GAN背后的数学原理
模拟上帝之手的对抗博弈——GAN背后的数学原理
简介
深度学习的潜在优势就在于可以利用大规模具有层级结构的模型来表示相关数据所服从的概率密度。从深度学习的浪潮掀起至今,深度学习的最大成功在于判别式模型。判别式模型通常是将高维度的可感知的输入信号映射到类别标签。训练判别式模型得益于反向传播算法、dropout和具有良好梯度定义的分段线性单元。然而,深度产生式模型相比之下逊色很多。这是由于极大似然的联合概率密度通常是难解的,逼近这样的概率密度函数非常困难,而且很难将分段线性单元的优势应用到产生式模型的问题。
基于以上的观察,作者提出了产生对抗网络。顾名思义,产生对抗网络包含两个网络:产生器和判别器。产生器负责伪造一些数据,要求这些数据尽可能真实(尽可能服从只有上帝知道的概率分布),而判别器负责判别给定数据是伪造的(来自产生器生成的数据),还是来自由上帝创造的真实分布。至此,我们不得不佩服作者如此的问题形式化。整个过程中就是在博弈。产生器尽可能伪造出真实的数据,而判别器尽可能提高自身的判别性能。
这样一种问题形式化实际上是一种通用框架,因为判别器和生成器可以是任何一种深度模型。为了简单起见,该篇文章只利用多层感知机,而且生成器所生成的样本是由随机噪声得到的。利用这种方法,整个模型的训练融入了之前无法利用的反向传播算法和dropout. 这个过程中不需要近似推测和马尔科夫链。
产生对抗网络
这部分将具体介绍产生对抗网络模型,并详细推导出GAN的优化目标。
简单起见,生成器和判别器都基于多层感知神经元。对于生成器,我们希望它是一个由噪声到所希望生成数据的一个映射;对于判别器,它以被考查的数据作为输入,输出其服从上帝所定义的概率分布的概率值。下图清晰地展示了这个过程。

假设我们有包含m个样本的训练集S={x(1),...,x(m)}. 此外,任给一种概率密度函数pz(z)(当然,在保证模型复杂度的前提下,相应的概率分布越简单越好),我们可以利用随机变量Z∼pz(z)采样得到m个噪声样本{z(1),...,z(m)}. 由此,我们可以得到似然函数
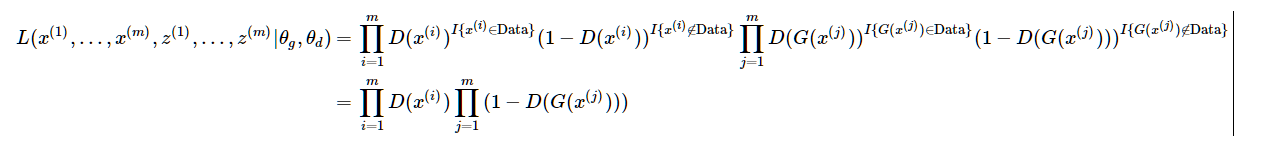
进一步,得到对数似然
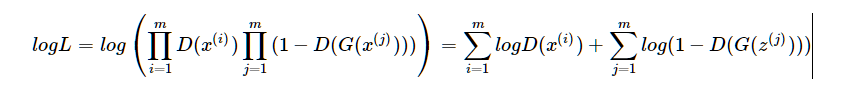
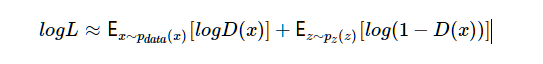

