python动态柱状图图表可视化:历年软科中国大学排行
本来想参照:https://mp.weixin.qq.com/s/e7Wd7aEatcLFGgJUDkg-EQ搞一个往年编程语言动态图的,奈何找不到数据,有数据来源的欢迎在评论区留言。
这里找到了一个,是2020年6月的编程语言排行,供大家看一下:https://www.tiobe.com/tiobe-index/

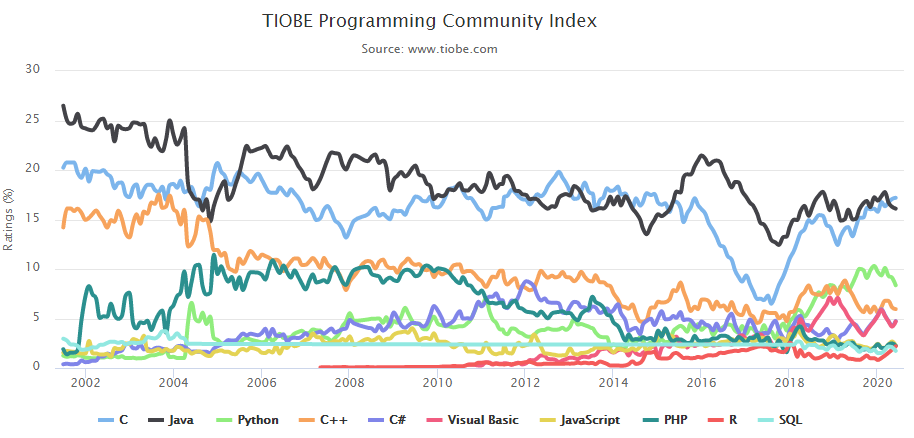
我们要实现的效果是:
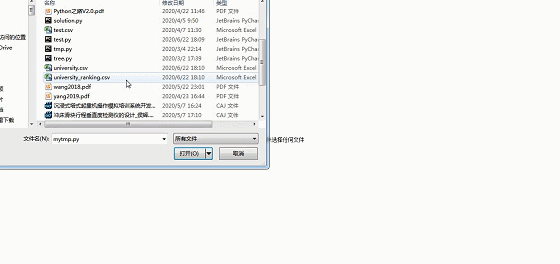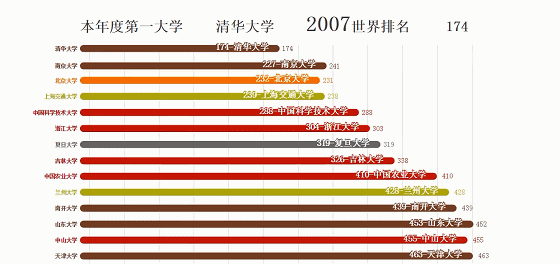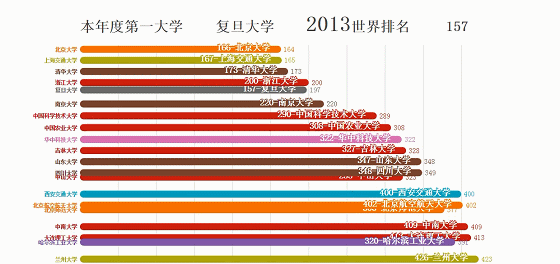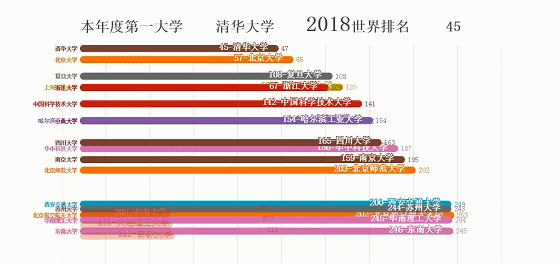
大学排名来源:http://www.zuihaodaxue.com/ARWU2003.html
部分截图:
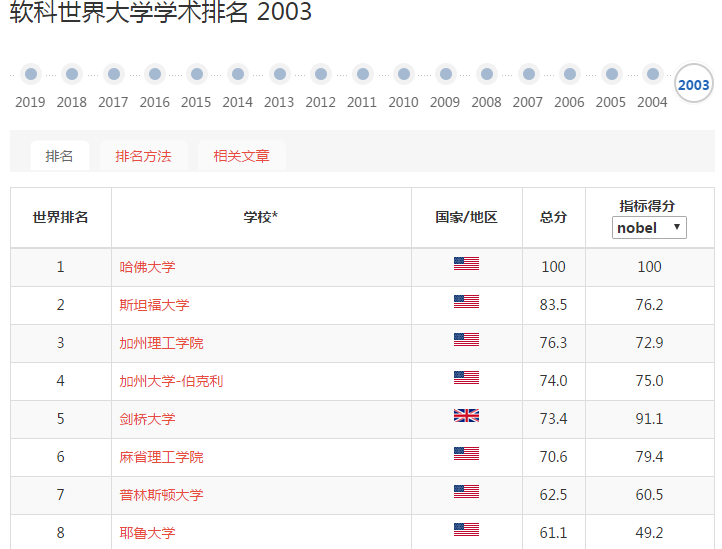
在http://www.zuihaodaxue.com/ARWU2003.html中的年份可以选择,我们解析的页面就有了:
"http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
初步获取页面的html信息的代码:
def get_one_page(year):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
response=requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
except RequestException:
print('爬取失败')
我们在页面上进行检查:

数据是存储在表格中的,这样我们就可以利用pandas获取html中的数据,基本语法:
tb = pd.read_html(url)[num]
其中的num是标识网页中的第几个表格,这里只有一个表格,所以标识为0。初步的解析代码就有了:
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
return tb
我们还要将爬取下来的数据存储到csv文件中,基本代码如下:
def save_csv(tb):
start_time=time.time()
tb.to_csv(r'university.csv', mode='a', encoding='utf_8_sig', header=True, index=0)
endtime = time.time()-start_time
print('程序运行了%.2f秒' %endtime)
最后是一个主函数,别忘了还有需要导入的包:
import requests
from requests.exceptions import RequestException
import pandas as pd
import time
def main(year):
for i in range(2003,year):
html=get_one_page(i)
tb=parse_on_page(html,i)
#print(tb)
save_csv(tb)
if __name__ == "__main__":
main(2004)
运行之后,我们在同级目录下就可以看到university.csv,部分内容如下:

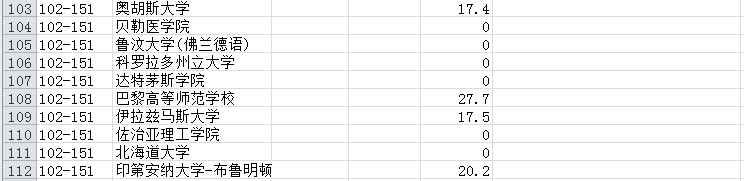
存在两个问题:
(1)缺少年份
(2)最后一列没有用
(3)国家由于是图片表示,没有爬取下来
(4)排名100以后的是一个区间
