selenium及webdriver的原理【转】
selenium与webdriver整合后,形成的新的测试工具叫做selenium2.x。在selenium1时间,selenium使用javascript来达到测试自动化的目标。
1. selenium RC
早期的Selenium使用的是Javascript注入技术与浏览器打交道,需要Selenium RC启动一个Server,将操作Web元素的API调用转化为一段段Javascript,在Selenium内核启动浏览器之后注入这段Javascript。开发过Web应用的人都知道,Javascript可以获取并调用页面的任何元素,自如的进行操作。由此才实现了Selenium的目的:自动化Web操作。这种Javascript注入技术的缺点是速度不理想,而且稳定性大大依赖于Selenium内核对API翻译成的Javascript质量高低。
2. WebDriver
当Selenium2.x 提出了WebDriver的概念之后,它提供了完全另外的一种方式与浏览器交互。那就是利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)。由于使用的是浏览器原生的API,速度大大提高,而且调用的稳定性交给了浏览器厂商本身,显然是更加科学。然而带来的一些副作用就是,不同的浏览器厂商,对Web元素的操作和呈现多少会有一些差异,这就直接导致了Selenium WebDriver要分浏览器厂商不同,而提供不同的实现。例如Firefox就有专门的FirefoxDriver,Chrome就有专门的ChromeDriver等等。(甚至包括了AndroidDriver和iOS WebDriver)
WebDriver Wire协议是通用的,也就是说不管是FirefoxDriver还是ChromeDriver,启动之后都会在某一个端口启动基于这套协议的Web Service。例如FirefoxDriver初始化成功之后,默认会从http://localhost:7055开始,而ChromeDriver则大概是http://localhost:46350之类的。接下来,我们调用WebDriver的任何API,都需要借助一个ComandExecutor发送一个命令,实际上是一个HTTP request给监听端口上的Web Service。在我们的HTTP request的body中,会以WebDriver Wire协议规定的JSON格式的字符串来告诉Selenium我们希望浏览器接下来做社么事情。
在我们new一个WebDriver的过程中,Selenium首先会确认浏览器的native component是否存在可用而且版本匹配。接着就在目标浏览器里启动一整套Web Service,这套Web Service使用了Selenium自己设计定义的协议,名字叫做The WebDriver Wire Protocol。这套协议非常之强大,几乎可以操作浏览器做任何事情,包括打开、关闭、最大化、最小化、元素定位、元素点击、上传文件等等等等。
这里笔者初步画了一个图来表示各种WebDriver的工作原理:
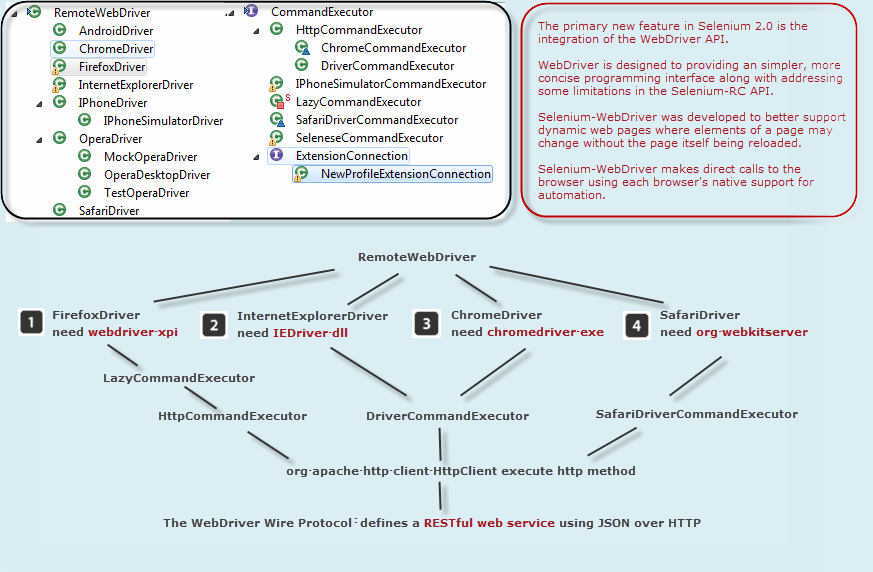
从上图中我们可以看出,不同浏览器的WebDriver子类,都需要依赖特定的浏览器原生组件,例如Firefox就需要一个add-on名字叫webdriver.xpi。而IE的话就需要用到一个dll文件来转化Web Service的命令为浏览器native的调用。另外,图中还标明了WebDriver Wire协议是一套基于RESTful的web service。如果不明白什么是RESTful的,可以参见笔者之前另外一篇介绍REST的blog(http://blog.csdn.net/ant_yan/article/details/7963517)
