Java实现的词频统计——单元测试
前言:本次测试过程中发现了几个未知字符,这里将其转化为十六进制码对其加以区分。
1)保存统计结果的Result文件中显示如图:

2)将其复制到eclipse环境下的切分方法StringTokenizer中却没有显示;
复制前:

复制后:

前后看似没有任何变化;
3)改动后的统计结果:
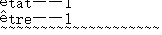
因此为了检测这个字符做了一个将其转化为十六进制码的小程序:
String t = "\0";
String s = "\0";
byte[] bbb = t.getBytes();
int[] n = new int[bbb.length];
for (int i = 0; i < n.length; i++) {
n[i] = bbb[i] & 0xff; //将每个字符的十六进制码保存到数组中
}
for (int j = 0; j < n.length; j++) {
System.out.println(Integer.toString(n[j], 0x10));
}
System.out.println("-----------------");
byte[] b = s.getBytes();
int[] in = new int[b.length];
for (int i = 0; i < in.length; i++) {
in[i] = b[i] & 0xff;
}
for (int j = 0; j < in.length; j++) {
System.out.println(Integer.toString(in[j], 0x10));
}
运行结果如下:

从结果可以看出,这个未知字符是由三个字符组成,而类似的难以识别的字符还有很多。
此外,在做单元测试之前还做了一项额外的测试——read()方法读取文件时单次读取的字符数量对效率的影响:
选取了从1-128、129-256、257-384、385-512四个范围,分别进行了测试。
总测试次数2560次,耗时10min左右,统计结果:
当取值在200左右时运行速率最快,平均值在210ms左右.
单元测试
对Java工程进行的单元测试,使用的工具为Eclipse集成的Juint4。
1.对FileProccessing类进行测试,测试其输出到控制台与输出到文件的结果与预期是否相同。Juint代码如下:
输出到控制台:这里用到了重定向输出,将要输出到控制台的字符串输出到缓冲区,并与预期结果进行比对。
@Test
public void testFP() throws Exception { final ByteArrayOutputStream outContent = new ByteArrayOutputStream();
System.setOut(new PrintStream(outContent)); //重定向输出,方便后面进行比对
new FileProccessing("content.txt", 200);
assertEquals(
"~~~~~~~~~~~~~~~~~~~~\r\ncontent\r\ntotals of the words:6\r\nquantity of vocabulary:5\r\nvery——2\r\nenglish——1\r\nis——1\r\nmy——1\r\npoor——1\r\n~~~~~~~~~~~~~~~~~~~~\r\n",
outContent.toString()); }
输出到文件:生成实例后分别建立两个文件流,一个读取实际结果文件,一个读取预期结果文件,通过循环逐行比对。
public void testFPtoFile() throws Exception{
new FileProccessing("E:\\Test3\\Test1.txt"); //测试文件
FileReader expect = new FileReader("E:\\Test3\\Expect.txt"); //用来保存期待的结果
BufferedReader ep= new BufferedReader(expect);
FileReader actual = new FileReader("Result.txt"); //实际的结果文件
BufferedReader at = new BufferedReader(actual);
String temp;
while((temp = at.readLine()) != null){
assertEquals(ep.readLine(),temp); //对文件中内容逐行比较
}
at.close();
actual.close();
ep.close();
expect.close();
}
用例截图:

