flink系列-10、flink保证数据的一致性
本文摘自书籍《Flink基础教程》
一、一致性的三种级别
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是“正确性级别”的另一种说法,即在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比。在流处理中,一致性分为 3 个级别。
- at-most-once:数据最多被处理一次。这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。
- at-least-once:数据最少被处理一次。这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少
- exactly-once:数据只被处理一次(最优)。这指的是系统保证在发生故障后得到的计数结果与正确值一致。
曾经, at-least-once 非常流行。第一代流处理器(如 Storm 和 Samza)刚问世时只保证 at-least-once,原因有二:
- 保证 exactly-once 的系统实现起来更复杂。这在基础架构层(决定什么代表正确,以及 exactly-once 的范围是什么)和实现层都很有挑战性。
- 流处理系统的早期用户愿意接受框架的局限性,并在应用层想办法弥补(例如使应用程序具有幂等性,或者用批量计算层再做一遍计算)。
最先保证 exactly-once 的系统(Storm Trident 和 Spark Streaming)在性能和表现力这两个方面付出了很大的代价:
- 为了保证 exactly-once,这些系统无法单独地对每条记录运用应用逻辑,而是同时处理多条(一批)记录,保证对每一批的处理要么全部成功,要么全部失败。
- 这就导致在得到结果前,必须等待一批记录处理结束。
- Flink 的一个重大价值在于,它既保证了 exactly-once,也具有低延迟和高吞吐的处理能力。
二、检查点,保证exactly-once
- Flink使用一种被称为“检查点”的特性,在出现故障时将系统重置回正确状态。
- 检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once,并且不需要牺牲性能。
- Flink 检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住这一基本点之后,我们用一个例子来看检查点是如何运行的。Flink 为用户提供了用来定义状态的工具。
- 例如,以下这个 Scala 程序按照输入记录的第一个字段(一个字符串)进行分组并维护第二个字段的计数状态。
val mapData: DataStream[(String, Int)] = dataSource.flatMap(f => f.split(" ")).map((_, 1))
val mapWithStageData: DataStream[(String, Int)] = mapData.keyBy(_._1).mapWithState((in: (String, Int), count: Option[Int]) => {
count match {
case Some(c) => ((in._1, c + in._2), Some(c + in._2))
case None => ((in._1, in._2), Some(in._2))
}
})
该程序有两个算子:keyBy 算子用来将记录按照第一个元素(一个字符串)进行分组,根据该 key 将数据进行重新分区,然后将记录再发送给下一个算子:有状态的 map 算子(mapWithState)。map算子在接收到每个元素后,将输入记录的第二个字段的数据加到现有总数中,再将更新过的元素发射出去。
