationNum=2&fps=1 一.判断指定程序名的进程是否存在 ...
- Java web相关内容
我们即将学习Java web 这是通过查阅资料找到的和Java web 相关的内容. 一:Java web的含义 JavaWeb,是用Java技术来解决相关web互联网领域的技术总和.web包括:we ...
- 【Oracle】锁表处理 SQL 错误: ORA-00054: 资源正忙, 但指定以 NOWAIT 方式获取资源, 或者超时失效
问题描述有时候ORACLE数据的某些表由于频繁操作,而且比较大,会导致锁表(死锁). 问题分析(1)锁的分析ORACLE里锁有以下几种模式:0:none1:null 空2:Row-S 行共享(RS): ...
- new era
新的博客,将会记录我在工作和学习中遇到的问题以及总结...
- MySQL 8.0复制性能的提升(翻译)
What’s New With MySQL Replication in MySQL 8.0 MySQL复制从问世到现在已经经历了多个年头,它的稳定性和可靠性也在稳步的提高.这是一个不停进化的过程,由 ...