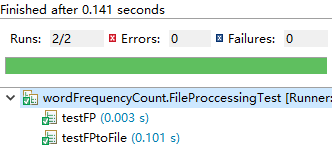
单元测试结果:
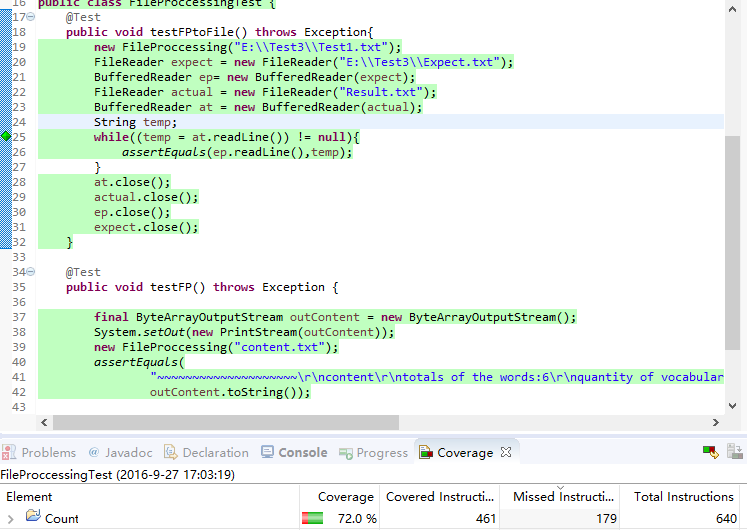
代码覆盖率:覆盖率为72%,未覆盖到的部分为主函数中为用户提供输入的代码段。
2.对于上面的测试用例进行改进,对main()函数不同情况的的输入输出进行测试。Juint代码如下,大致分为四种情况:
1>由命令行传入参数:
@Test
public void testMain1() throws Exception {
String[] test = { "E:\\Test3\\Test1.txt" };
WordFrequencyCount.main(test); //生成实例 FileReader expect = new FileReader("E:\\Test\\Expect.txt");
BufferedReader ep = new BufferedReader(expect);
FileReader actual = new FileReader("Result.txt");
BufferedReader at = new BufferedReader(actual); String temp;
while ((temp = at.readLine()) != null) {
assertEquals(ep.readLine(), temp);
} at.close();
actual.close();
ep.close();
expect.close();
}
2>传入参数为文件夹时:
@Test
public void testMain2() throws Exception {
String[] test = { "E:\\Test3" }; //文件夹中内容为Test1.txt
WordFrequencyCount.main(test); FileReader expect = new FileReader("E:\\Test\\Expect.txt");
BufferedReader ep = new BufferedReader(expect);
FileReader actual = new FileReader("Result.txt");
BufferedReader at = new BufferedReader(actual); String temp;
while ((temp = at.readLine()) != null) {
assertEquals(ep.readLine(), temp);
} at.close();
actual.close();
ep.close();
expect.close(); }
3>由控制台重定向输入:这里运用了重定向输入,并且将String转化为输入流。
@Test
public void testMain3() throws Exception {
String[] test = {};
String str = "< E:\\Test3\\Test1.txt\n";
ByteArrayInputStream instr = new ByteArrayInputStream(str.getBytes()); //将String转化为输入流 System.setIn(instr); //重定向输入
WordFrequencyCount.main(test); FileReader expect = new FileReader("E:\\Test\\Expect.txt");
BufferedReader ep = new BufferedReader(expect);
FileReader actual = new FileReader("Result.txt");
BufferedReader at = new BufferedReader(actual); String temp;
while ((temp = at.readLine()) != null) {
assertEquals(ep.readLine(), temp);
} at.close();
actual.close();
ep.close();
expect.close();
}
4>由控制台输入文件名及内容:这一部分使用了重定向输入和输出;由于main()函数中为了方便用户使用,会有输出作为引导,因此在比对时要把这部分输出也纳入考虑。
@Test
public void testMain4() throws Exception {
String[] test = {};
String str = "content\nMy English is very very poor.\n";
ByteArrayInputStream instr = new ByteArrayInputStream(str.getBytes()); System.setIn(instr); final ByteArrayOutputStream outContent = new ByteArrayOutputStream();
System.setOut(new PrintStream(outContent));
WordFrequencyCount.main(test);
assertEquals(
"请输入文件名:\r\n请输入内容,结尾以回车后ctrl+z结束:\r\n~~~~~~~~~~~~~~~~~~~~\r\ncontent\r\ntotals of the words:6\r\nquantity of vocabulary:5\r\nvery——2\r\nenglish——1\r\nis——1\r\nmy——1\r\npoor——1\r\n~~~~~~~~~~~~~~~~~~~~\r\ntime:1ms\r\n",
outContent.toString());
} //要考虑到main()函数中面向用户的输出
(为了方便测试,这一部分用例与之前相同,这里不再展示)
单元测试结果:

