CentOS6.5 安装Spark集群
一、安装依赖软件Scala(所有节点)
1、下载Scala:http://www.scala-lang.org/files/archive/scala-2.10.4.tgz
2、解压:
[root@Hadoop-NN-01 ~]# tar -xzvf scala-2.10.4.tgz -C /usr/local/
3、配置scala环境变量
[root@Hadoop-NN-01 ~]# vim /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:${SCALA_HOME}/bin [root@Hadoop-NN-01 ~]# source /etc/profile #使环境变量生效
4、测试scala运行环境
[root@Hadoop-NN-01 scala]# scala
scala> 15*15
res0: Int = 225
二、安装spark
1、下载spark:http://archive.cloudera.com/cdh5/cdh/5/spark-1.5.0-cdh5.6.0.tar.gz
理论上讲CDH的一套是没有问题,可是我装了三个版本都没有装成功,启动的时候始终一个错:Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Logger
提示缺少slf4j依赖包:log4j-1.2.17.jar、 slf4j-api-1.7.10.jar、 slf4j-log4j12-1.7.10.jar
可我将这三个包放到lib下依然不行,最后只能下载的官方的安装。如果有朋友知道原谅还请留言,谢谢!
引用【书忆江南】的回复:
#CDH版的Spark安装目录下的/conf/spark-env.sh配置文件中,添加以下环境变量:export SPARK_DIST_CLASSPATH=(/mnt/sda6/Hadoop/hadoop−2.6.0−cdh5.15.0/bin/hadoopclasspath),给这个变量添加你已经安装的CDHHadoop的类路径,我看到别的教程说等号后面可以直接(/mnt/sda6/Hadoop/hadoop−2.6.0−cdh5.15.0/bin/hadoopclasspath),给这个变量添加你已经安装的CDHHadoop的类路径,我看到别的教程说等号后面可以直接(hadoop classpath),我试过,这样只能启动Master,启动Worker进程的时候还是会报缺Logger的错。所以,必须要在括号内写全CDH Hadoop的安装路径精确到/bin,然后再斜杠接上hadoop classpath才行。 export SPARK_DIST_CLASSPATH=$(/mnt/sda6/Hadoop/hadoop-2.6.0-cdh5.15.0/bin/hadoop classpath)
官方下载:http://www.apache.org/dyn/closer.lua/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
2、解压:
[root@Hadoop-NN-01 ~]# tar xzvf spark-1.6.0-bin-hadoop2.6.tgz
3、配置Spark环境变量
[root@Hadoop-NN-01 ~]# vim /etc/profile
export SPARK_HOME=/home/hadoopuser/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:${SPARK_HOME}/bin [root@Hadoop-NN-01 ~]# source /etc/profile #使环境变量生效
4、配置 ${SPARK_HOME}/conf/spark-env.sh
[hadoopuser@Hadoop-NN-01 conf]$ cp spark-env.sh.template spark-env.sh [hadoopuser@Hadoop-NN-01 conf]$ vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_73
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0
export HADOOP_CONF_DIR=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/etc/hadoop
export SPARK_MASTER_IP=192.168.107.82
export SPARK_MASTER_PORT=8070
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_CORES=1 #每个Worker使用的CPU核数