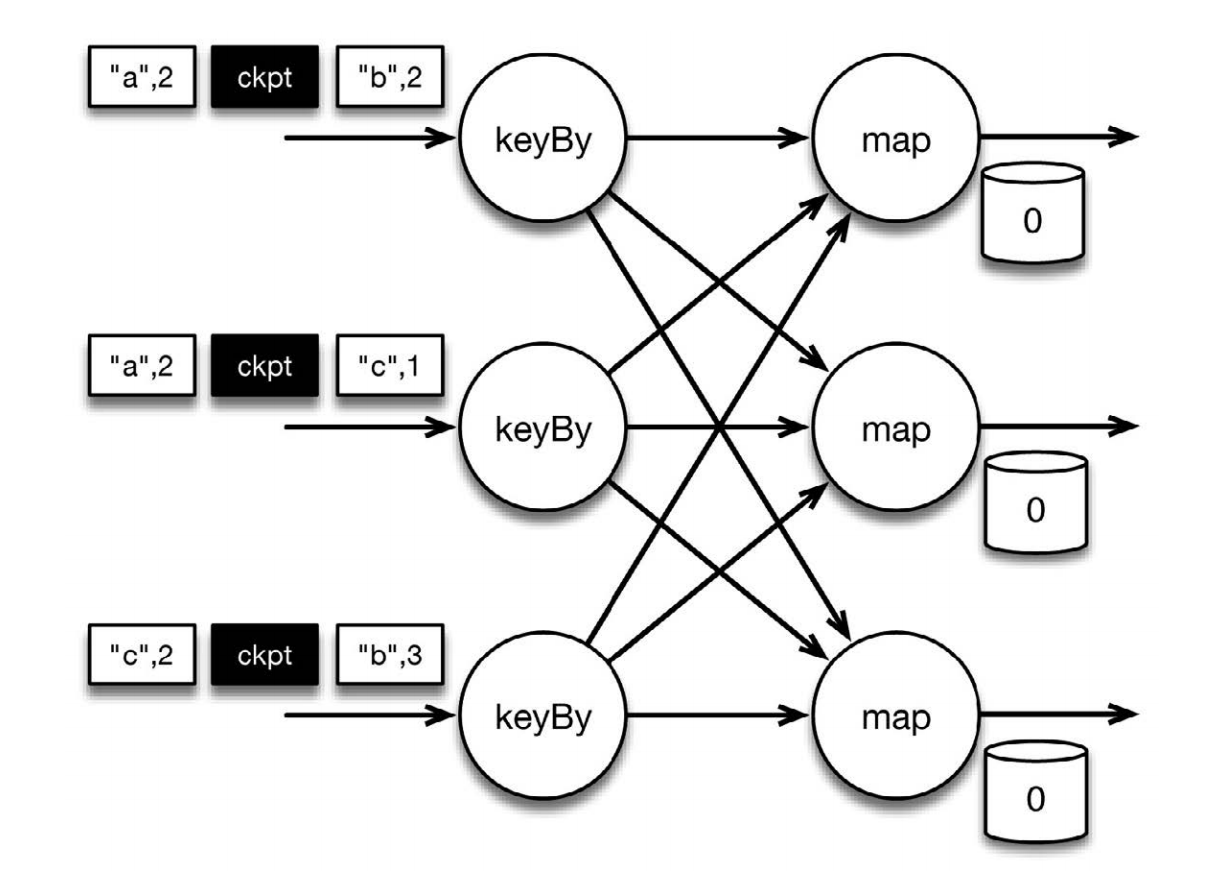
上图表示程序的初始状态:输入流中的6条记录被检查点屏障(checkpoint barrier)隔开,所有的map算子状态均为0(计数还未开始)。所有key为a的记录将被顶层的map算子处理,所有key为b的记录将被中间层的map算子处理,所有key为c的记录则将被底层的map算子处理。其中 ["b",2] 在检查点之前被处理, ["a",2] 则在检查点之后被处理
当该程序处理输入流中的 6 条记录时,涉及的操作遍布 3 个并行实例(节点、 CPU 内核等)。那么,检查点该如何保证 exactly-once 呢?检查点屏障和普通记录类似。它们由算子处理,但并不参与计算,而是会触发与检查点相关的行为。当读取输入流的数据源(在本例中与 keyBy 算子内联)遇到检查点屏障时,它将其在输入流中的位置保存到稳定存储中。如果输入流来自消息传输系统(Kafka 或 MapR Streams),这个位置就是偏移量。 Flink 的存储机制是插件化的,稳定存储可以是分布式文件系统,如HDFS、 S3 或 MapR-FS。下图展示了这个过程。
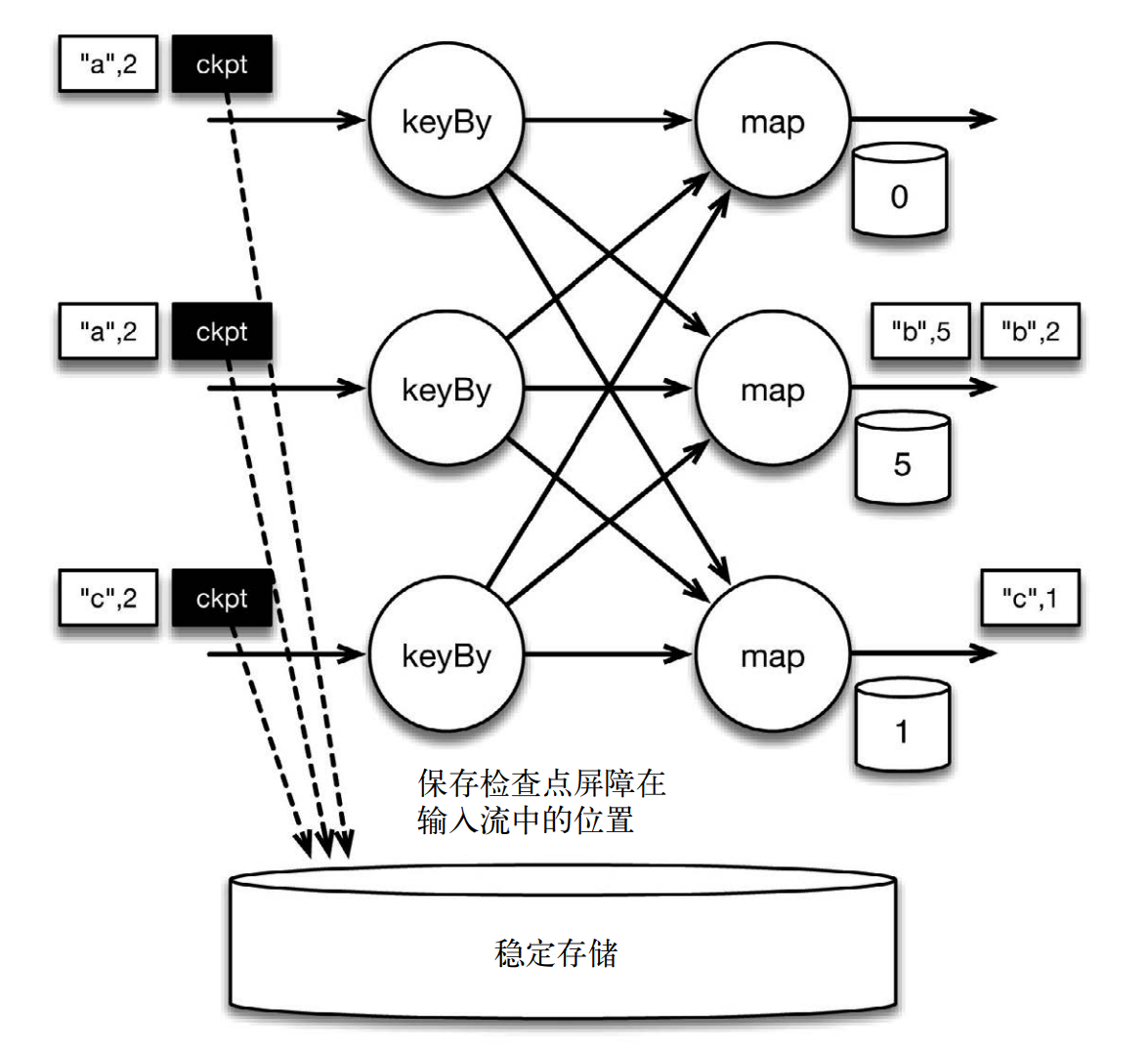
如下图所示:位于检查点之前的所有记录(["b",2]、 ["b",3] 和 ["c",1])被 map 算子处理之后的情况。此时,稳定存储已经备份了检查点屏障在输入流中的位置(备份操作发生在检查点屏障被输入算子处理的时候)。 map 算子接着开始处理检查点屏障,并触发将状态异步备份到稳定存储中这个动作。检查点屏障像普通记录一样在算子之间流动。当 map 算子处理完前 3 条记录并收到检查点屏障时,它们会将状态以异步的方式写入稳定存储。