生成器G(⋅)实际上隐式定义了一个概率分布pg,将其称之为隐式是因为G是从噪声z∼pz到样本G(z)的映射。由此,我们自然会提出一个问题:通过这样的建模以及训练方式得到的pg能否最终达到上帝创造的那个分布pdata,或者说两者差距到底多少?
这个问题由下面的命题和定理回答。
首先,任意给定生成器G,我们考虑最优判别器D.
命题1. 对于给定G,最优判别器为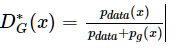
证明.
给定G,我们目标是最大化V(G,D)
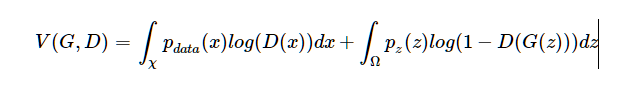
注意到第二项,利用映射关系x=G(z),我们可以得到
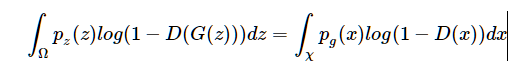
所以,
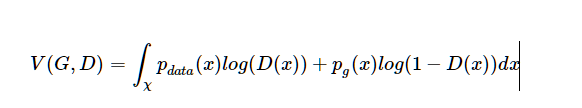

证毕。
有了这个定理,我们可以进一步将这个min max博弈重新形式化为最小化C(G),其中
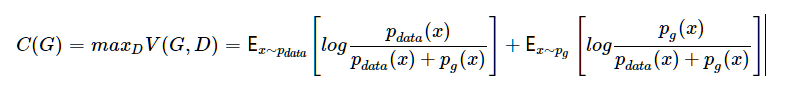
下面,我们提出并证明定理1. 由此回答本节最开始提出的问题:通过这样的建模以及训练方式得到的pg能否最终达到上帝创造的那个分布pdata,或者说两者差距到底多少?
定理1. 对于C(G)的全局优化最小值可达,当且仅当pg=pdata,并且最小值为−log4.
证明.

等号成立的条件为
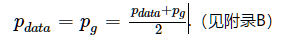
证毕。
由此可见,生成器完美地浮现了上帝创造数据的过程!
下面我们正式给出GAN训练算法流程,如下图所示。

