tesseract系列(3) -- tesseract训练
tessract的训练有个工具叫 jTessBoxEditor
1、jTessBoxEditor是用java写的,首先要装java的环境
jdk-8u191-windows-x64.exe 这个我想从官网下载来的,但是一直失败,直接从搞java的同事那里要来的。
装完以后要配置一些环境变量:
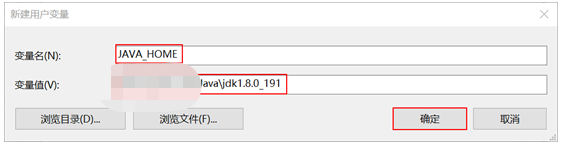
系统环境变量 --》 path ---》新建
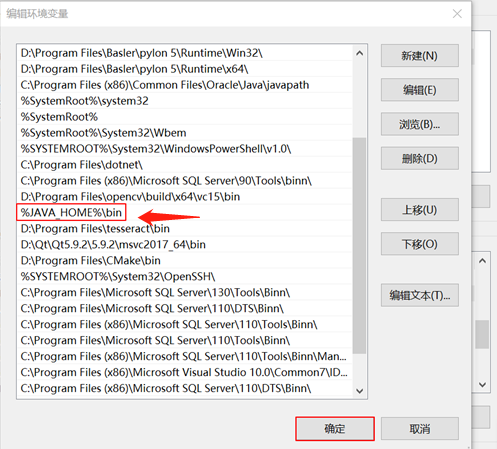
然后重启电脑。。。
2、安装jTessBoxEditor:
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
3、启动jTessBoxEditor:
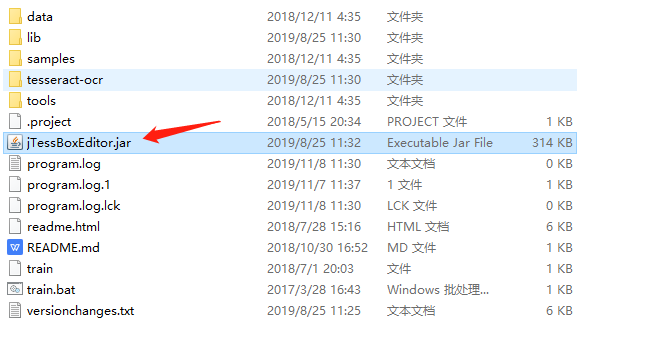
双击显示:
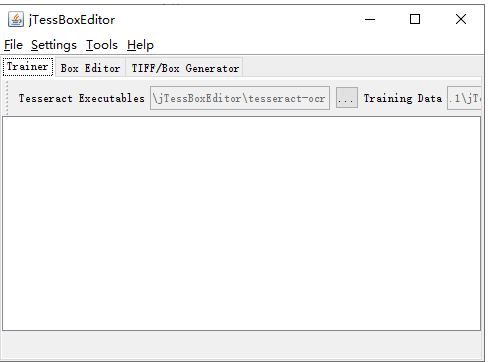
然后进入tools 点击merge tif
如果你加入的模型是tif的格式,直接找到那个tif即可。
如果你加入的图片格式是png的,
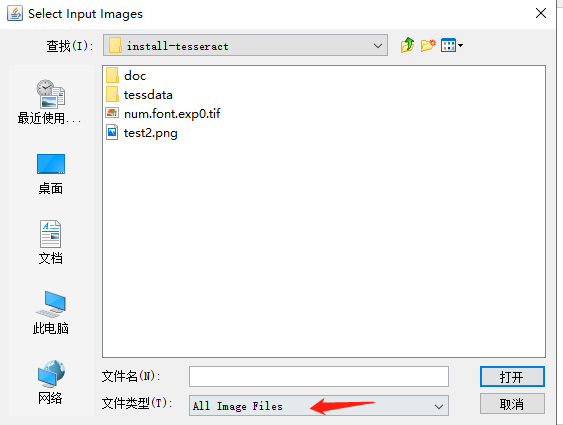
修改加入的文件格式,点击打开会显示保存的界面,将文件保存为:num.font.exp0.tif 其中,num是你自己定义的,图片要保存到tesseract的目录下。
cmd进入tesseract目录,执行命令 tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
