cnn 经典网络结构 解析
cnn发展史
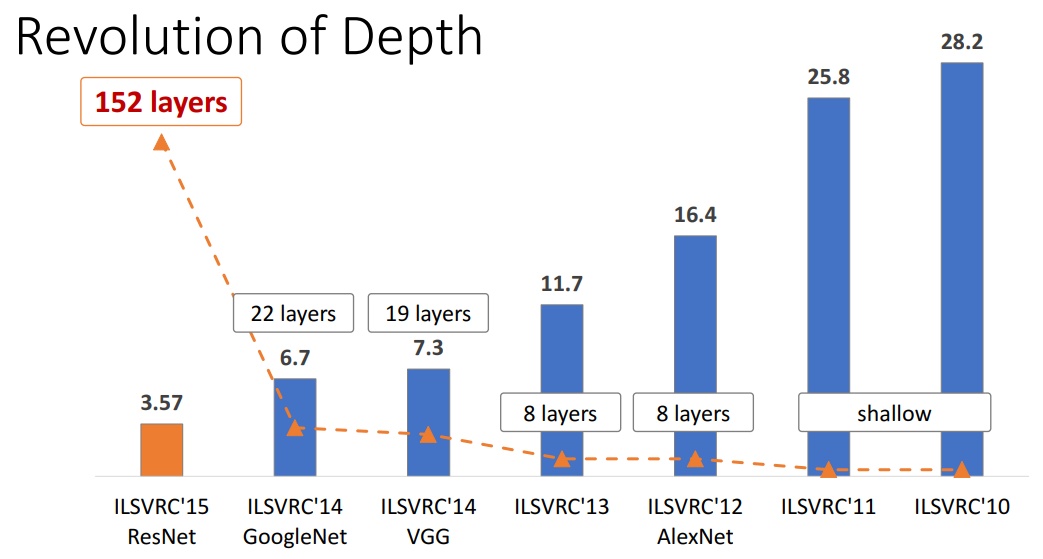
这是imageNet比赛的历史成绩
可以看到准确率越来越高,网络越来越深。
加深网络比加宽网络有效的多,这已是公认的结论。
cnn结构演化图
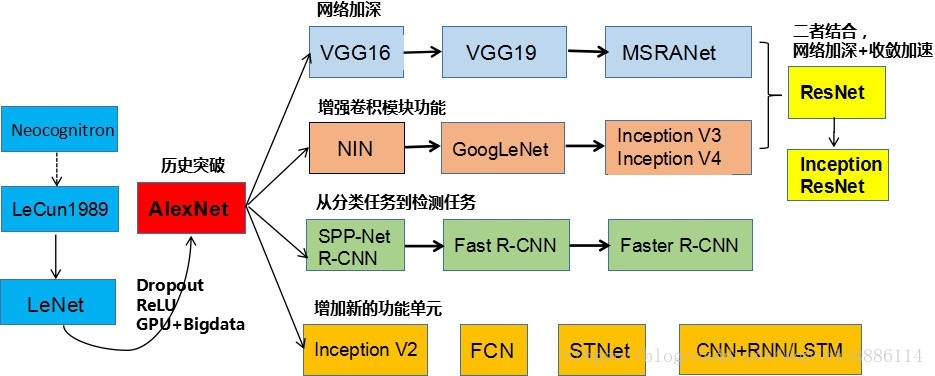
AlexNet
诞生于2012年,因为当时用了两个GPU(硬件设备差),所以结构图是2组并行
网络结构总共8层,5个卷积层,3个全连接层,最后输出1000个分类
分层结构图

简单解释如下:
conv1:输入为224x224x3,96个shape为11x11x3的卷积核,步长为4,输出55x55x96的特征图,(224-11)/4+1,paddig为valid,故等于55,relu,池化,池化视野3x3,步长为2,这个池化稍有不同,后面解释,然后,lrn,局部归一化,后面解释,输出27x27x96 (这里输入的224在卷积时计算不方便,后来改成了227)
conv2 conv3 conv4 conv5基本类似
fc6:将输出6x6x256展开成一维9216,接4096个神经元,输出4096个值,dropout,还是4096个值
fc7:写的有些问题,第一个框内应该是4096,不打紧
fc8:输出1000个类别
注意几点
