【消息队列】kafka是如何保证高可用的
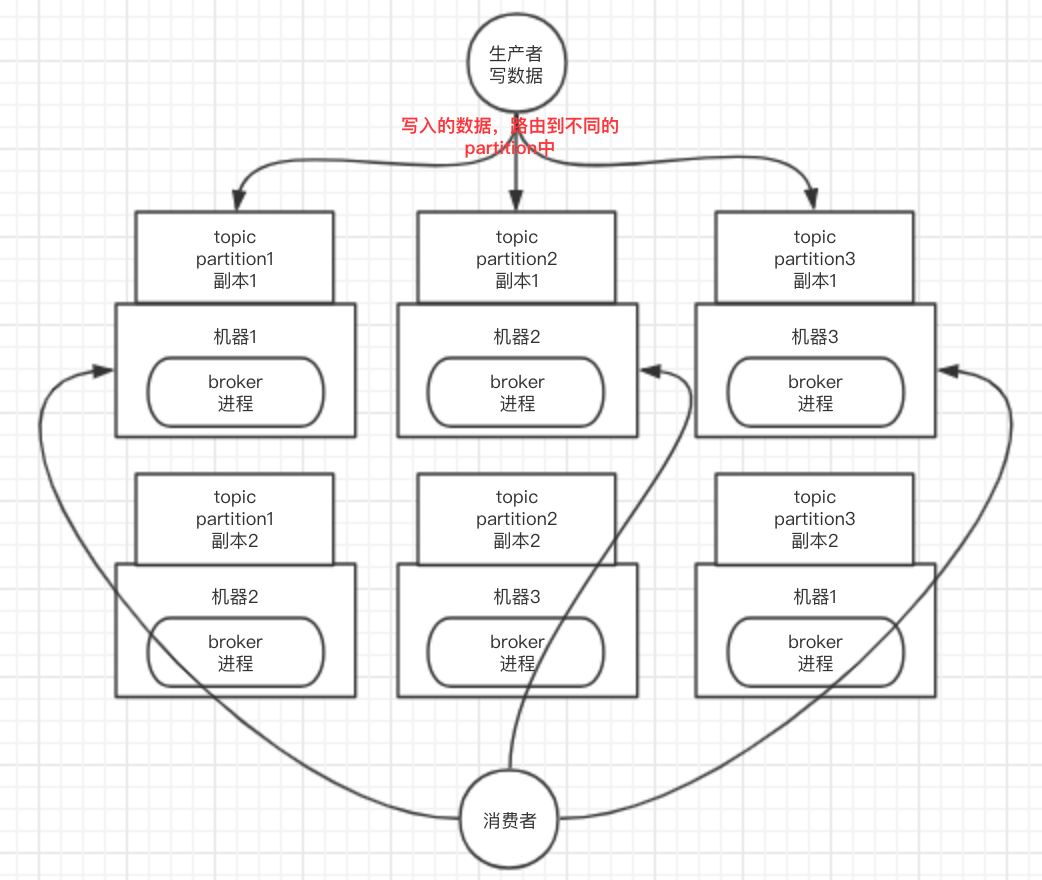
一、kafka一个最基本的架构认识
由多个broker组成,每个broker就是一个节点;创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition存放放一部分数据。
kafka就是一个分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上像rabbitmq之类的,并不是分布式消息队列,它只是传统的消息队列,只不过提供了一些集群、HA的机制而已,因为rabbitmq的一个queue的数据都是放在一个节点里的,镜像集群下,也是每个节点都存放这个queue的完整数据。
二、kafka高可用机制
kafka 0.8以前,是没有HA机制的,就是任何一个broker宕机了,那个broker上的partition就废了,没法写也没法读,没有什么高可用性可言。
kafka 0.8以后,提供了HA机制,就是replica副本机制。每个partition的数据都会同步到其他机器上,形成自己的多个replica副本。然后所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,然后其他replica就是follower。