我们接下来一一解决:
(1)删掉没用的列
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = ['world rank','university', 2, 'score',4]
tb.drop([2,4],axis=1,inplace=True)
return tb
新的结果:
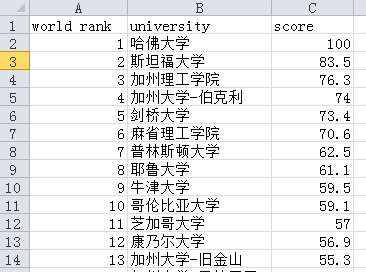
(2) 对100以后的进行唯一化,增加一列index作为排名标识
tb['index_rank'] = tb.index
tb['index_rank'] = tb['index_rank'].astype(int) + 1
(3)新增加年份
tb['year'] = i
(4)新增加国家
首先我们进行检查:


发现国家在td->a>img下的图像路径中有名字:UnitedStates。 我们可以取出src属性,并用正则匹配名字即可。
def get_country(html):
soup = BeautifulSoup(html,'lxml')
countries = soup.select('td > a > img')
lst = []
for i in countries:
src = i['src']
pattern = re.compile('flag.*\/(.*?).png')
country = re.findall(pattern,src)[0]
lst.append(country)
return lst
然后这么使用:
# read_html没有爬取country,需定义函数单独爬取
tb['country'] = get_country(html)
最终解析的整体函数如下:
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = ['world rank','university', 2, 'score',4]
tb.drop([2,4],axis=1,inplace=True)
tb['index_rank'] = tb.index
tb['index_rank'] = tb['index_rank'].astype(int) + 1
tb['year'] = i
# read_html没有爬取country,需定义函数单独爬取
tb['country'] = get_country(html)
return tb
运行之后:
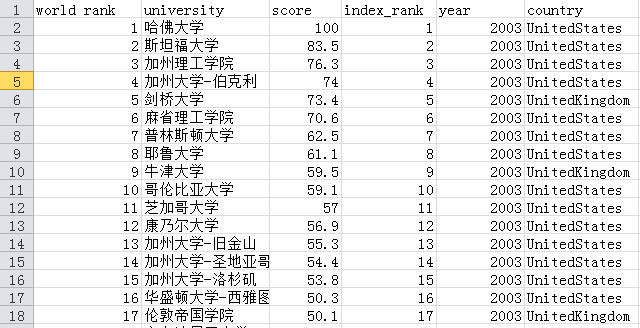
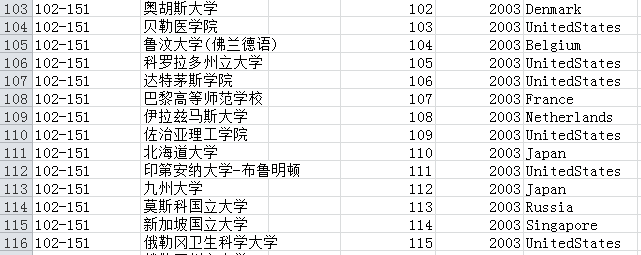
最后我们要提取属于中国部分的相关信息:
首先将年份改一下,获取到2019年为止的信息:
if __name__ == "__main__":
main(2019)
然后我们提取到中国高校的信息,直接看代码理解:
def analysis():
df = pd.read_csv('university.csv')
# 包含港澳台
# df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']] # 只包括内地
df = df.query("(country == 'China')")
df['index_rank_score'] = df['index_rank']
# 将index_rank列转为整形
df['index_rank'] = df['index_rank'].astype(int) # 美国
# df = df.query("(country == 'UnitedStates')|(country == 'USA')") #求topn名
def topn(df):