1. 重叠池化:一般情况下,我们的池化视野和步长是一样的,但是这里池化视野大于步长,这样就有重叠,故称为重叠池化
2. 局部响应归一化:虽然relu不会梯度饱和,但是笔者认为lrn可以提高模型的泛化能力
AlexNet较之前网络的改进
1. 网络变深
2. relu激活函数
3. 数据增强
通俗理解就是准备更多更全的数据
// 法1:平移图像和水平翻转图像,从原始的256x256的图像中随机提取227x227的块,并且水平翻转,作为训练数据
// 法2:改变训练图像的RGB通道的强度。特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。
4. dropout
// 以一定的概率将神经元的输出置为0,就是忽略该神经元的存在,既不前向传递,也不反向传播,这是AlexNet很大的一个创新。
数据增强和dropout都是防止过拟合的。
VGG
诞生于2014年

上图是VGG16--黑色框+蓝色框=16

上图为VGG19
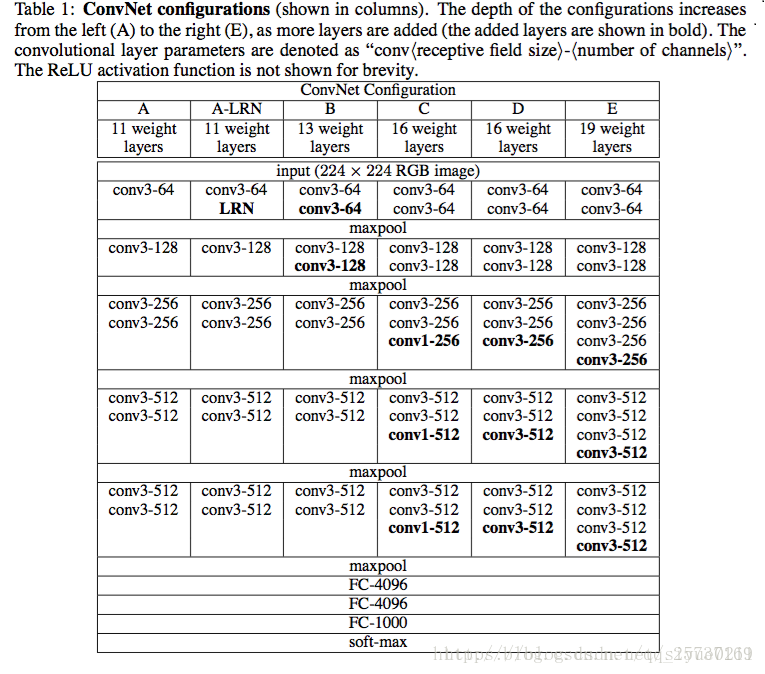
VGG共有6种结构,常用的是D和E,即VGG16和VGG19
VGG网络结构非常规则,共分为5组卷积,每组卷积都使用3x3的卷积核,卷积后都使用2x2的max池化,最后接3个全连接
可以看到C网络的最后3个卷积使用了1x1的卷积,这是什么意思呢?
