Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块
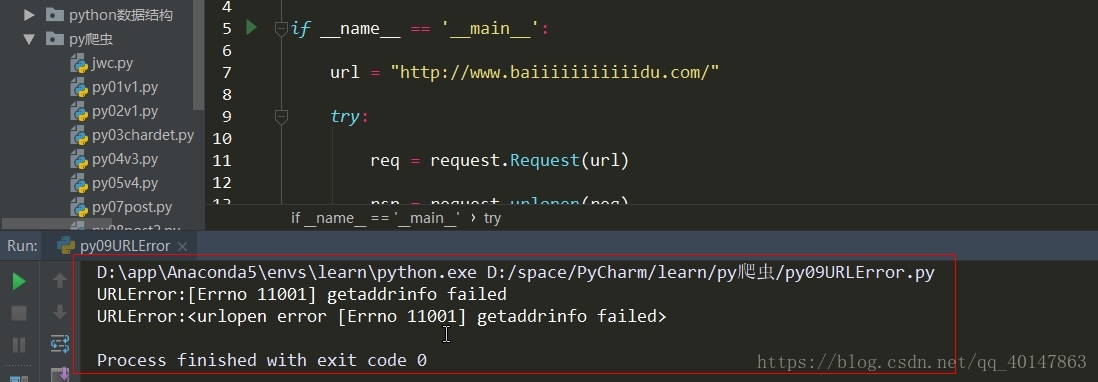
今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error
URLError
- URLError 产生的原因:
- 1.无网络连接
- 2.服务器连接失败
- 3.找不到指定的服务器
- 4.URLError是OSError的子类
- 案例v9文件:https://xpwi.github.io/py/py爬虫/py09error.py
# 案例v9
# URLError的使用
from urllib import request,error
if __name__ == '__main__':
url = "http://www.baiiiiiiiiiiidu.com/"
try:
req = request.Request(url)
rsp = request.urlopen(req)
html = rsp.read().decode()
print(html)
except error.URLError as e:
print("URLError:{0}".format(e.reason))
print("URLError:{0}".format(e))
except Exception as e:
print(e)
HTTPError
- 1.是URLError的一个子类
URLError和HTTPError的区别:
- HTTPError是对应的HTTP请求的返回码错误,如果返回错误码是400以上的,则引发HTTPError
- URLError对应的一般是网络出现问题,包括url问题
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-09-error 模块的更多相关文章
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
随机推荐
- java源码解析之Object类
一.Object类概述 Object类是java中类层次的根,是所有类的基类.在编译时会自动导入.Object中的方法如下: 二.方法详解 Object的方法可以分成两类,一类是被关键字fin ...
- Add:四则运算
输入为四则运算表达式,仅由整数.+.-.*./ .(.) 组成,没有空格,要求求其值.假设运算符结果都是整数 ."/"结果也是整数 表达式 由 项 或 项 ...
- mysql启动不起来
在刚编译安装完成mysql,启动mysql时报了下面错误: /etc/init.d/mysqld start Starting MySQL... ERROR! The server quit with ...
- ECharts-入门学习
最近因项目需要要做图表,后台数据要以柱状图的形式展示,通过上网查找,感觉ECharts这个js控件挺不错的,下面就把入门知识搞一下. 一.下载ECharts控件. 地址:http://echarts. ...
- JS写游戏
最近在看萧井陌的视频.感觉一些东西挺有意思的,尤其是解决问题的过程,以及一个好程序应该改进的地方. 萧大的GITHUB:github.com/guaxiao/gua.game.js 视频:https: ...
- Django 中文乱码问题&富文本显示
1.起源:从后台管理添加中文对象,正常,但是再次点击编辑的时候,抛出异常,显示编码问题. 解决:在项目的manage.py 的文件头部添加 import sys reload(sys) sys. ...
- C#调用SQLite报错:无法加载 DLL“SQLite.Interop.dll”: 找不到指定的模块
C#调用SQLite数据库,有些情况下会报以下这个错误: 无法加载 DLL“SQLite.Interop.dll”: 找不到指定的模块 实际上程序目录中是存在SQLite.Interop.dll这个文 ...
- Code First配合Entity Framework Power Tools Beta 4使用
基于现有数据库生成POCO数据类和数据库上下文需要借助Visual Studio一个扩展插件-- Entity Framework Power Tools(一个Code First反向工程工具).只要 ...
- 数据库SQLITE3初识
数据库DataBase,我们都没有接触过数据库,那么数据库是什么? 它是一个有结构的.集成的.可共享的统一管理的数据集合! 所谓有结构的,指的是数据是按一定的模型组织起来的. 简单的说,拿个箱子,用隔 ...
- Mysql中的分页处理
先来说一下Mysql中limit的语法: --语法: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset --举例: selec ...