top = df.sort_values(['year','index_rank'],ascending = True)
return top[:20].reset_index()
df = df.groupby(by =['year']).apply(topn) # 更改列顺序
df = df[['university','index_rank_score','index_rank','year']]
# 重命名列
df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True) # 输出结果
df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False)
# index可以设置
本来是想爬取从2003年到2019年的,运行时发现从2005年开始,页面不一样了,多了一列:
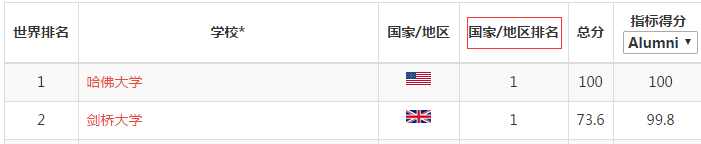
方便起见,我们就只从2005年开始了,还需要修改一下代码:
# 重命名表格列,不需要的列用数字表示
tb.columns = ['world rank','university', 2,3, 'score',5]
tb.drop([2,3,5],axis=1,inplace=True)
最后是整体代码:
import requests
from requests.exceptions import RequestException
import pandas as pd
import time
from bs4 import BeautifulSoup
import re
def get_one_page(year):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
response=requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
except RequestException:
print('爬取失败')
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = ['world rank','university', 2,3, 'score',5]
tb.drop([2,3,5],axis=1,inplace=True)
tb['index_rank'] = tb.index
tb['index_rank'] = tb['index_rank'].astype(int) + 1
tb['year'] = i
# read_html没有爬取country,需定义函数单独爬取
tb['country'] = get_country(html)
return tb
def save_csv(tb):
start_time=time.time()
tb.to_csv(r'university.csv', mode='a', encoding='utf_8_sig', header=True, index=0)
endtime = time.time()-start_time
print('程序运行了%.2f秒' %endtime)
# 提取国家名称
def get_country(html):
soup = BeautifulSoup(html,'lxml')
countries = soup.select('td > a > img')
lst = []
for i in countries:
src = i['src']
pattern = re.compile('flag.*\/(.*?).png')
country = re.findall(pattern,src)[0]
lst.append(country)