1x1的卷积其实是对特征的线性变换,主要用来综合特征,这个方法后来被推广解决多种问题。
VGG的优点
1. 使用较小的卷积核,使得参数更少,网络更深
2. 卷积层的堆叠,这样做一可以保证感受视野,即2个3x3的感受野堆叠相当于一个5x5,二是经过多个非线性转换,提取特征的能力更强
3. VGG在训练时,先训练简单的如A网络,然后用A网络的参数(卷积和全连接)初始化后面的复杂网络,更快收敛
4. VGG认为lrn作用不大,去掉了lrn
VGG虽然网络更深,但比AlexNet收敛更快
缺点是占用内存较大
VGG的数据处理
1. 数据标准化
2. 数据增强采用Multi-Scale方法。将原始图像缩放到不同尺寸S,然后再随机裁切224′224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。
VGG16的卷积代码
conv1_1 = self._conv_layer(x, 3, 64, "conv1_1")
conv1_2 = self._conv_layer(conv1_1, 64, 64, "conv1_2")
pool1 = self._max_pool(conv1_2, "pool1") conv2_1 = self._conv_layer(pool1, 64, 128, "conv2_1")
conv2_2 = self._conv_layer(conv2_1, 128, 128, "conv2_2")
pool2 = self._max_pool(conv2_2, "pool2") conv3_1 = self._conv_layer(pool2, 128, 256, "conv3_1")
conv3_2 = self._conv_layer(conv3_1, 256, 256, "conv3_2")
conv3_3 = self._conv_layer(conv3_2, 256, 256, "conv3_3")
pool3 = self._max_pool(conv3_3, "pool3") conv4_1 = self._conv_layer(pool3, 256, 512, "conv4_1")
conv4_2 = self._conv_layer(conv4_1, 512, 512, "conv4_2")
conv4_3 = self._conv_layer(conv4_2, 512, 512, "conv4_3")
pool4 = self._max_pool(conv4_3, "pool4") conv5_1 = self._conv_layer(pool4, 512, 512, "conv5_1")
conv5_2 = self._conv_layer(conv5_1, 512, 512, "conv5_2")
conv5_3 = self._conv_layer(conv5_2, 512, 512, "conv5_3")
pool5 = self._max_pool(conv5_3, "pool5")
GoogleNet
诞生于2014年,和VGG一同出道,当时是第一名,VGG是第二名,但因其结构复杂,所以没有VGG更常用。
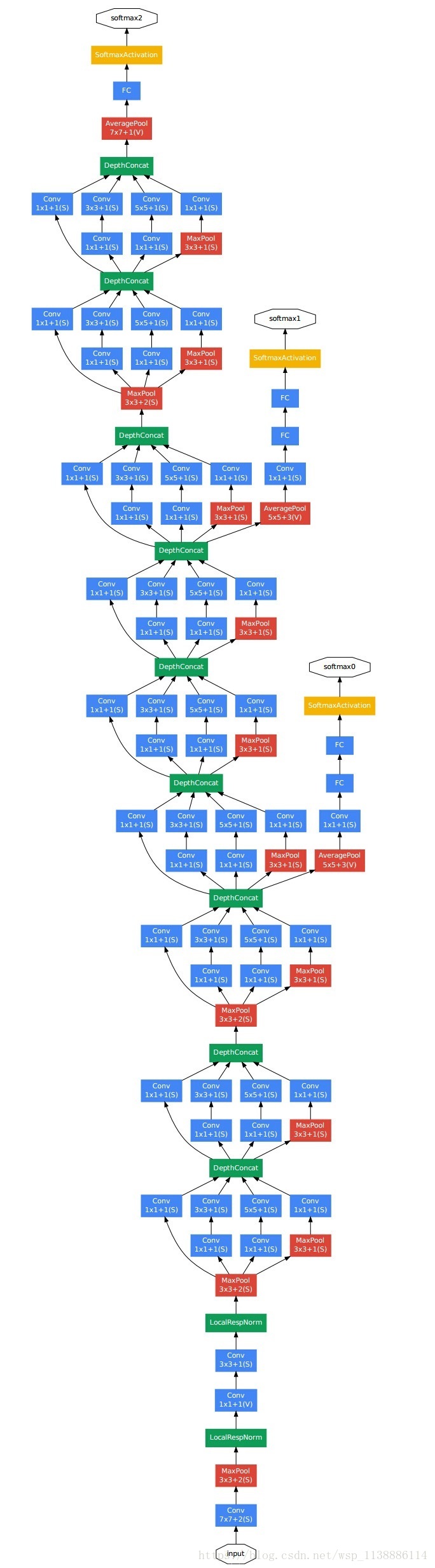
网络太过复杂,不多解释了,这个网络估计也很少被用到。
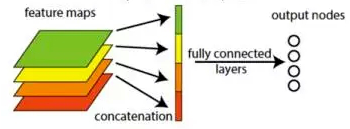
但是 googlenet 有个很大的创新点,并且被后来很多网络借鉴,就是 global average pooling
global average pooling 一般放在网络最后,替代全连接层。
因为全连接层参数太多,占整个模型参数的比例可以高达90%左右,很难训练,而且参数太多,没有合适的正则化方法,很容易过拟合
global average pooling 做法很简单,就是对每个feature map取全局average,然后每个feature变成了一个数,然后最后接了一个 输出层fc网络
为什么这样,我以后会讲
ResNet
ResNet就借鉴了上面的global average pooling
详见我的博客 https://www.cnblogs.com/yanshw/p/10576354.html
参考资料:
https://blog.csdn.net/Sakura55/article/details/81559881
https://blog.csdn.net/siyue0211/article/details/80092531
https://blog.csdn.net/xbinworld/article/details/61210499
https://blog.csdn.net/ziyouyi111/article/details/80546500 vgg16结构图
https://blog.csdn.net/loveliuzz/article/details/79080194 cnn结构详细教程
https://blog.csdn.net/dcrmg/article/details/79254654 vgg网络结构
cnn 经典网络结构 解析的更多相关文章
- 大话CNN经典模型:AlexNet
2012年,Alex Krizhevsky.Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LS ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- 大话CNN经典模型:VGGNet
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC20 ...