我们不加证明地给出该算法的收敛性。
命题2. 假设G和D有足够的表达能力,并且假设算法1的每一步,给定G,D都可以达到最优,并且pg依照下面目标优化

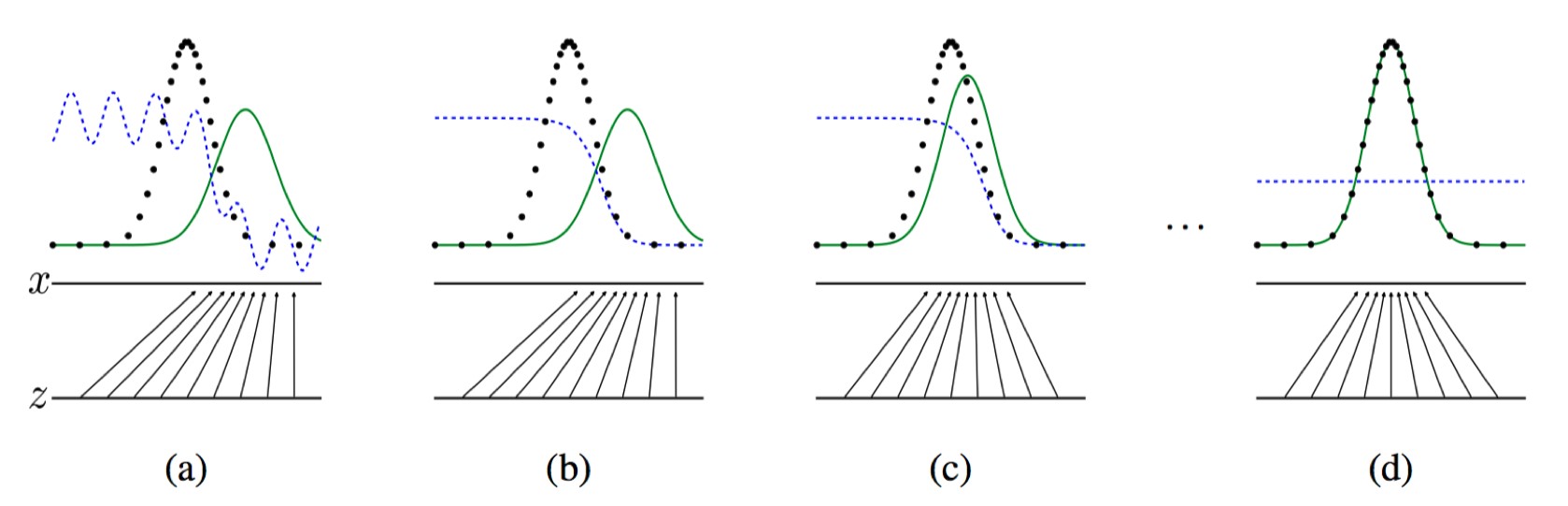
我们通过下面的示意图,可以更加直观地理解整个训练的过程。

实验效果
下面我们来欣赏一下伪装上帝的效果吧!

每张图的最右侧一栏是在训练集中的与生成样本的最近邻样本。可见,模型在没有记忆训练集的情况下生成了多样化的类似风格的图片。不像其他生成模型的可视化那样,这些图片都是由模型分布直接生成的,而不是利用条件概率的方法。并且,这些图片不像利用马尔科夫链采样过程那样所生成的图像之间是不相关的。(a)(b)(c)(d)依次是MNIST, TFD, CIFAR-10(全连接模型), CIFAR-10(卷积判别器和反卷积生成器)
附录
A. K-L散度
在概率论和信息论中,K-L散度,也称之为信息增益,是衡量两个概率分布差异的一种“度量”。我们首先给出K-L散度的定义。分为离散形式和连续形式。
对于离散形式,给定两个离散型随机变量所对应的概率函数P和Q,两者的K-L散度定义为
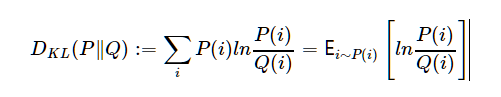
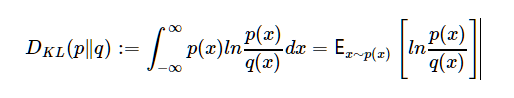
前置位,如定义式中的P(或p)可以理解为数据的真实分布,而Q(或q)是模型对真实分布的一种近似。另一种理解是,DKL(P∥Q)表示从先验Q到后验P带来的信息增益。
K-L散度有如下几个重要性质:
(1) K-L散度是具有良好定义的,当且仅当,当对于某些x, q(x)=0, 一定有p(x)=0;
(2) 对于某些x,当p(x)=0,一定有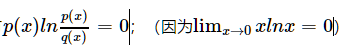
下面证明一下最后一条性质。

证毕。
B. 泛函变分
泛函变分实际上是函数微分的一种自然的推广。
对于给定泛函F[y]:y(x)↦K,其中K=R/C,我们可以仿照泰勒公式,定义泛函的展开形式,对于任意η(⋅),
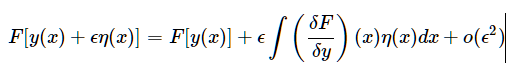
证明:
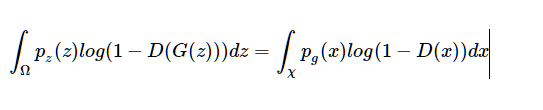
我们首先定义测度空间(Ω,F,P),其中Ω为z的样本空间,F为σ-代数。进一步,易证G(⋅)是可测函数:(Ω,F)↦(χ,G),其中χ为x的样本空间,G为χ的σ-代数。因此,我们有