export SPARK_WORKER_INSTANCES=1 #每个Slave中启动几个Worker实例
export SPARK_WORKER_PORT=8092 #Worker的WebUI端口号
export SPARK_WORKER_MEMORY=1g #每个Worker使用多大的内存
其它参数:
|
SPARK_MASTER_IP |
绑定一个外部IP给master。 |
|
SPARK_MASTER_PORT |
从另外一个端口启动master(默认: 7077) |
|
SPARK_MASTER_WEBUI_PORT |
Master的web UI端口(默认:8080) |
|
SPARK_WORKER_PORT |
启动Spark worker 的专用端口(默认:随机) |
|
SPARK_WORKER_DIR |
伸缩空间和日志输入的目录路径(默认:SPARK_HOME/work) |
|
SPARK_WORKER_CORES |
作业可用的CPU内核数量(默认:所有可用的) |
|
SPARK_WORKER_MEMORY |
作业可使用的内存容量,默认格式1000M或者 2G (默认:所有RAM去掉给操作系统用的1 GB)注意:每个作业自己的内存空间由SPARK_MEM决定。 |
|
SPARK_WORKER_WEBUI_PORT |
worker 的web UI 启动端口(默认:8081) |
|
SPARK_WORKER_INSTANCES |
每个机器上运行worker数量(默认:1)当你有一个非常强大的计算机的时候和需要多个Spark worker进程的时候你可以修改这个默认值大于1。如果你设置了这个值。要确保SPARK_WORKER_CORE 明确限制每一个r worker的核心数,否则每个worker 将尝试使用所有的核心。 |
|
SPARK_DAEMON_MEMORY |
分配给Spark master和 worker 守护进程的内存空间(默认:512m) |
|
SPARK_DAEMON_JAVA_OPTS |
Spark master 和 worker守护进程的JVM 选项(默认:none) |
5、配置 {SPARK_HOME}/conf/ slaves
[hadoopuser@Hadoop-NN-01 conf]$ cp slaves.template slaves [hadoopuser@Hadoop-NN-01 conf]$ vim slaves
#注意这里添加所有工作节点的主机名或者ip
#Hadoop-NN-01(如果既想当master又想当worker的话,可以配置上。)
Hadoop-DN-01
Hadoop-DN-02
6、程序分发
scp -r spark-1.6.0-bin-hadoop2.6. hadoopuser@Hadoop-DN-01:/home/hadoopuser/
scp -r spark-1.6.0-bin-hadoop2.6. hadoopuser@Hadoop-DN-02:/home/hadoopuser/
7、启动spark集群
[hadoopuser@Hadoop-NN-01 sbin]# ./start-all.sh
单节点启动:
sbin/start-master.sh #启动主节点
sbin/start-slave.sh 192.168.107.82:8070 #启动从节点
8、运行示例程序
[hadoopuser@Hadoop-NN-01 spark-1.6.0-bin-hadoop2.6.]# ./bin/run-example SparkPi 10 > Sparkpilog.txt
9、验证
1)jps
主节点多了Master
从节点多了Worker
2)浏览器查看http://192.168.107.82:8090/
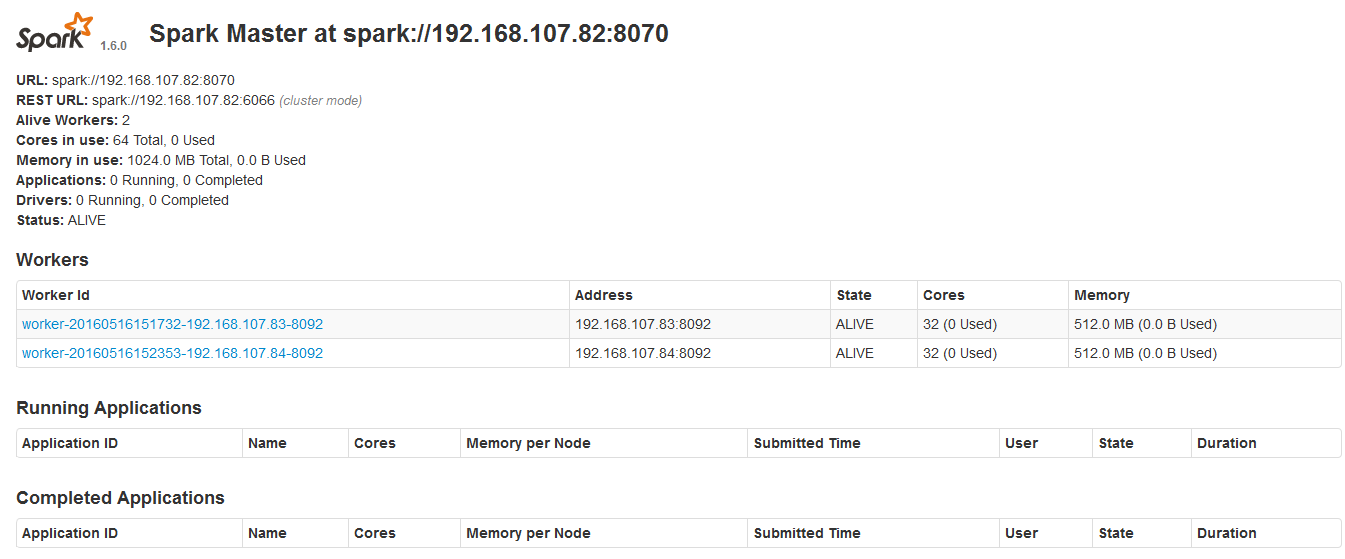
10、使用spark-shell
[hadoopuser@Hadoop-NN-01 spark-1.5.0-cdh5.6.0]# bin/spark-shell

浏览器访问SparkUI http:// 192.168.107.82:4040/

可以从 SparkUI 上查看一些 如环境变量、Job、Executor等信息。
至此,整个 Spark 分布式集群的搭建就到这里结束。
11、停止spark集群
[hadoopuser@Hadoop-NN-01 sbin]# ./stop-all.sh
CentOS6.5 安装Spark集群的更多相关文章
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- 安装Spark集群(在CentOS上)
环境:CentOS 6.4, Hadoop 1.1.2, JDK 1.7, Spark 0.7.2, Scala 2.9.3 1. 安装 JDK 1.7 yum search openjdk-deve ...