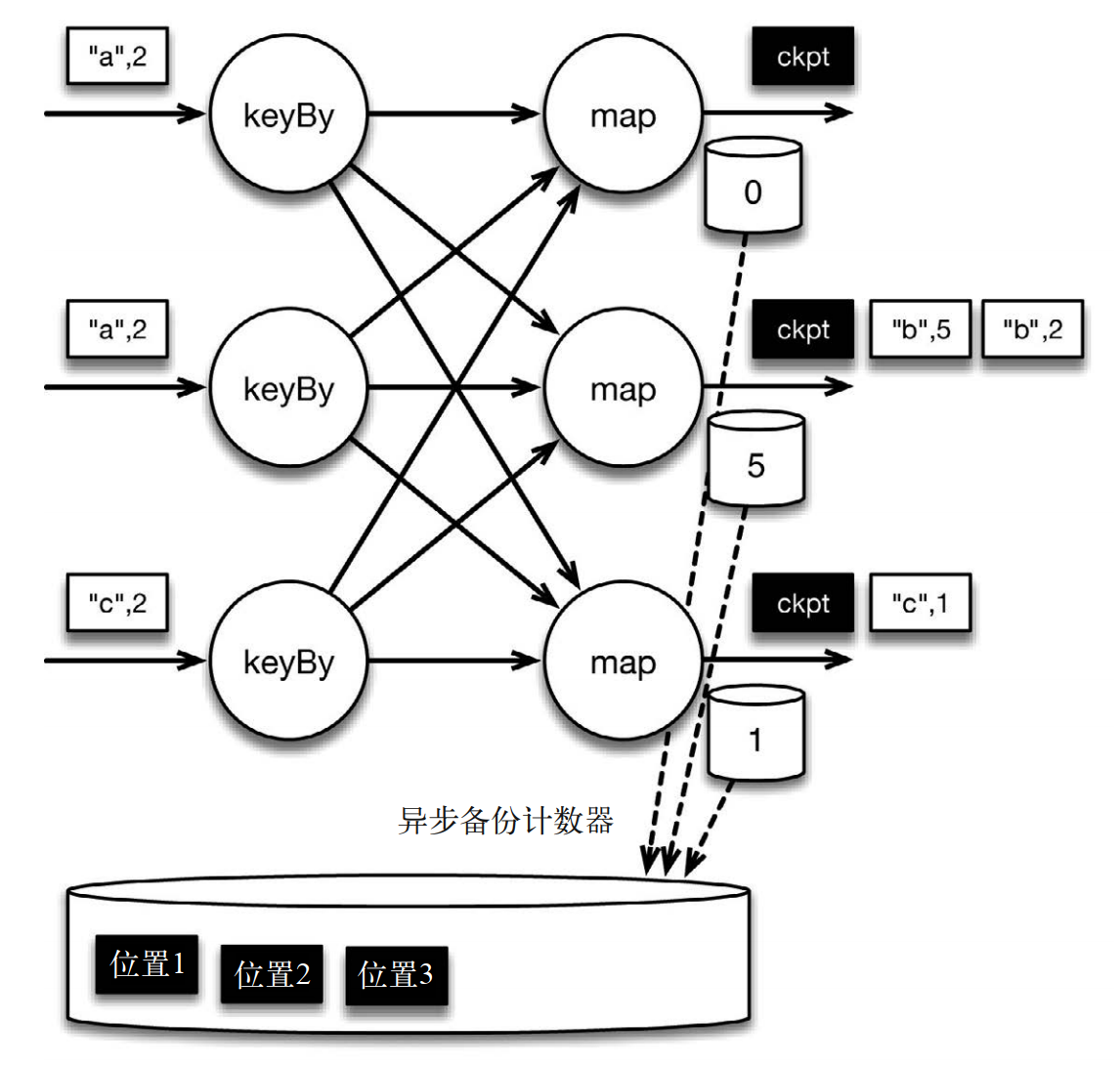
当 map 算子的状态备份和检查点屏障的位置备份被确认之后,该检查点操作就可以被标记为完成,如下图所示。我们在无须停止或者阻断计算的条件下,在一个逻辑时间点(对应检查点屏障在输入流中的位置)为计算状态拍了快照。通过确保备份的状态和位置指向同一个逻辑时间点,从而保证 exactly-once。值得注意的是,当没有出现故障时, Flink 检查点的开销极小,检查点操作的速度由稳定存储的可用带宽决定。值得注意的是,备份的状态值与实际的状态值是不同的。备份反映的是检查点的状态
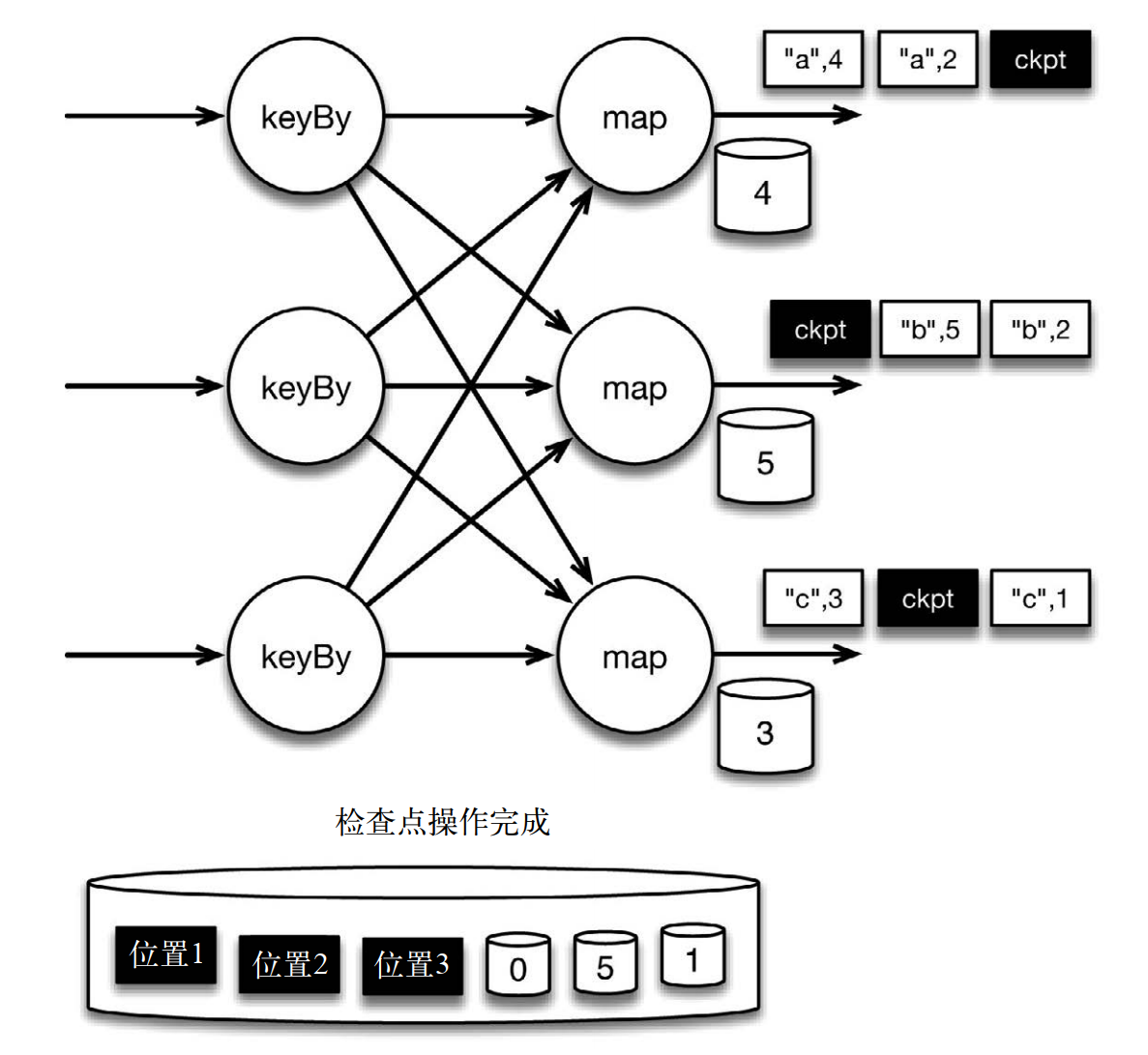
如果检查点操作失败, Flink 会丢弃该检查点并继续正常执行,因为之后的某一个检查点可能会成功。虽然恢复时间可能更长,但是对于状态的保证依旧很有力。只有在一系列连续的检查点操作失败之后, Flink 才会抛出错误,因为这通常预示着发生了严重且持久的错误。
在这种情况下, Flink 会重新拓扑(可能会获取新的执行资源),将输入流倒回到上一个检查点,然后恢复状态值并从该处开始继续计算。
二、保存点: 状态版本控制
检查点由 Flink 自动生成,用来在故障发生时重新处理记录,从而修正状态。 Flink 用户还可以通过另一个特性有意识地管理状态版本,这个特性叫作保存点(savepoint)
- 保存点与检查点的工作方式完全相同,只不过它由用户通过 Flink 命令行工具或者 Web 控制台手动触发,而不由 Flink 自动触发。
- 和检查点一样,保存点也被保存在稳定存储中。
- 用户可以从保存点重启作业,而不用从头开始。
- 保存点可以被视为作业在某一个特定时间点的快照(该时间点即为保存点被触发的时间点)。