关于WebDriver Wire协议的细节,比如希望了解这套Web Service能够做哪些事情,可以阅读Selenium官方的协议文档, 在Selenium的源码中,我们可以找到一个HttpCommandExecutor这个类,里面维护了一个Map<String, CommandInfo>,它负责将一个个代表命令的简单字符串key,转化为相应的URL,因为REST的理念是将所有的操作视作一个个状态,每一个状态对应一个URI。所以当我们以特定的URL发送HTTP request给这个RESTful web service之后,它就能解析出需要执行的操作。截取一段源码如下:
可以看到实际发送的URL都是相对路径,后缀多以/session/:sessionId开头,这也意味着WebDriver每次启动浏览器都会分配一个独立的sessionId,多线程并行的时候彼此之间不会有冲突和干扰。例如我们最常用的一个WebDriver的API,getWebElement在这里就会转化为/session/:sessionId/element这个URL,然后在发出的HTTP request body内再附上具体的参数比如by ID还是CSS还是Xpath,各自的值又是什么。收到并执行了这个操作之后,也会回复一个HTTP response。内容也是JSON,会返回找到的WebElement的各种细节,比如text、CSS selector、tag name、class name等等。以下是解析我们说的HTTP response的代码片段:
相信总结道这里,应该对WebDriver的运行原理应该清楚了!其实挺佩服这一套RESTful web service的设计。感觉封装WebDriver暴露出来的public API还可以更加友好跟强大一点,这次就先总结道这里,会继续分析Selenium源码,继续分享的!
3. 使用selenium2.x的经验总结
其中WebDriver的更加面向对象的方式大大降低了Selenium的入门门槛,对Web元素的操作也非常之简单易学。实际项目用起来,工作量最大的部分就是你如何解析定位到你的目标项目页面中的各种元素。好比你要定位一个Button,你可以用ID,可以用CSS,可以用XPATH,你为了点击这个Button,写了一个函数调用Selenium里的API,即WebElement里的click()或者submit(),那么另外一个Button怎么办?成百上千个Button又怎么办?
所以,你需要有一套自己实现的算法或者封装,来根据项目页面的特点提供一套通用的元素定位方式。当你的通用定位逻辑能准确的找到任何一个元素的时候,剩下的事情就顺理成章了,交给Selenium WebElement的API就可以了。这一套定位逻辑笔者觉得才是使用Selenium做Web自动化工作量最大的部分。当然有的公司Web项目使用了自己开发的UI框架,例如笔者所在的公司,这样Web元素的定位规则和算法就比较容易设计。如果Web项目开发出来的页面代码比较杂乱无章,那么你就需要更加高明和严谨的逻辑去寻找你想要操作和查看的元素了!
在笔者的项目里,笔者自己设计并封装了一套通用的API,去智能的定位页面中的各种类型的元素。比如项目里的页面有大量的dialog和wizard,都是用div+css实现的。我就提供了一个dialog组件,带有next(),save(),finish(),click(String buttonName),cancel()等方法,然后根据遮罩层和loading Icon的时间来追踪操作完成的进度。这里只是举个小小的例子,有机会再分享更多的细节
selenium及webdriver的原理【转】的更多相关文章
- 【转】selenium及webdriver的原理
主要内容转自:http://blog.csdn.net/ant_ren/article/details/7968582和http://blog.csdn.net/ant_ren/article/det ...
- selenium及webdriver的原理
主要内容转自:http://blog.csdn.net/ant_ren/article/details/7968582和http://blog.csdn.net/ant_ren/article/det ...
