零基础Python爬虫实现(百度贴吧)
提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记。
目标
http://tieba.baidu.com/f?kw=linux&ie=utf-8
网站结构
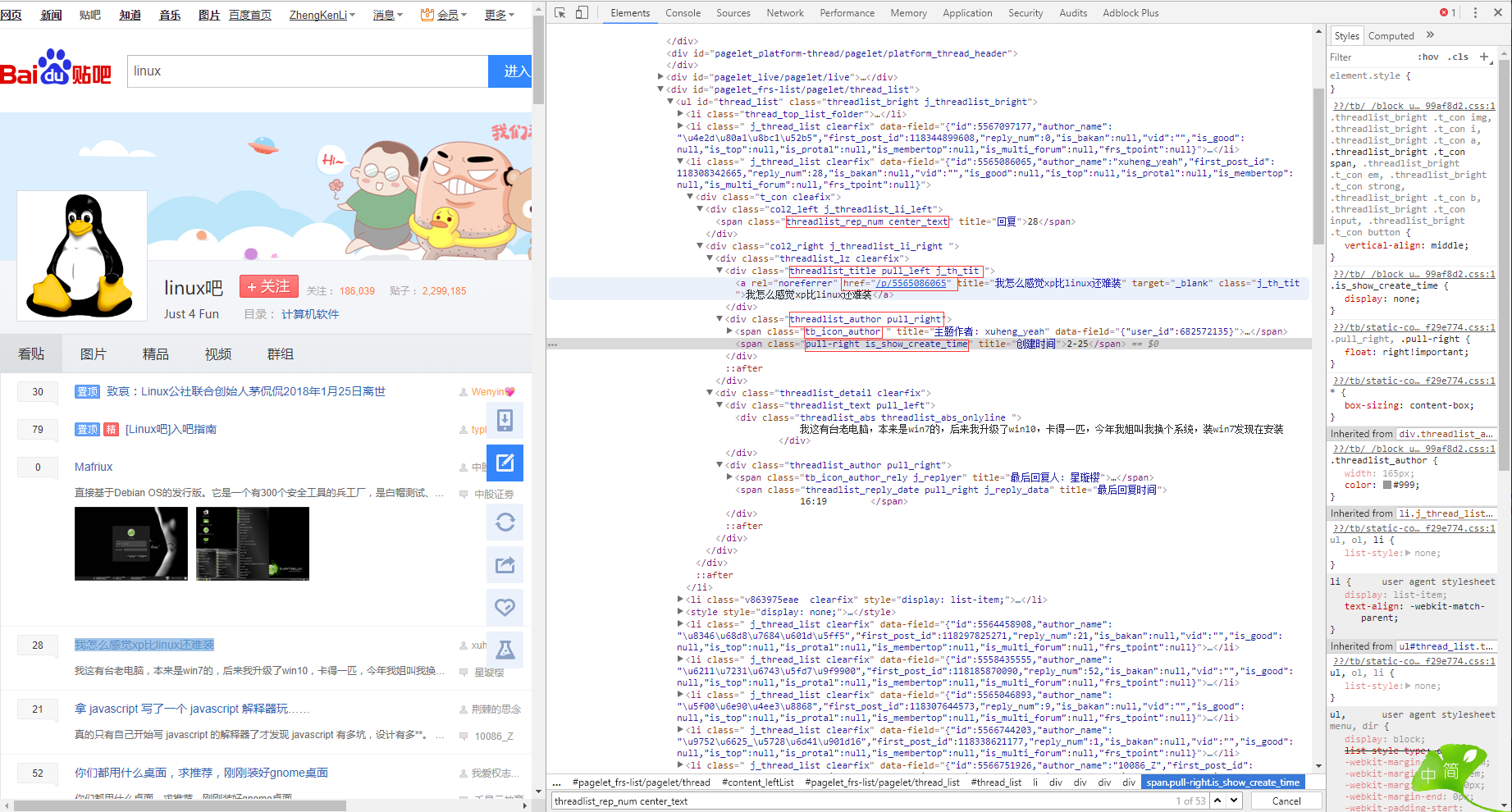
学习目标
由于是第一个实验性质爬虫,我们要做的不多,我们需要做的就是: 1. 从网上爬下特定页码的网页
2. 对于爬下的页面内容进行简单的筛选分析
3. 找到每一篇帖子的 标题、发帖人、日期、楼层、以及跳转链接
4. 将结果保存到文本。
发现规律
&pn=0 : 首页
&pn=50: 第二页
&pn=100:第三页
&pn=50*n 第n页
50 表示 每一页都有50篇帖子。
这样就能实现翻页操作
附上代码
import requests
import time from bs4 import BeautifulSoup def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() r.encoding = 'utf-8'
return r.text
except:
return "error" def get_content(url):
comments = []
html = get_html(url) soup = BeautifulSoup(html, 'lxml')
liTags = soup.find_all('li', attrs={'class':' j_thread_list clearfix'}) for li in liTags:
comment = {}
try:
#标题
comment['title'] = li.find(
'a', attrs={'class':'j_th_tit '}).text.strip()
#链接
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class' : 'j_th_tit'})['href']
#发帖人
comment['name'] = li.find(
'span', attrs = {'class':'tb_icon_author '}
).text.strip()
#发帖时间
comment['time'] = li.find(
'span', attrs={'class':'pull-right is_show_create_time'}
).text.strip()
#回复数量
comment['replyNum'] = li.find(
'span', attrs={'class':'threadlist_rep_num center_text'}
).text.strip()
comments.append(comment)
except:
print("出了点小问题")
return comments def Out2File(dict):
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} \t 连接: {} \t 发帖人: {} \t 发帖时间: {} \t 回复数量: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']
))
print("当前页面爬取完成") def main(base_url, deep):
url_list = []
for i in range(0, deep):
url_list.append(base_url + '&pn' + str(50 * i))
print("所有的网页已经下载到本地! 开始筛选信息") for url in url_list:
content = get_content(url)
Out2File(content)
print("所有的信息都已经保存完毕") base_url = 'http://tieba.baidu.com/f?kw=linux&ie=utf-8'
deep = 3 if __name__ == '__main__':
main(base_url, deep)
结果


零基础Python爬虫实现(百度贴吧)的更多相关文章
- 零基础Python爬虫实现(爬取最新电影排行)
提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记. 目标网站 http://dianying.2345.com/top/ 网站结构 要爬的部分,在ul标签下(包括li标签), 大致来说迭代li ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av15123607/?from=search&seid=10211084839195730432#page=25 中的42-45讲 {字典}
