K均值聚类算法
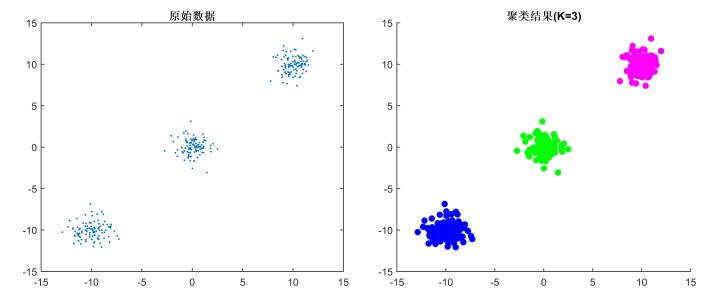
定义
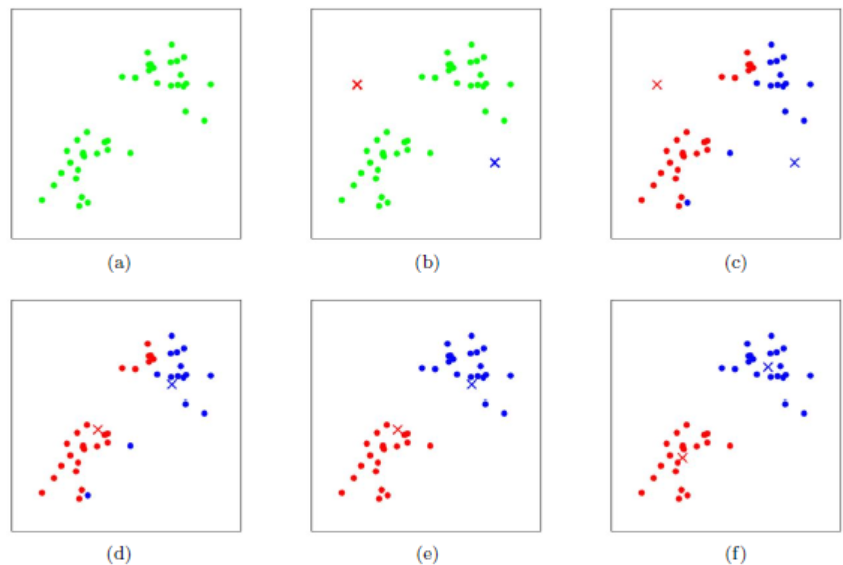
算法
K-Means的优缺点
优点:
1、原理比较简单,实现也是很容易,收敛速度快。
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
K均值聚类算法的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
随机推荐
- [转]ubuntu备份与恢复
在 使用Ubuntu之前,相信很多人都有过使用Windows系统的经历.如果你备份过Windows系统,那么你一定记忆犹新:首先需要找到一个备份工 具(通常都是私有软件),然后重启电脑进入备份工具提供 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 按钮:表示成功的动作
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- Python print()函数
#输出单个数据,会自动输出回车换行 print(1) print(2) #输出 1 2 #输出换行 print('\n') #防止换行 for x in range(0, 5): print(x, e ...
- oracle数据库时间是毫秒值,创建function,直接SQL取值。
首先创建一个function: create or replace function num_to_date(in_number NUMBER) return date is begin return ...
- 【mysql】mysq8.0新特性
一.MySQL8.0简介 mysql8.0现在已经发布,2016-09-12第一个DM(development milestone)版本8.0.0发布.新的版本带来很多新功能和新特性,对性能也得到 ...
- windows环境变量引发的血案
最近重装了系统,决心使用Anaconda来管理python包和虚拟环境.在完成一系列配置后,运行程序,发现老是报错 D:\Anaconda3\envs\jobnote>python E:\wor ...
- zookeeper logs is missing zookeeper 日志丢失
ERROR [main:QuorumPeerMain@85] - Invalid config, exiting abnormally Invalid config, exiting abnormal ...
- 100、Java中String类之字符串转为大写
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- Git如何合并Commit
如果你在 push 你的修改之前想要将本地多次修改后的 commit 合并一下变得更好看,可以使用下面的方法. 指定你要合并的 commit 相关的命令有两种 你可以通过指定修改过去的几个 commi ...
- Vue和React之间关于注册组件和组件间传值的区别
注册组件 Vue中:1.引入组件:2.在components中注册组件:3.使用组件; React中:1.引入组件:2.使用组件; 子父传值 Vue中: 父组件向子组件传值: 1.在父组件中绑定值:2 ...