- 对保存点的另一种理解是,它在明确的时间点保存应用程序状态的版本。这和用版本控制系统保存应用程序的版本很相似。最简单的例子是在不修改应用程序代码的情况下,每隔固定的时间拍快照,即照原样保存应用程序状态的版本。
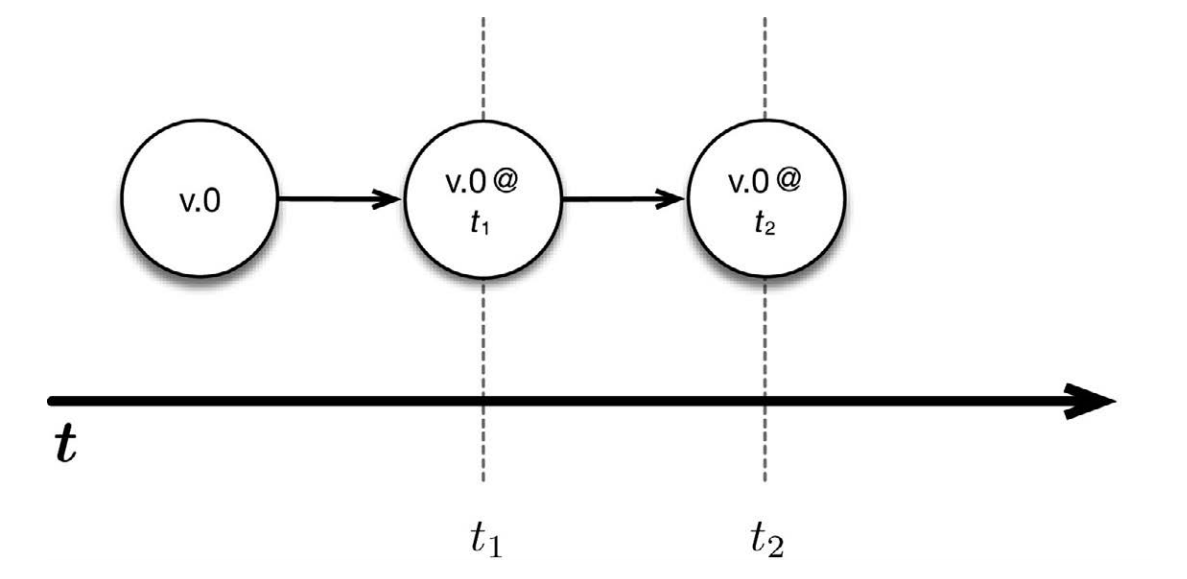
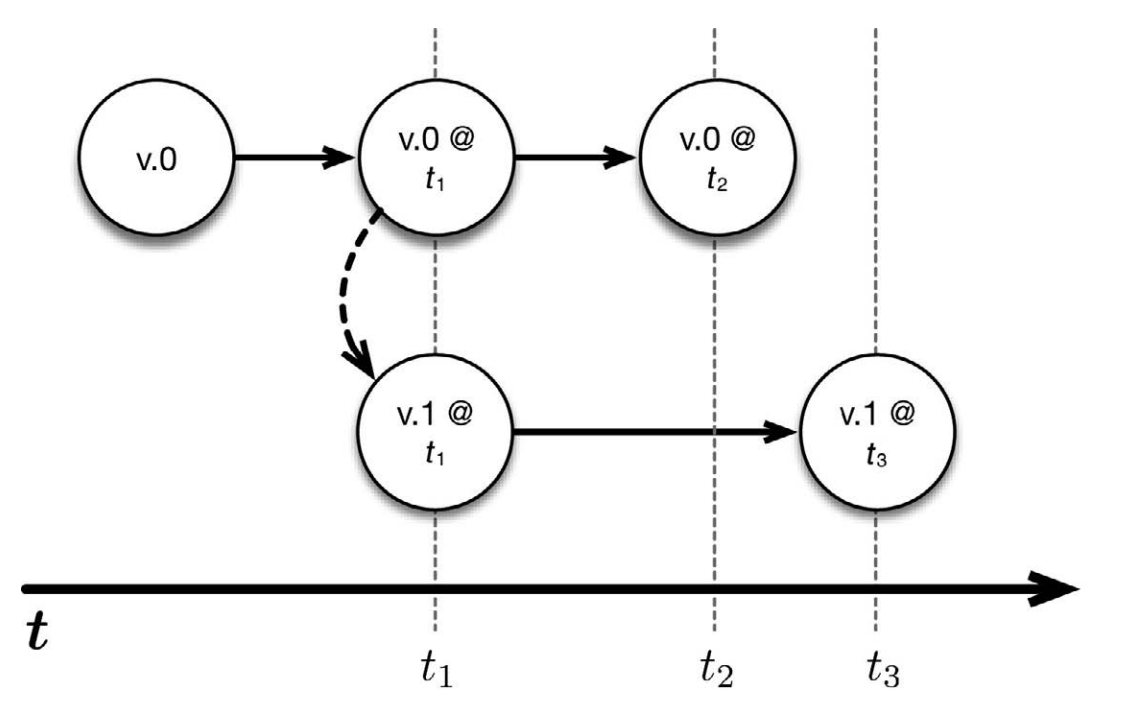
上图中, v.0 是某应用程序的一个正在运行的版本。我们分别在 t1 时刻和 t2时刻触发了保存点。因此,可以在任何时候返回到这两个时间点,并且重启程序。更重要的是,可以从保存点启动被修改过的程序版本。举例来说,可以修改应用程序的代码(假设称新版本为 v.1),然后从 t1 时刻开始运行改动过的代码。这样一来, v.0 和 v.1 这两个版本同时运行,并在之后的时间里获取各自的保存点。
保存点可用于应对流处理作业在生产环境中遇到的许多挑战:
- 应用程序代码升级:假设你在已经处于运行状态的应用程序中发现了一个 bug,并且希望之后的事件都可以用修复后的新版本来处理。通过触发保存点并从该保存点处运行新版本,下游的应用程序并不会察觉到不同(当然,被更新的部分除外)。
- Flink 版本更新: Flink 自身的更新也变得简单,因为可以针对正在运行的任务触发保存点,并从保存点处用新版本的 Flink 重启任务。
- 维护和迁移:使用保存点,可以轻松地“暂停和恢复”应用程序。这对于集群维护以及向新集群迁移的作业来说尤其有用。此外,它还有利于开发、测试和调试,因为不需要重播整个事件流。
- 假设模拟与恢复:在可控的点上运行其他的应用逻辑,以模拟假设的场景,这样做在很多时候非常有用。
- A/B 测试:从同一个保存点开始,并行地运行应用程序的两个版本,有助于进行 A/B 测试
三、端到端的一致性和作为数据库的流处理器