return lst
def analysis():
df = pd.read_csv('university.csv')
# 包含港澳台
# df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']] # 只包括内地
df = df.query("(country == 'China')")
df['index_rank_score'] = df['index_rank']
# 将index_rank列转为整形
df['index_rank'] = df['index_rank'].astype(int) # 美国
# df = df.query("(country == 'UnitedStates')|(country == 'USA')") #求topn名
def topn(df):
top = df.sort_values(['year','index_rank'],ascending = True)
return top[:20].reset_index()
df = df.groupby(by =['year']).apply(topn) # 更改列顺序
df = df[['university','index_rank_score','index_rank','year']]
# 重命名列
df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True) # 输出结果
df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False)
# index可以设置
def main(year):
for i in range(2005,year):
html=get_one_page(i)
tb=parse_on_page(html,i)
save_csv(tb)
print(i,'年排名提取完成完成')
analysis()
if __name__ == "__main__":
main(2019)
运行之后会有一个university_ranking.csv,部分内容如下:
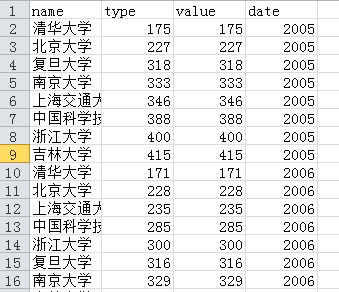
接下来就是可视化过程了。
1、 首先,到作者的github主页:
https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
2、克隆仓库文件,使用git
# 克隆项目仓库
git clone https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
# 切换到项目根目录
cd Historical-ranking-data-visualization-based-on-d3.js
# 安装依赖
npm install
这里如果git clone超时可参考:
https://www.cnblogs.com/xiximayou/p/12305209.html
需要注意的是,这里的npm是我之前装node.js装了的,没有的自己需要装以下。
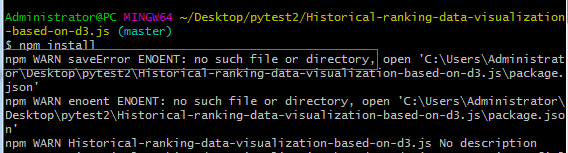
在执行npm install时会报错:
先执行:
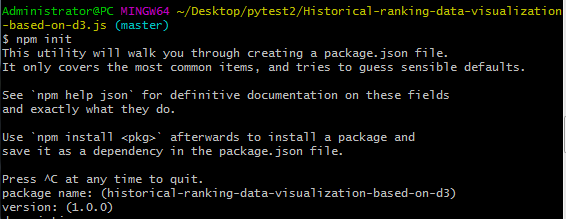
npm init
之后一直回车即可:
再执行npm install

任意浏览器打开bargraph.html网页,点击选择文件,然后选择前面输出的university_ranking.csv文件,看下效果:

只能制作动图上传了。
可以看到,有了大致的可视化效果,但还存在很多瑕疵,比如:表顺序颠倒了、字体不合适、配色太花哨等。可不可以修改呢?