写的时候,leader会负责把数据同步到所有follower上去,读的时候就直接读leader上数据即可。只能读写leader?很简单,要是你可以随意读写每个follower,那么就要care数据一致性的问题,系统复杂度太高,很容易出问题。kafka会均匀的将一个partition的所有replica分布在不同的机器上,这样才可以提高容错性。
kafka的这种机制,就有所谓的高可用性了,因为如果某个broker宕机了,也没事儿,因为那个broker上面的partition在其他机器上都有副本的,那么此时会重新选举一个新的leader出来,大家继续读写那个新的leader即可。这就有所谓的高可用性了。
1)写过程
写数据的时候,生产者就写leader,然后leader将数据落地写本地磁盘,接着其他follower自己主动从leader来pull数据。一旦所有follower同步好数据了,就会发送ack给leader,leader收到所有follower的ack之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
2)读过程
消费的时候,只会从leader去读,但是只有当一个消息已经被所有follower都同步成功并返回ack的时候,这个消息才能够被消费者读到。
题外话: RabbitMQ的高可用性
RabbitMQ是比较有代表性的,因为是基于主从做高可用性的;
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
1.单机模式
demo级别,生产不能用单机模式。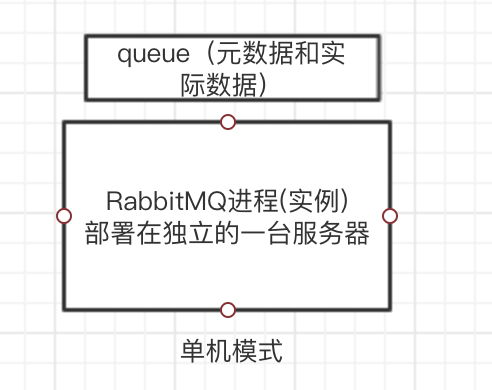
2.普通集群模式
就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会存放在一个rabbtimq实例上,但是每个实例都同步queue的元数据。实际上如果连接到了另外一个实例,那么那个实例会从真正存有数据的queue所在实例上拉取数据过来。
没做到所谓的分布式,就是个普通集群。该方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。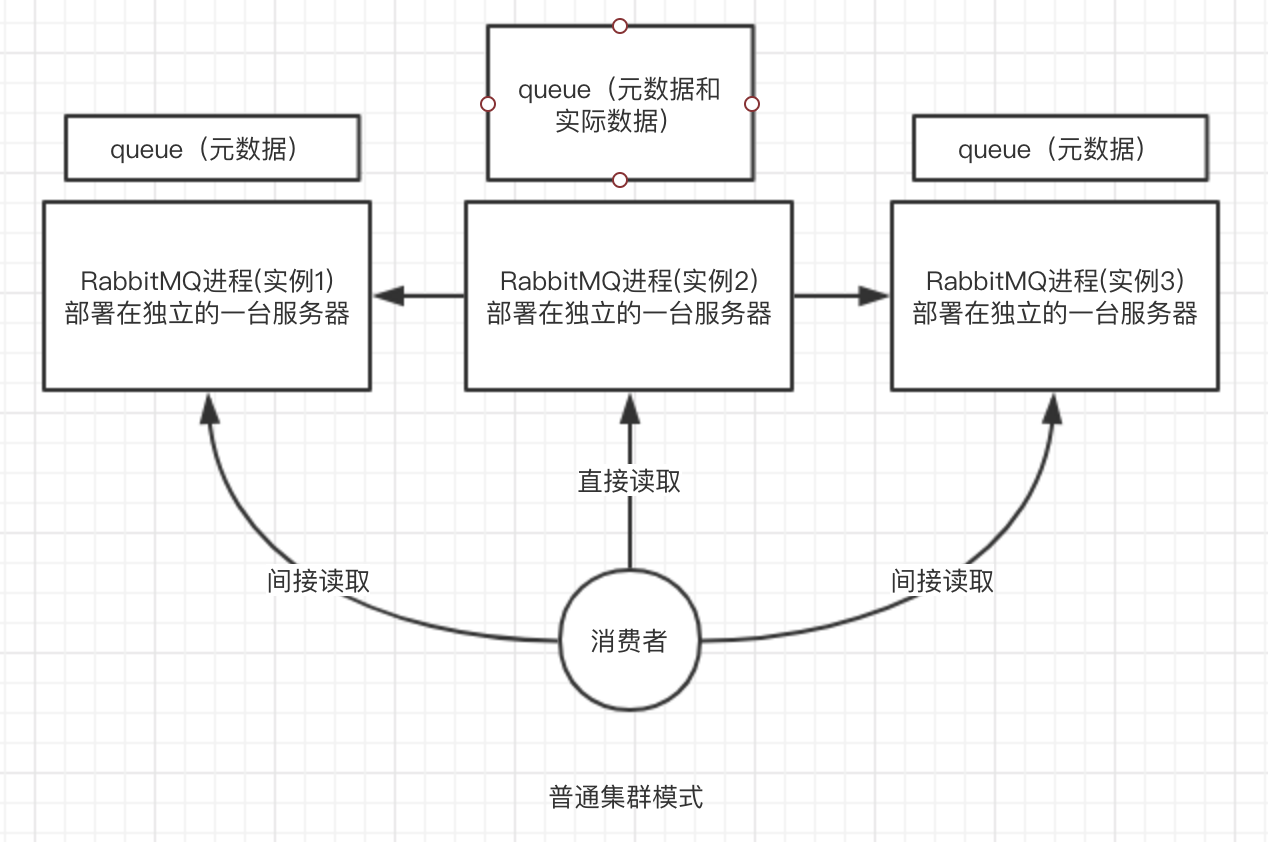
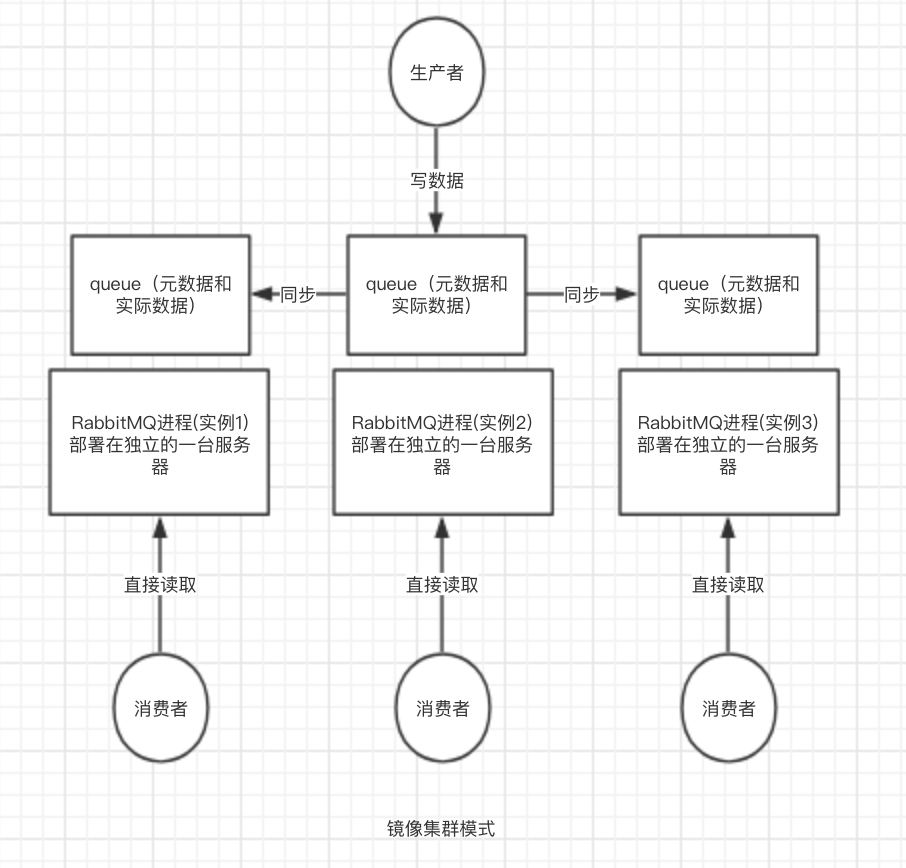
3.镜像集群模式
这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
【消息队列】kafka是如何保证高可用的的更多相关文章
- 消息队列kafka
消息队列kafka 为什么用消息队列 举例 比如在一个企业里,技术老大接到boss的任务,技术老大把这个任务拆分成多个小任务,完成所有的小任务就算搞定整个任务了. 那么在执行这些小任务的时候,可能 ...