我们已经通过简单的计数例子了解了 Flink 如何保证状态的一致性(即保证exactly-once)。接下来看看端到端的情况,因为在生产环境中可能会部署这种应用程序。
下面的应用程序架构中,有状态的 Flink 应用程序消费来自消息队列的数据,然后将数据写入输出系统,以供查询。底部的详情图展示了 Flink 应用程序的内部情况。
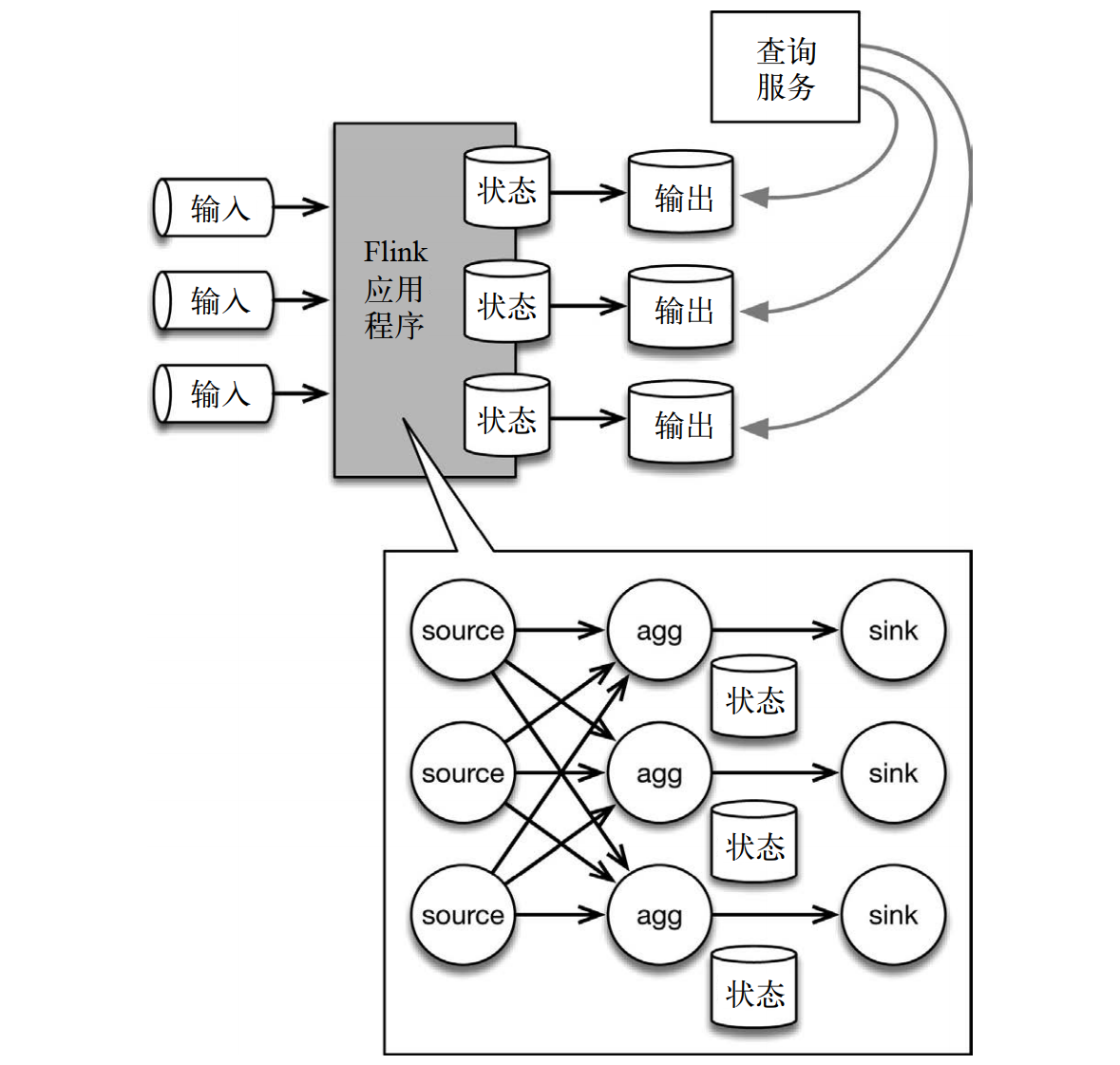
输入数据来自一个分区存储系统(如 Kafka 或者 MapR Streams 这样的消息队列)。底部的详情图展示了 Flink 拓扑,其中包含 3 个算子。source 读取输入数据,根据 key 分区,并将数据路由到有状态的算子实例。有状态的算子将状态内容(比如前例中的计数结果)或者一些衍生结果写入 sink,再由 sink 将结果传送到输出存储系统中(例如文件系统或数据库)。接着,查询服务(比如数据库查询 API)就可以允许用户对状态进行查询(最简单的例子就是查询计数结果),因为状态已经被写入输出存储系统了。
需要记住的是,在本例中,输出反映的是截至最近一次写入状态之时, Flink 应用程序中的状态内容。
在将状态内容传送到输出存储系统的过程中,如何保证 exactly-once 呢?这叫作端到端的一致性。本质上有两种实现方法,用哪一种方法则取决于输出存储系统的类型,以及应用程序的需求:
- 第一种方法是在 sink 环节缓冲所有输出,并在 sink 收到检查点记录时,将输出“原子提交”到存储系统。这种方法保证输出存储系统中只存在有一致性保障的结果,并且不会出现重复的数据。从本质上说,输出存储系统会参与 Flink 的检查点操作。要做到这一点,输出存储系统需要具备“原子提交”的能力。