代码覆盖率:覆盖率为94%,加入了对于面向用户的输入输出的测试。仍有未覆盖到的代码,主要是抛出异常、异常处理、异常检测部分的代码。
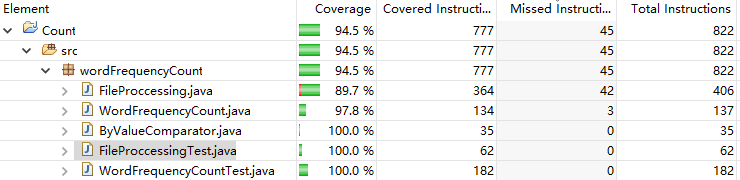
通过此次单元测试了解到:System.out.println()与System.out.print()方法差别不仅仅在于行末多了换行符\n,而是\r\n。同时通过这次单元测试发现了原程序中的bug:用read()方法读取文件时用来保存结果的char[]不会自动清空,而是以覆盖的方式读取字符,因此会导致统计结果有误。
代码地址:
HTTPS https://coding.net/u/regretless/p/WordFrequencyCount/git
SSH git@git.coding.net:regretless/WordFrequencyCount.git
GIT git://git.coding.net/regretless/WordFrequencyCount.git
Java实现的词频统计——单元测试的更多相关文章
- Java实现的词频统计——Web迁移
本次将原本控制台工程迁移到了web工程上,依旧保留原本控制台的版本. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息 ...
- Java实现的词频统计——功能改进
本次改进是在原有功能需求及代码基础上额外做的修改,保证了原有的基础需求之外添加了新需求的功能. 功能: 1. 小文件输入——从控制台由用户输入到文件中,再对文件进行统计: 2.支持命令行输入英文作品的 ...
- Java实现中文词频统计
昨日有个中文词频统计的需求, 百度一番后, 发现一大堆标题党文章, 讲的与内容严重不符, 这里就简单记录下自己实现的流程吧! 与英文单词的词频统计不同, 中文的难点在于如何分词, 不过好在有许多优秀的 ...
- Java实现的词频统计
要求: 1.读取文件: 2.记录出现的词汇及出现频率: 3.按照频率降序排列: 4.输出结果. 概要: 1.读取的文件路径是默认的,为了方便调试,将要统计的文章.段落复制到文本中即可:2.只支持英文: ...
- 【week3】词频统计 单元测试
使用Eclipse 集成的Junit进行单元测试.单元测试的核心包括断言.注解. 测试代码如下: @BeforeClass // 针对所有测试,只执行一次,且必须为static void public ...
- java词频统计——改进后的单元测试
测试项目 博客文章地址:[http://www.cnblogs.com/jx8zjs/p/5862269.html] 工程地址:https://coding.net/u/jx8zjs/p/wordCo ...
- 如何用java完成一个中文词频统计程序
要想完成一个中文词频统计功能,首先必须使用一个中文分词器,这里使用的是中科院的.下载地址是http://ictclas.nlpir.org/downloads,由于本人电脑系统是win32位的,因此下 ...
- 词频统计的java实现方法——第一次改进
需求概要 原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 ...
- 效能分析——词频统计的java实现方法的第一次改进
java效能分析可以使用JProfiler 词频统计处理的文件为WarAndPeace,大小3282KB约3.3MB,输出结果到文件 在程序本身内开始和结束分别加入时间戳,差值平均为480-490ms ...
随机推荐
- Python学习:19.Python设计模式-单例模式
一.单例模式存在的意义 在这里的单例就是只有一个实例(这里的实例就像在面向对象的时候,创建了一个对象也可以说创建了一个实例),只用一个实例进行程序设计,首先我们可以了解一下什么时候不适合使用单例模式, ...
- Python3 图像识别(二)
Infi-chu: http://www.cnblogs.com/Infi-chu/ 以图搜图的使用已经非常广泛了,我现在来介绍一下简单的以图搜图的相关算法及其实践. 一.感知hash算法 感知哈希算 ...
- Gulp的安装配置过程和一些小坑
谈谈gulp. 项目尾声,老师叫我去熟悉一下grunt前端自动化工具,第一次知道这种东西,我就查各种资料啊,发现grunt已经‘过时’了,大家都用gulp和webpack.我当然选择了配置最简单的gu ...
- 20155321 2016-2017-2 《Java程序设计》第四周学习总结
20155321 2016-2017-2 <Java程序设计>第四周学习总结 教材学习内容总结 第六.七章 继承 多态 接口 相应的语法细节 继承 关键字 extends 格式 class ...
- 《Java 程序设计》课堂实践二
题目 设计并实现一个Book类,定义义成Book.java,Book 包含书名,作者,出版社和出版日期,这些数据都要定义getter和setter.定义至少三个构造方法,接收并初始化这些数据.覆盖(O ...
- CH03 课下作业
CH03 课下作业 缓冲区溢出漏洞实验 缓冲区溢出攻击:通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,造成程序崩溃或使程序转而执行其它指令,以达到攻击的目的. 缓冲区溢出 ...
- 使用salt-ssh初始化系统安装salt-minion
salt-ssh介绍及使用方法 在ssh上执行salt命令和状态而不安装salt-minion,类似于ansible. 1. salt-ssh的安装: [root@linux-node1 ~]# yu ...
- C#:在AnyCPU模式下使用CefSharp
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 本篇博客讲述如何在AnyCPU模式下使用CefSharp 因为在某些情况下,不得不用AnyCPU,但是CefS ...
- 一个经典的PHP加密解密算法authcode
项目中有时我们需要使用PHP将特定的信息进行加密,也就是通过加密算法生成一个加密字符串,这个加密后的字符串可以通过解密算法进行解密,便于程序对解密后的信息进行处理.最常见的应用在用户登录以及一些API ...
- Hibernate5使用注解方式(转)
用Hibernate5使用映射文件时存在一个问题没有解决,在映射文件中配置了student_sequence,但找不到映射文件自增长的序列的sequence(Oracle)数据库. 输出的是 Hibe ...