当然是可以的,只需要分别修改文件夹中这几个文件的参数就可以了:
config.js 全局设置各项功能的开关,比如配色、字体、文字名称、反转图表等等功能;
color.css 修改柱形图的配色;
stylesheet.css 具体修改配色、字体、文字名称等的css样式;
visual.js 更进一步的修改,比如图表的透明度等。
知道在哪里修改了以后,那么,如何修改呢?很简单,只需要简单的几步就可以实现:
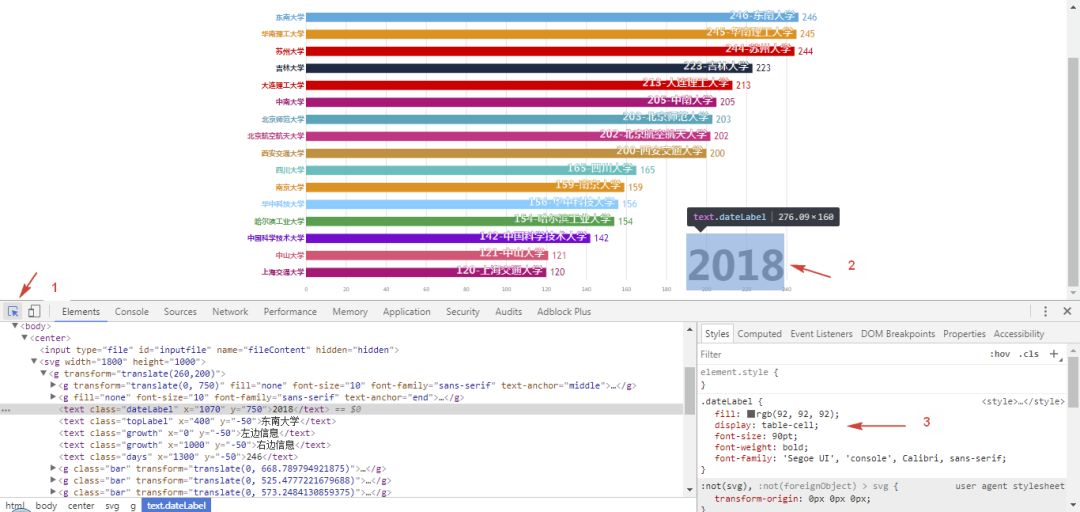
打开网页,
右键-检查,箭头指向想要修改的元素,然后在右侧的css样式表里,双击各项参数修改参数,修改完元素就会发生变化,可以不断微调,直至满意为止。
把参数复制到四个文件中对应的文件里并保存。
Git Bash运行
npm run build,之后刷新网页就可以看到优化后的效果。(我发现这一步其实不需要,而且会报错,我直接修改config.js之后运行也成功了)
这里我主要修改的是config.js的以下项:
// 倒序,使得最短的条位于最上方
reverse: true,
// 附加信息内容。
// left label
itemLabel: "本年度第一大学",
// right label
typeLabel: "世界排名",
//为了避免名称重叠
item_x: ,
// 时间标签坐标。建议x:1000 y:-50开始尝试,默认位置为x:null,y:null
dateLabel_x: ,
dateLabel_y: -,
最终效果:
至此,就全部完成了。
看起来简单,还是得要自己动手才行。
python动态柱状图图表可视化:历年软科中国大学排行的更多相关文章
- python爬虫学习(二):定向爬虫例子-->使用BeautifulSoup爬取"软科中国最好大学排名-生源质量排名2018",并把结果写进txt文件
在正式爬取之前,先做一个试验,看一下爬取的数据对象的类型是如何转换为列表的: 写一个html文档: x.html<html><head><title>This is ...
- python爬虫入门---第二篇:获取2019年中国大学排名
我们需要爬取的网站:最好大学网 我们需要爬取的内容即为该网页中的表格部分: 该部分的html关键代码为: 其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中 ...
- Python交互图表可视化Bokeh:1. 可视交互化原理| 基本设置
Bokeh pandas和matplotlib就可以直接出分析的图表了,最基本的出图方式.是面向数据分析过程中出图的工具:Seaborn相比matplotlib封装了一些对数据的组合和识别的功能:用S ...
- 使用Python的Flask框架,结合Highchart,动态渲染图表(Ajax 请求数据接口)
参考链接:https://www.highcharts.com.cn/docs/ajax 参考链接中的示例代码是使用php写的,这里改用python写. 需要注意的地方: 1.接口返回的数据格式,这个 ...