证毕。
GAN背后的数学原理的更多相关文章
- 速算1/Sqrt(x)背后的数学原理
概述 平方根倒数速算法,是用于快速计算1/Sqrt(x)的值的一种算法,在这里x需取符合IEEE 754标准格式的32位正浮点数.让我们先来看这段代码: float Q_rsqrt( float nu ...
- opencv——PCA(主要成分分析)数学原理推导
引言: 最近一直在学习主成分分析(PCA),所以想把最近学的一点知识整理一下,如果有不对的还请大家帮忙指正,共同学习. 首先我们知道当数据维度太大时,我们通常需要进行降维处理,降维处理的方式有很多种, ...
- OpenGL坐标变换及其数学原理,两种摄像机交互模型(附源程序)
实验平台:win7,VS2010 先上结果截图(文章最后下载程序,解压后直接运行BIN文件夹下的EXE程序): a.鼠标拖拽旋转物体,类似于OGRE中的“OgreBites::CameraStyle: ...
- word2vec 数学原理
word2vec 是 Google 于 2013 年推出的一个用于获取词向量的开源工具包.我们在项目中多次使用到它,但囿于时间关系,一直没仔细探究其背后的原理. 网络上 <word2vec 中的 ...
- 浅议极大似然估计(MLE)背后的思想原理
1. 概率思想与归纳思想 0x1:归纳推理思想 所谓归纳推理思想,即是由某类事物的部分对象具有某些特征,推出该类事物的全部对象都具有这些特征的推理.抽象地来说,由个别事实概括出一般结论的推理称为归纳推 ...
- hover 背后的数学和图形学
前端开发中,hover是最常见的鼠标操作行为之一,用起来也很方便,CSS直接提供:hover伪类,js可以通过mouseover+mouseout事件模拟,甚至一些第三方库/框架直接提供了 hover ...
- RSA加密数学原理
RSA加密数学原理 */--> *///--> *///--> UP | HOME RSA加密数学原理 Table of Contents 1 引言 2 RSA加密解密过程 2.1 ...
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
随机推荐
- JS实现表格列宽拖动
在数据表格中,有时候需要拖动表格宽度,查看完整的数据,是很常用的功能. 1 效果 可以用纯JS就可以实现,如下,是正常情况下的表格: 拖动表格标题中间线,拖动后效果如下: 查看DEMO 2 代码 HT ...
- FZU_1894 志愿者选拔 【单调队列】
1 题面 FZU1894 2 分析 单调队列的典型引用 需要注意的是在用维护辅助队列的时候,$L$和$R$的初始化都是0时,队列第一个数就是$L$,最后一个数就是$R-1$. 3 AC代码 #incl ...
- springboot(十四)-分库分表-自动配置
上一节我们是手动配置数据源的,直接在java代码里写数据库的东西,这操作我个人是不喜欢的.我觉得这些东西就应该出现在application.yml文件中. 还有,万一我们的项目在使用之后,突然需要改变 ...
- 【Vue】环境搭建、项目创建及运行
一.软件下载 1. 进入官网https://nodejs.org/en/下周node.js,傻瓜式安装步骤(一直下一步就好) 2. 进入官网http://www.dcloud.io/下载并安装编辑器H ...
- 自定义 mapper
1. 定义一个接口 public interface ItemMapper { List<Item> getItemList(); } 2. 编写 xml 文件 , 将sql 语句填 ...
- Redis服务挂掉后,重启时闪退
这个时候去进程管理器里找一个 redisservice.exe 的进程..杀死他 杀死他 杀死他!!! 整理领结,嘬口咖啡, 嗯... 然后再来启动服务..
- 关于Java的权限修饰符(public,private,protected,默认friendly)
以前对访问修饰符总是模棱两可,让自己仔细解释也是经常说不很清楚.这次要彻底的搞清楚. 现在总结如下: 一.概括总结 各个访问修饰符对不同包及其子类,非子类的访问权限 Java访问权限修饰符包含四个:p ...
- python 脚本备份 mysql 数据库到 OSS
脚本如下: #!/usr/bin/python ########################################################### ################ ...
- split使用和特殊使用(包括截取第一个字符后的数据)
javaScript中关于split()的使用 1.一般使用对一个字符串使用split(),返回一个数组 例子: var testArr = "1,2,3,4,5": var ...
- windows下python2.7版本numpy,Scipy,matplotlib,sklearn安装
系统是windows32位,安装了python2.7.13. 安装顺序就是numpy,Scipy,matplotlib,sklearn. 首先是更新一下pip (确保pip能使用) 然后将setupt ...