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
- Kafka学习笔记-如何保证高可用
一.术语 1.1 Broker Kafka 集群包含一个或多个服务器,服务器节点称为broker. broker存储topic的数据. 如果某topic有N个partition,集群有N个broker ...
- kafka为什么吞吐量高,怎样保证高可用
1:kafka可以通过多个broker形成集群,来存储大量数据:而且便于横向扩展. 2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向l ...
- 分布式消息队列kafka
下载地址:http://kafka.apache.org/downloads.html 先启动zookeeper服务器 bin/zookeeper-server-start.sh config/zoo ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- 基于Docker搭建分布式消息队列Kafka
本文基于Docker搭建一套单节点的Kafka消息队列,Kafka依赖Zookeeper为其管理集群信息,虽然本例不涉及集群,但是该有的组件都还是会有,典型的kafka分布式架构如下图所示.本例搭建的 ...
- Kafka 消息队列系列之分布式消息队列Kafka
介绍 ApacheKafka®是一个分布式流媒体平台.这到底是什么意思呢?我们认为流媒体平台具有三个关键功能:它可以让你发布和订阅记录流.在这方面,它类似于消息队列或企业消息传递系统.它允许您以容 ...
- 消息队列——kafka
原文:再过半小时,你就能明白kafka的工作原理了 会出现什么情况呢? 1.为了这个女朋友,我请假回去拿(老板不批). 2.小哥一直在你楼下等(小哥还有其他的快递要送). 3.周末再送(显然等不及). ...
随机推荐
- css-过渡
css过渡:元素从一种样式逐渐改变为另一种的效果.过渡所需的条件:1.所过渡的元素必须有css样式.2.必须有过渡时间.以下是过渡元素的属性:transition:简写属性,用于在一个属性中设置四个过 ...
- CentOS7学习记录(工具使用篇)
一. 远程连接终端中文乱码:如xShell 检查当前系统语言:echo $LANG 查看系统安装语言包:locale ,如果包含zh_CN.UTF-8表示已经安装中文语言.如果没有中文包,使用命令 ...
- Restful framework【第十二篇】版本控制
简单使用 -drf版本控制 -在setting中配置 'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值) 'ALLOWED_VERSIONS' ...
- ubuntu upgrade
升级命令 虽然 apt-get 经常被人诟病,但实际上它还是个挺好用的软件包管理器.在 Ubuntu 14.04 以后的系统中,apt-get 相关的升级更新命令有四个: apt-get update ...
- html 之 position 绝对定位与相对定位(待补充)
相对定位:对于区块标签而言,占着原有的空间 绝对定位:对于网页而言,不占原来的空间
- HIHOcoder 1466 后缀自动机六·重复旋律9
思路 后缀数组+博弈论的好题,首先对两个串都建出SAM,然后题目的要求实际上就是在SAM的trans上转移即可 DAG的博弈是经典问题,然后dfs求出SG函数,两个游戏的组合就是把SG函数异或起来,异 ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- (zhuan) Deep Deterministic Policy Gradients in TensorFlow
Deep Deterministic Policy Gradients in TensorFlow AUG 21, 2016 This blog from: http://pemami49 ...
- 中文目录对 sublime text 有什么影响?
用了这软件好几个月了,一直没出现问题.最近做精简时,发现一个奇怪的问题. 相同的配置,为什么两个程序表现得不一样? 难道是哪里的配置不一样? 难道是插件被我精简得太厉害了? 难道是插件有依赖文件被我删 ...
- Git 分支 - 远程分支
Git 分支 - 远程分支 远程分支 远程分支(remote branch)是对远程仓库中的分支的索引.它们是一些无法移动的本地分支:只有在 Git 进行网络交互时才会更新.远程分支就像是书签,提醒着 ...