- 第二种方法是急切地将数据写入输出存储系统,同时牢记这些数据可能是“脏”的,而且需要在发生故障时重新处理。如果发生故障,就需要将输出、输入和 Flink 作业全部回滚,从而将“脏”数据覆盖,并将已经写入输出的“脏”数据删除。注意,在很多情况下,其实并没有发生删除操作。例如,如果新记录只是覆盖旧纪录(而不是添加到输出中),那么“脏”数据只在检查点之间短暂存在,并且最终会被修正过的新数据覆盖。
值得注意的是,这两种方法恰好对应关系数据库系统中的两种为人所熟知的事务隔离级别: 已提交读(read committed)和未提交读(read uncommitted)。已提交读保证所有读取(查询输出)都只读取已提交的数据,而不会读取中间、传输中或“脏”的数据。之后的读取可能会返回不同的结果,因为数据可能已被改变。未提交读则允许读取“脏”数据;换句话说,查询总是看到被处理过的最新版本的数据。
某些应用程序可以接受弱一点的语义,所以 Flink 提供了支持多重语义的多种内置输出算子,如支持未提交读语义的分布式文件输出算子。用户可以根据输出存储系统的能力和应用程序的需求选择合适的语义。根据输出存储系统的类型, Flink 及与之对应的连接器可以一起保证端到端的一致性,并且支持多种隔离级别。
上面的应用程序架构。之所以需要有输出存储系统,是因为外部无法访问 Flink 的内部状态,所以输出存储系统成了查询目标。但是,如果可以直接查询状态,则在某些情况下根本就不需要输出存储系统,因为状态本身就已经包含了查询所需的信息。这种情况在许多应用程序中真实存在, 直接查询状态可以大大地简化架构,同时大幅提升性能
flink系列-10、flink保证数据的一致性的更多相关文章
- Cassandra如何保证数据最终一致性
Cassandra如何保证数据最终一致性:1.逆熵机制(Anti-Entropy)使用默克尔树(Merkle Tree)来确认多个副本数据一致,对于不一致数据,根据时间戳来获取最新数据. 2.读修复机 ...