- CentOS7 安装spark集群
Spark版本 1.6.0 Scala版本 2.11.7 Zookeeper版本 3.4.7 配置虚拟机 3台虚拟机,sm,sd1,sd2 1. 关闭防火墙 systemctl stop firewa ...
- RedHat6.5安装Spark集群
版本号: RedHat6.5 RHEL 6.5系统安装配置图解教程(rhel-server-6.5) JDK1.8 http://blog.csdn.net/chongxin1/arti ...
- Centos6.6 安装Mysql集群
一.环境准备 1.1系统IP设置 准备三台服务器安装Centos6.6 64位操作系统,IP地址及角色分配如下: Node IP Address ...
- 36. CentOS-6.3安装Mysql集群
安装要求 安装环境:CentOS-6.3安装方式:源码编译安装 软件名称:mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz下载地址:http://mysql ...
- redis CentOS6.5安装及集群部署
.下载redis source包 链接:https://pan.baidu.com/s/122ZCjNvjl9Jx6M2YsLrncw 密码:92ze 2.解压 tar -xzf redis-3.2. ...
- CentOS6.5 安装Storm集群
1.首先安装依赖包 [root@Hadoop-NN-01 ~]# yum install uuid* [root@Hadoop-NN-01 ~]# yum install libuuid [root@ ...
- CentOS6.5安装HBase集群及多HMaster配置
1.配置SSH免登录 请参考:http://www.cnblogs.com/hunttown/p/5470357.html 服务器配置: Hadoop-NN-01 主Hadoop-NN-02 备Had ...
随机推荐
- 设计模式学习--Abstarct Factory
What Abstarct Factory:提供一个创建一系列相关或相互依赖的接口,而无需指定他们具体类. Why Abstarct Factory是创建型设计模式的一种,主要在创建对象时解耦,避免对 ...
- mtd工具
http://daemons.net/linux/storage/mtd.html MTD The Memory Technology Devices (MTD) subsystem provides ...
- CentOS和Redhat单用户模式
当系统无法启动时,可能是/etc/fstab挂载错误导致这时候可以进入单用户模式修改配置文件后重启 重启系统出现以下界面按e 选择第二栏按e健 在后面输入1回车回到上一个页面按b健启动 进入单用户模式 ...
- asp.net Ajax调用Aspx后台方法
Ajax调用的前提(以aspx文件为例:) 1.首先需要在aspx文件后台中引用using System.Web.Services; 2.需要调用的方法必须是公共的(public).静态的(stati ...
- Steeltoe之Service Discovery篇
在前文一窥Spring Cloud Eureka中,已经构建了基于Eureka的服务端与客户端,可用于实现服务注册与发现功能.而借助Steeltoe的类库,可以在.NET生态系统中使用Spring C ...
- HDU5988/nowcoder 207G - Coding Contest - [最小费用最大流]
题目链接:https://www.nowcoder.com/acm/contest/207/G 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5988 ...
- 下载文件的协议:HTTP、FTP、P2P
本篇学习笔记以HTTP.FTP.P2P叙述与网上下载文件有关的协议 需要掌握的要点: 下载一个文件可以使用 HTTP 或 FTP,这两种都是集中下载的方式,而 P2P 则换了一种思路,采取非中心化下载 ...
- DBCHART
dbchart1.Series[0].DataSource := adoquery1; dbchart1.Series[0].XLabelsSource := 'aaaa'; dbchart1.Ser ...
- 清理solaris /var/mail/下的邮件文件
我服务器上/var/mail下的各个用户的邮件日志非常大,占用空间已经有95%了,我想清除掉,是否可以直接删除/var/mail的各个日志??删除后系统是否可以自动生成? 应该可以直接删除/var/m ...
- falsk 与 django 过滤器的使用与区别
1,flask中内置的过滤器模板中常用方法: {#过滤器调用方式{{变量|过滤器名称}} #} <!-- safe过滤器,可以禁用转义 --> {{'<strong>hello ...