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av15123607/?from=search&seid=1021108 ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=15873837810484552531 中的15-23讲
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=1587383 ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=15873837810484552531 中的1-14讲
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=1587383 ...
- 零基础Python应该怎样学习呢?(附视频教程)
Python应该怎样学习呢? 阶段一:适合自己的学习方式 对于零基础的初学者来说,最迷茫的是不知道怎样开始学习?那这里小编建议可以采用视频+书籍的方式进行学习.看视频学习可以让你迅速掌握编程的基础语法 ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- python爬虫获取百度图片(没有精华,只为娱乐)
python3.7,爬虫技术,获取百度图片资源,msg为查询内容,cnt为查询的页数,大家快点来爬起来.注:现在只能爬取到百度的小图片,以后有大图片的方法,我会陆续发贴. #!/usr/bin/env ...
- 【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)
一.爬虫基础 1.爬虫概念 网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本.用爬虫最大的好出是批量且自动化得获取和处理信息.对于宏观或微观的情况都可以多一个侧面去了 ...
- 零基础Python接口测试教程
目录 一.Python基础 Python简介.环境搭建及包管理 Python基本语法 基本数据类型(6种) 条件/循环 文件读写(文本文件) 函数/类 模块/包 常见算法 二.接口测试快速实践 简单接 ...
随机推荐
- shell编程:for循环
有几个参数执行几次 do done取代了{} 这种用于 文件的个数,用户的个数等. (())里才可以进行加减乘除.
- Linux 安装Eclipse
安装Eclipse 场景: 我用的是笔记本(Windows系统),我在笔记本上安装了虚拟机,在 虚拟机中安装了Linux系统,使用的镜像是:CentOS-6.6-x86_64-bin-DVD1.iso ...
- python3学习笔记之安装
一.Python安装 1.下载地址: https://www.python.org/downloads/release/python-365/ 2. Linux系统自带Python2.7,如需安装3 ...
- html常用文本标签(转)
内容一<br />内容二 让文本强制换行 内容一内容二 <p>段落一</p><p>段落二</p> 段落标签 段落一 段落二 <b> ...
- 软工网络15团队作业4——Alpha阶段敏捷冲刺4.0
软工网络15团队作业4--Alpha阶段敏捷冲刺4.0 1.每天举行站立式会议,提供当天站立式会议照片一张. 2.项目每个成员的昨天进展.存在问题.今天安排. 成员 昨天已完成 今天计划完成 郭炜埕 ...
- Python 3 -- 数据结构(list, dict, set,tuple )
看了<Head First Python>后,觉得写的很不错,适合新手.此处为读书笔记,方便日后查看. Python 提供了4中数据结构:list,dict,set,tuple. 每种结构 ...
- 20155228 2017-5-10 课堂测试:MySort
20155228 2017-5-10 课堂测试:MySort 题目和要求 模拟实现Linux下Sort-t:-k2的功能.参考Sort的实现.提交码云链接和代码运行截图. import java.ut ...
- CocoaPod 问题(I)
问题一 报错:_OBJC_CLASS_$_ 方案:https://blog.csdn.net/duxinfeng2010/article/details/8265273 问题二: [!] Oh no, ...
- 【Elasticsearch学习之一】Elasticsearch
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 一.概念ElasticSearch: 基于Lucene全文搜 ...
- arm cortex-m0plus源码学习(二)AMBA3.0_ AHBLite
1. AMBA总线概述 AMBA2.0 以上版本都是基于单沿时钟.单向信号线的协议[1]. 现在市场上大部分的基于 AMBA 架构的 SoC 产品, 系统总线采用 AHB, 外部总线采用 APB.系统 ...