- 使用Python的Flask框架,结合Highchart,动态渲染图表
服务端动态渲染图表 参考文章链接:https://www.highcharts.com.cn/docs/dynamic-produce-html-page 参考文章是使用php写的,我这边改用pyth ...
- 百度echart如何动态生成图表
百度echart如何动态生成图表 一.总结 一句话总结: clear hideloading setOption 主要是下面三行代码: myChart.clear(); //清空画布myChart.h ...
- Python之绘图和可视化
Python之绘图和可视化 1. 启用matplotlib 最常用的Pylab模式的IPython(IPython --pylab) 2. matplotlib的图像都位于Figure对象中. 可以使 ...
- 沉淀再出发:用python画各种图表
沉淀再出发:用python画各种图表 一.前言 最近需要用python来做一些统计和画图,因此做一些笔记. 二.python画各种图表 2.1.使用turtle来画图 import turtle as ...
- ASP.NET Core +Highchart+ajax绘制动态柱状图
一.项目介绍利用前端Highchart,以及ajax向后台获取数据,绘制动态柱状图.hightchart其他实例可查看官网文档.[Highchart](https://www.highcharts.c ...
随机推荐
- Java的字节流,字符流和缓冲流对比探究
目录 一.前言 二.字节操作和字符操作 三.两种方式的效率测试 3.1 测试代码 3.2 测试结果 3.3 结果分析 四.字节顺序endian 五.综合对比 六.总结 一.前言 所谓IO,也就是Inp ...
- 解决google play上架App设置隐私政策声明问题
在我们的app上架到google play后,为了赚点小钱,就集成google ads,然而这会引发一个新的问题,那就是设置隐私政策声明的问题,通常我们会收到一封来自google play的邮件,提示 ...
- React面试题(超详细,附答案)
生命周期 组件将要挂载时触发的函数:componentWillMount 组件挂载完成时触发的函数:componentDidMount 是否要更新数据时触发的函数:shouldComponentUpd ...
- 利用Nginx设置跨域的方式
1.服务端可控,添加响应头 2.服务端不可控.通过Nginx反向代理 3.服务端不可控.通过Nginx反向代理添加响应头 第一种方法.服务端可控时,可以在服务器端添加响应头(前端+后端解决) 浏览器地 ...
- 被缠上了,小王问我怎么在 Spring Boot 中使用 JDBC 连接 MySQL
上次帮小王入了 Spring Boot 的门后,他觉得我这个人和蔼可亲.平易近人,于是隔天小王又微信我说:"二哥,快教教我,怎么在 Spring Boot 项目中使用 JDBC 连接 MyS ...
- 上位机C#通过OPCUA和西门子PLC通信
写在前面: 很多人在学习OPCUA的时候,有个非常苦恼的问题,就是没有OPCUA服务器的环境,这时候,有些人可能会想到通过类似于KepServer这样的软件来实现.那么,有没有一种方式,实现快速搭建O ...
- Rocket - devices - PLIC
https://mp.weixin.qq.com/s/FR3yeLLBqy0n-fflw-ATgg 简单介绍TLPLIC的实现. 1. GatewayPLICIO PLIC是Platform-Leve ...
- Rocket - debug - DMI
https://mp.weixin.qq.com/s/70BoeS7z4aBZK24zxdZzXA 简单介绍DMI的实现. 1. DMIConsts 定义DMI使用的常量: 其中: a. dmiDat ...
- HTML元素跟随鼠标一起移动,网页中回到顶部按钮的实现
对象跟随鼠标: 1.对象css设置绝对定位position: absolute; 2.获取鼠标坐标: 3.通过鼠标坐标计算出对象坐标位置,并设置为css定位的位置: document.onmousem ...
- Java实现 LeetCode 587 安装栅栏(图算法转换成数学问题)
587. 安装栅栏 在一个二维的花园中,有一些用 (x, y) 坐标表示的树.由于安装费用十分昂贵,你的任务是先用最短的绳子围起所有的树.只有当所有的树都被绳子包围时,花园才能围好栅栏.你需要找到正好 ...