- 代码中添加事务控制 VS(数据库存储过程+事务) 保证数据的完整性与一致性
做人事档案的系统考虑到数据的安全性与一致性,毕竟是要对外上线.真正投入使用的项目,数据库的可靠性与安全性上我们开发人员要考虑的就很多了,记得做机房收费系统时注册新卡是自己为了简单,写成了一个存储过程( ...
- Flink系列之1.10版流式SQL应用
随着Flink 1.10的发布,对SQL的支持也非常强大.Flink 还提供了 MySql, Hive,ES, Kafka等连接器Connector,所以使用起来非常方便. 接下来咱们针对构建流式SQ ...
- Flink系列(0)——准备篇(流处理基础)
Apache Flink is a framework and distributed processing engine for stateful computations over unbound ...
- Flink系列之Time和WaterMark
当数据进入Flink的时候,数据需要带入相应的时间,根据相应的时间进行处理. 让咱们想象一个场景,有一个队列,分别带着指定的时间,那么处理的时候,需要根据相应的时间进行处理,比如:统计最近五分钟的访问 ...
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Flink 1.10 正式发布!——与Blink集成完成,集成Hive,K8S
Apache Flink社区宣布Flink 1.10.0正式发布! 本次Release版本修复1.2K个问题,对Flink作业的整体性能和稳定性做了重大改进,同时增加了对K8S,Python的支持. ...
- kerberos系列之flink认证配置
大数据安全系列的其它文章 https://www.cnblogs.com/bainianminguo/p/12548076.html-----------安装kerberos https://www. ...
- zookeeper 各节点数据保证是弱一致性
一致性保证: ZooKeeeper 是一个高性能的,可扩展的服务.不管是读和写操作是被设计成快速,虽然读比写快. 这样做的原因是在读的情况下,Zookeeper 可以提供旧的数据, 反过来又是由于Zo ...
随机推荐
- 来说说Java中String 类的那些事情
今天正好学校那边的任务不多,我就打算把Stirng 的有关知识点都总结在一起了,这样有利于知识的系统性,要不然学多了就会越来越杂,最主要的是总会忘记,记忆的时间太短了,通过这种方式,把它归纳在一起,写 ...
- 使用Network Emulator Toolkit工具模拟网络丢包测试(上)
弱网络测试包括延时和丢包二种场景下应用的功能是否正常: 网络延时测试使用Fiddler工具控制上下行数据传输延时时间来模拟网络延时场景: 网络丢包测试使用Network Emulator Toolki ...
- svg 实践之屏幕坐标与svg元素坐标转换
近期在做svg相关项目,很好用的东西要记下来: 1.基础知识就是根据 矩阵进行坐标转换,如下: : 屏幕坐标 = 矩阵* svg对象坐标 2.javascript有个方法用于获取 svg对象 的转换矩 ...
- 【three.js第七课】鼠标点击事件和键盘按键事件的使用
当我们使用鼠标操作three.js渲染出的对象时,不仅仅只是仅限用鼠标对场景的放大.缩小.旋转而已,还有鼠标左键.右键的点击以及键盘各种按键等等的事件.我们需要捕获这些事件,并在这些事件的方法里进行相 ...
- 【three.js第五课】光线的添加和感光材料
材料分类: MeshBasicMaterial:基础网孔材料,一个以简单着色(平面或线框)方式来绘制几何形状的材料.MeshLambertMaterial:兰伯特网孔材料,一种非发光材料(兰伯特)的表 ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- F - What Is Your Grade?
“Point, point, life of student!” This is a ballad(歌谣)well known in colleges, and you must care about ...
- 落谷 P1734 最大约数和
题目描述 选取和不超过S的若干个不同的正整数,使得所有数的约数(不含它本身)之和最大. 输入格式 输入一个正整数S. 输出格式 输出最大的约数之和. 输入输出样例 输入 #1复制 11 输出 #1复制 ...
- HPU第一次团队赛
D. Tom的战力问题 Tom被斯派克揍了TAT.Tom下定决心要战胜斯派克.但是在战胜最强的斯派克之前,Tom要先打败其他的狗.为此,他打算先收集一下信息.现在Tom在了得到了一些关于战斗力的小道消 ...
- python selenium模块 xpath定位
''' 附w3xpath语法地址 https://www.w3school.com.cn/xpath/xpath_syntax.asp 总结: 返回匹配到所有符合条件的第一个节点,对象是 <cl ...