- Atitit WebDriver技术规范原理与概念
Atitit WebDriver技术规范原理与概念 1. Book haosyo ma1 2. WebDriver是W3C的一个标准,由Selenium主持.1 3. WebDriver如何工作 (z ...
- Selenium:WebDriver简介及元素定位
参考内容:官方API文档,下载链接:http://download.csdn.net/detail/kwgkwg001/4004500 虫师:<selenium2自动化测试实战-基于python ...
- selenium工作的大概原理
selenium的原理是什么? selenium的原理涉及到3个部分,分别是 浏览器 driver: 一般我们都会下载driver client: 也就是我们写的代码 client其实并不知道浏览器是 ...
- selenium和webdriver区别
接触selenium大概半年时间了.从开始的预研,简单的写个流程到后期的自动化框架的开发,因为本人不属于代码方面的大牛,一直的边研究边做.逐步深入学习.近期发现自己对本身selenium的发展还存在困 ...
- Selenium的webdriver的常用方法,鼠标事件
就来认识 WebDriver 中最常用的几个方法: get():跳转到的地址clear(): 清除文本. send_keys (value): 模拟按键输入. click(): 单击元素. 示例: f ...
- selenium调用webdriver异常
使用selenium调用webdriver的时候报错. from selenium import webdriver browser = webdriver.Chrome() browser.get( ...
- 第五种方式,python使用组合来添加类方法和属性(二),以selenium的webdriver为例
组合优点多,但经常比继承需要额外的代码. 上一篇是 介绍装饰器.继承.元类.mixin,四种給类动态添加类属性和方法的四种方式. 此篇介绍直接把被组合的类的属性直接加入到类里面,前面的四个例子很简单, ...
随机推荐
- python 中 打印及格式化字符串的相关方法
原文 将值转换为字符串 Python 有多种方式将任何值转为字符串: 将它传给 repr() 或 str() 函数. repr() 和 str() 的区别,看几个例子: >>> pr ...
- C# 单元测试能过,但Web项目就报错!
第一印象肯定是两个项目中各有不同的地方 背景: 公司项目采用IBatic+Castle实现 排查过程: 1.sqlmap文件是否一至,并且读取位置也要正确 2.dao.config文件要一至,读取位置 ...
- 国庆JAVA作业
动手动脑1 运行enumtest.java程序我明白了JAVA中枚举类型,s和t不能引用同一个对象.不是原始对象,可以实现从字符串中的转换. 动手动脑2 原码就是符号位加上真值的绝对值, 即用第一位表 ...
- Git 子模块:git submodule
imtianx 2018年03月08日阅读 2057 Git 子模块:git submodule 工作中,可能会遇到在一个Git仓库 中添加 其他 Git 仓库的场景.比如,在项目中引用第三方库.或者 ...
- ubuntu物理机上搭建Kubernetes集群 -- minion 配置
1. flannel配置 下载二进制文件 https://github.com/coreos/flannel/releases 版本:flannel-v0.7.0-linux-amd64.tar.gz ...
- 【Python全栈-JavaScript】JavaScript入门
JavaScript基础知识点 一.JavaScript概述 参考:http://www.w3school.com.cn/b.asp JavaScript的历史 1.1992年Nombas开发出C-m ...
- 从网络上筛选"流媒体"的相关文章
1> 雷神的博客专栏https://blog.csdn.net/leixiaohua1020 [总结]FFMPEG视音频编解码零基础学习方法https://blog.csdn.net/leixi ...
- JVM java垃圾回收机制
一.jvm简介 1.JVM内存运行时数据区的三个重要的地方 1.1.堆(heap):它是最大的一块区域,用于存放对象实例数组,是全局共享的. 1.2.栈(stack):全称为虚拟机栈,主要存储基本数据 ...
- springMVC(二): @RequestBody @ResponseBody 注解实现分析
一.继承结构 @RequestBody.@ResponseBody的处理器:RequestResponseBodyMethodProcessor @ModelAttribute处理器: ModelAt ...
- 什么是Docker?(一)
Docker 最初是 dotCloud 公司创始人 Solomon Hykes 在法国期间发起的一个公司内部项目,它是基于 dotCloud 公司多年云服务技术的一次革新,并于 2013 年 3 月以 ...