- 大话CNN经典模型:LeNet
近几年来,卷积神经网络(Convolutional Neural Networks,简称CNN)在图像识别中取得了非常成功的应用,成为深度学习的一大亮点.CNN发展至今,已经有很多变种,其中有 ...
- CNN经典模型VGG
VGG是一个很经典的CNN模型,接触深度学习的人大概都有所耳闻.VGG在2014年被提出并拿来参加ImageNet挑战赛,最终实现了92.3%的正确率,得到了当年的亚军.虽然多年过去,又有很多新模型被 ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
- Genetic CNN: 经典NAS算法,遗传算法的标准套用 | ICCV 2017
论文将标准的遗传算法应用到神经网络结构搜索中,首先对网络进行编码表示,然后进行遗传操作,整体方法十分简洁,搜索空间设计的十分简单,基本相当于只搜索节点间的连接方式,但是效果还是挺不错的,十分值得学习 ...
- JS经典题目解析
此次列举出一些觉得有意思的JS题目(来源于出了名的44题),相信有非常多关于这些题目的博客,写这篇博客的目的在于巩固一些知识点,希望能和读者共同进步. 1. map函数执行过程 ["1&qu ...
随机推荐
- android -------- Eclipse下的NDK配置环境
NDK 全称是Native Development Kit,是一个让开发人员在Android应用中嵌入使用本地代码编写的组件的工具集 原生开发工具包 (NDK) 是一组可让您在 Android 应用中 ...
- Confluence 6 从一个模板中创建一个空间
Confluence 已经存储了一系列的模板,这些模板被称为 空间蓝图(space blueprints),这模板具有一些自定义的主页,边栏或者可能有蓝图页面或一些示例内容来帮助你开始使用 Confl ...
- Mysql中Join用法及优化
Join的几种类型 笛卡尔积(交叉连接) 如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录.在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者直接用f ...
- Weighted Channel Dropout for Regularization of Deep Convolutional Neural Network
这是AAAI2019的一篇论文,主要是为了解决小数据集的过拟合问题,使用了针对于卷积层的Dropout的方法. 论文的要点记录于下: 1.在训练过程中对于卷积层的channels进行droipout, ...
- 串的模式匹配算法 ------ KMP算法
//KMP串的模式匹配算法 #include <stdio.h> #include <stdlib.h> #include <string.h> int* get_ ...
- [CodeForces - 197F] F - Opening Portals
F - Opening Portals Pavel plays a famous computer game. A player is responsible for a whole country ...
- ActiveMQ 事务和XA
1. 客户端怎样显式地使用事务? producer 开启事务(代码片段): ActiveMQSession session = (ActiveMQSession)connection.createSe ...
- git reset --hard 恢复
git reset --hard ,再然后,悲剧上演~ 恢复方法: 使用 git reflog 来找到最近提交的信息,这里贴出部分信息: F:\voidy>git reflog WARNING: ...
- 漫谈moosefs中cgi各项的意义
原创:http://www.cnblogs.com/bugutian/p/6869278.html 转载请注明出处 一.先上一张图 二.解释 1. Metadata Servers (masters) ...
- JavaScript 上万条数据 导出Excel文件 页面卡死
最近项目要js实现将数据导出excel文件,网上很多插件实现~~那个开心呀,谁知道后面数据量达到上万条时出问题:浏览器不仅卡死,导出的excel文件一直提示网络失败.... debug调试发现var ...