安装hadoop2.9.2 jdk1.8 centos7
安装JDK1.8
查看JDK1.8的安装
https://www.cnblogs.com/TJ21/p/13208514.html
安装hadoop
上传hadoop
下载hadoop 地址http://mirrors.hust.edu.cn/apache/hadoop/common/
放到mkdir /usr/local/src/hadoop目录下
解压 tar -zxvf hadoop-2.9.2.tar.gz
配置环境变量
vi /etc/profile 添加如下配置 export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.9.
export PATH=$HADOOP_HOME/bin:$PATH 重新刷新配置 source /etc/profile 查看版本 hadoop version
修改配置文件
vi core-site.xml
路径是 cd /usr/local/src/hadoop/hadoop-2.9.2/etc/hadoop
vi core-site.xml 添加如下配置
<property>
<name>fs.defaultFS</name>
<!-- 这里填的是你自己的ip,端口默认-->
<value>hdfs://192.168.0.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里填的是你自定义的hadoop工作的目录,端口默认-->
<value>/usr/local/src/hadoop/hadoop-2.9.2/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.
</description>
</property>
vi hadoop-env.sh 配置成你自己的jdk安装路径
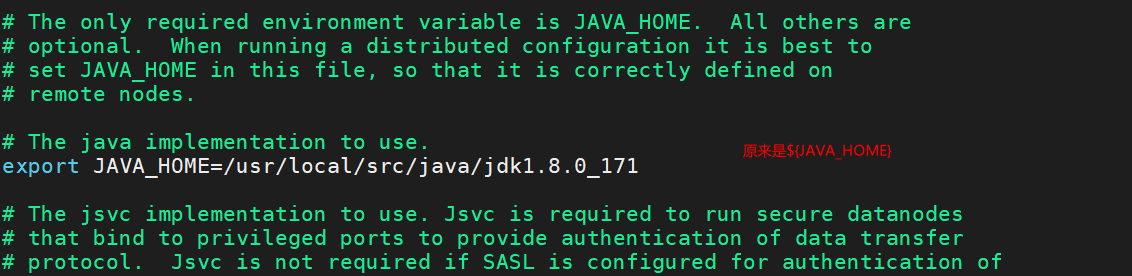
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.secondary.http.address</name> <!--这里是你自己的ip,端口默认-->
<value>192.168.0.130:50090</value>
</property>
vi mapred-site.xml
复制默认的cp mapred-site.xml.template ./mapred-site.xml 配置命名为mapred-site.xml
vi mapred-site.xml 添加如下配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>192.168.0.130</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置完成启动
配置好之后切换到sbin目录下
cd /usr/local/src/hadoop/hadoop-2.9.2/sbin/ 查看命令 ll
格式化hadoop文件格式,执行命令 hadoop namenode -format,成功之后启动
执行启动所有命令
./start-all.sh
没启动一个进程需要输入密码,可以通过配置ssh来解决,就不需要输入了,暂时配置
使用 jps 查看进程,能看到这些进程证明启动成功了,
也可以通过网页来查看 192.168.0.130:50070 此处的ip是自己的虚拟机IP
关闭防火墙的方法为:
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动
安装hadoop2.9.2 jdk1.8 centos7的更多相关文章
- CentOS7安装Hadoop2.7完整流程
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7完整步骤
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7流程
准备3个虚拟机节点 其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍lin ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- 安装hadoop2.7.3
hadoop3与hadoop2.x的变化很大,hadoop3很多东西现在做起来太麻烦了,这里先安装hadoop2.7.3 此贴学习地址http://www.yiibai.com/t/mapreduce ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 编译安装hadoop2.6.3
一.安装环境 1.1 JAVA 安装java1.7 下载jdk1.7: [root@node1~]# wget http://download.oracle.com/otn-pub/java/jd ...
- centos单机安装Hadoop2.6
一,安装环境 硬件:虚拟机 操作系统:Centos 6.4 64位 IP:10.51.121.10 主机名:datanode-4 安装用户:root 二,安装JDK 安装JDK1.6或者以上版本.这里 ...
随机推荐
- js在运算时的类型转换
日期类型与数字类型的运算 在加法时将日期对象与数字都当作字符串进行连接 字符串的运算方式中没有减法.乘法.除法.转化成数字类型进行运算 字符串类型字符与数字类型的运算 在加法时将二者都转换成字符串进行 ...
- eclipse 界面复原
Windows-----Perspective-----Reset perspective
- Redis 入门到分布式 (四) 瑞士军刀Redis其他功能
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 目录: 慢查询 Pipeline 发布订阅 Bitmap(位图) HyperLogLog GEO 一.慢 ...
- Java实现 LeetCode 552 学生出勤记录 II(数学转换?还是动态规划?)
552. 学生出勤记录 II 给定一个正整数 n,返回长度为 n 的所有可被视为可奖励的出勤记录的数量. 答案可能非常大,你只需返回结果mod 109 + 7的值. 学生出勤记录是只包含以下三个字符的 ...
- Java实现 蓝桥杯 历届试题 错误票据
问题描述 某涉密单位下发了某种票据,并要在年终全部收回. 每张票据有唯一的ID号.全年所有票据的ID号是连续的,但ID的开始数码是随机选定的. 因为工作人员疏忽,在录入ID号的时候发生了一处错误,造成 ...
- java实现第六届蓝桥杯无穷分数
无穷分数 无穷分数 无穷的分数,有时会趋向于固定的数字. 请计算[图1.jpg]所示的无穷分数,要求四舍五入,精确到小数点后5位,小数位不足的补0. 请填写该浮点数,不能填写任何多余的内容. 结果:0 ...
- java实现第四届蓝桥杯世纪末星期
世纪末星期 题目描述 曾有邪教称1999年12月31日是世界末日.当然该谣言已经不攻自破. 还有人称今后的某个世纪末的12月31日,如果是星期一则会- 有趣的是,任何一个世纪末的年份的12月31日都不 ...
- 【Spring注解驱动开发】聊聊Spring注解驱动开发那些事儿!
写在前面 今天,面了一个工作5年的小伙伴,面试结果不理想啊!也不是我说,工作5年了,问多线程的知识:就只知道继承Thread类和实现Runnable接口!问Java集合,竟然说HashMap是线程安全 ...
- mysql基础-数据库表的管理-记录(四)
0x01 MySQL中字符大小写 1.SQL关键字及函数不区分大小写 2.数据库.表及视图名称的大小写区分与否取决于底层OS及FS 3.存储过程.存储函数及事件调度器的名字不区分大小写,但触发器区分大 ...
- 最新 iOS 框架整体梳理(二)
在前面一篇中整理出来了一些了,下面的内容是接着上面一篇的接着整理.上篇具体的内容可以点击这里查看: 最新 iOS 框架整体梳理(一) Part - 2 34.CoreTeleph ...