命令解析,
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
然后: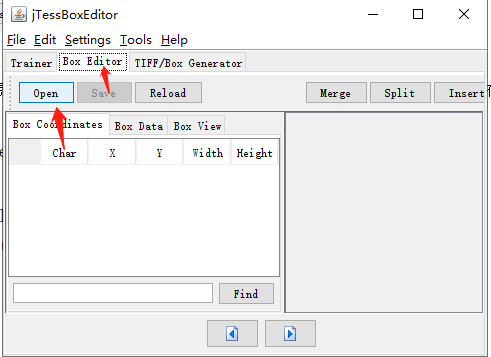
点击open打开上面保存的num.font.exp0.tif文件
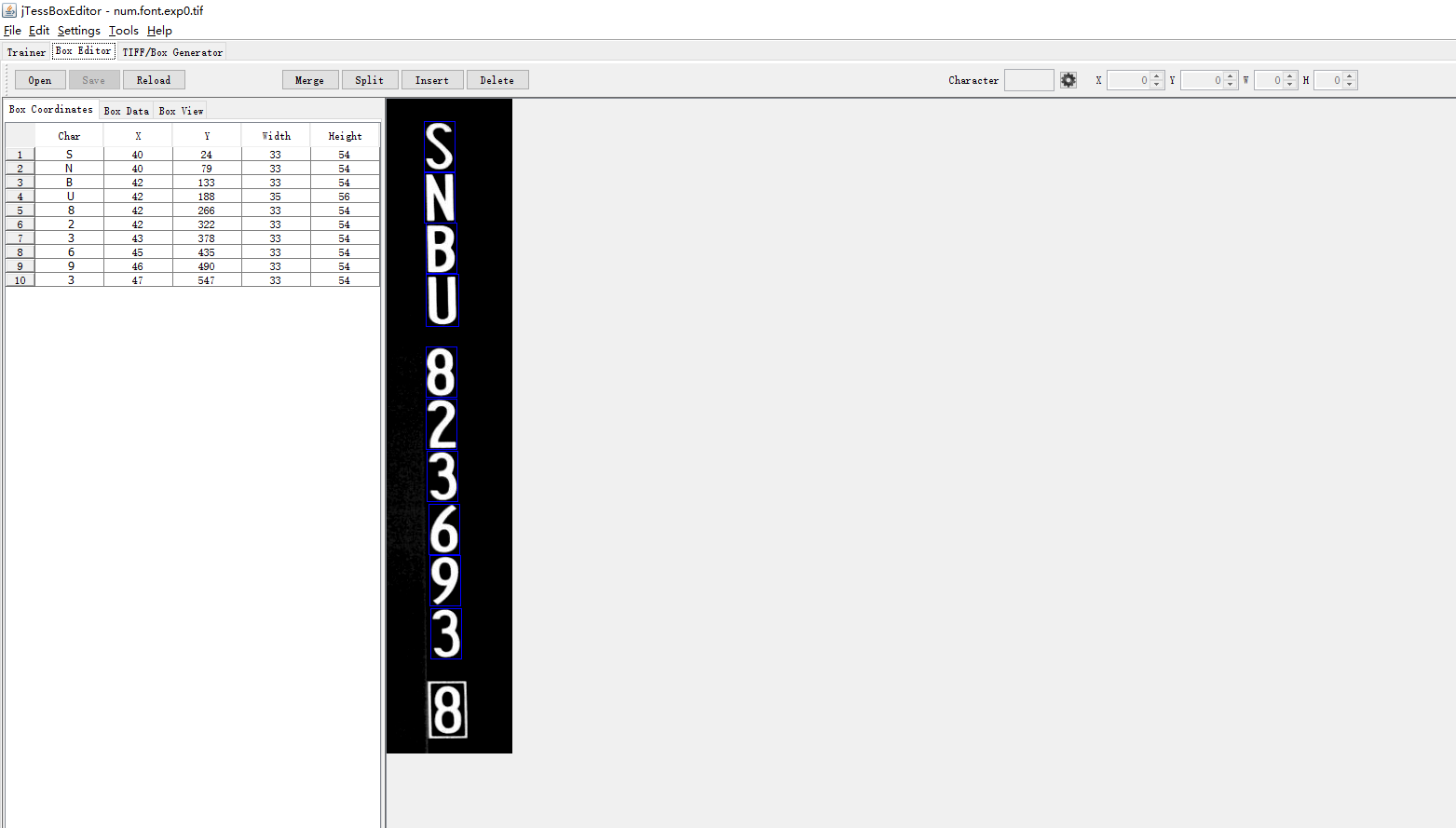
这我的demo的一张图。
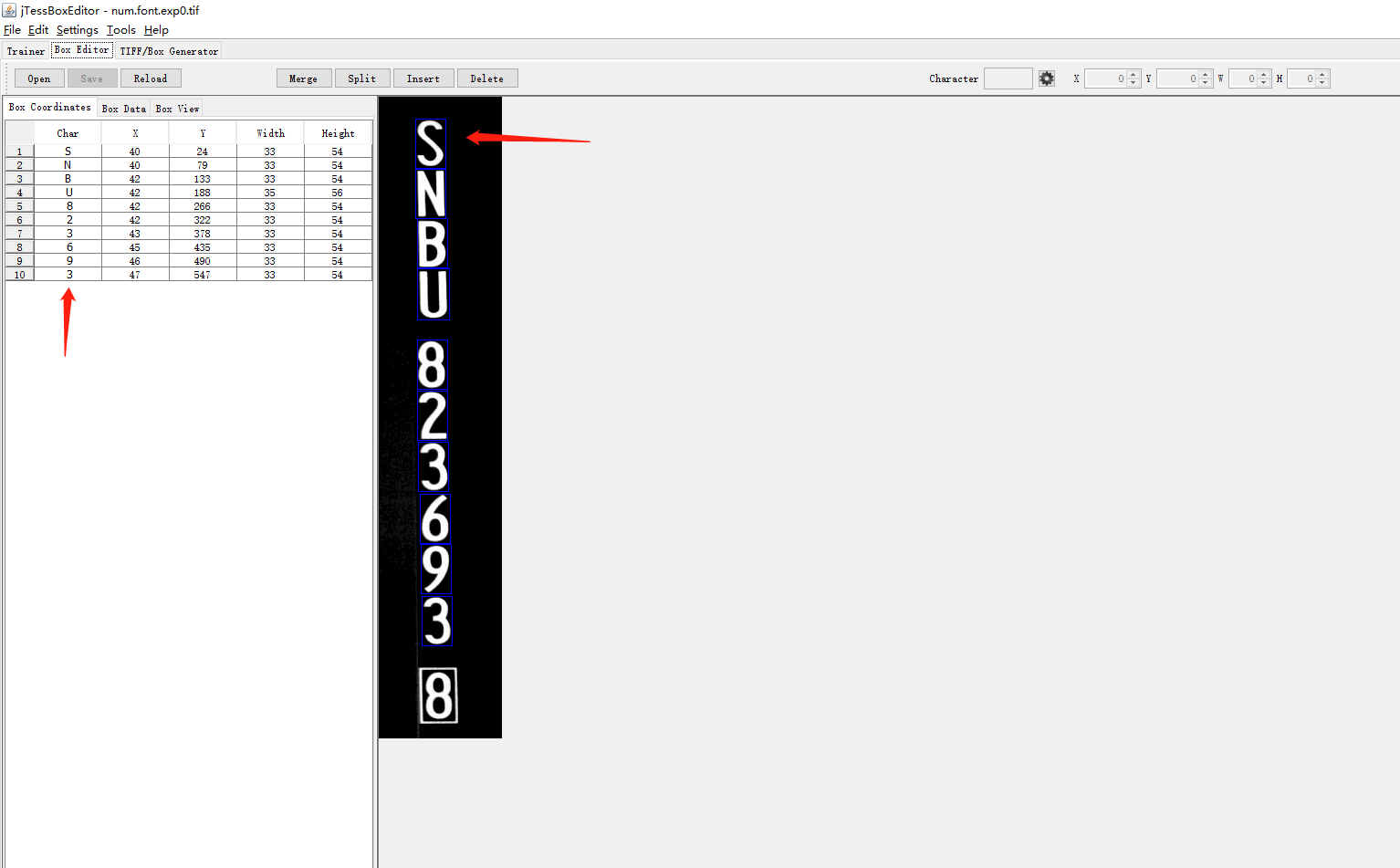
每一个char都要和左边的图相对应。如果不对应就一一修改,建议大家把这上面的所有的操作按钮都熟悉下再使用,其实很简单。
修改完以后点击save保存。
定义字体特征文件。创建一个名称为font_properties的字体特征文件。font_properties不含有BOM头,文件内容格式如下:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
font 0 0 0 0 0
这里全取值为0,表示字体不是粗体、斜体等等。
简单的说就是在tesseract的目录下新建一个font_properties,txt,然后写内容: font 0 0 0 0 0
将下面命令保存成一个批处理的bat文件,放在tesseract的目录下,双击执行。
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
pause
命令窗口会有一些错误,请看错误的解决办法:
传送门:https://www.cnblogs.com/132818Creator/p/11811841.html
something from:https://blog.csdn.net/sylsjane/article/details/83751297
tesseract系列(3) -- tesseract训练的更多相关文章
- Tesseract 3.02中文字库训练
Tesseract 3.02中文字库训练 下载chi_sim.traindata字库下载tesseract-ocr-setup-3.02.02.exe 下载jTessBoxEditor用于修改box文 ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- tesseract系列(4) -- tesseract训练问题总结
1. 每次训练模型删除目录下,上述重复的名字 2. 生成inttemp.pffmtable文件的时候,如果下述命令(1)不行的话,或者报错,使用命令(2) (1)mftraining -F font_ ...
- [转]Tesseract 3.02中文字库训练
下载chi_sim.traindata字库下载tesseract-ocr-setup-3.02.02.exe 下载地址:http://code.google.com/p/tesseract-ocr/d ...
- tesseract 中文二次训练
tesseract4.0以上版本可参考 https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00#tutorial- ...
- tesseract系列(2) -- tesseract的使用
上文说了怎么编译成库,这次说说怎么使用,先验证下编译出来的结果. 下图是debug生成的文件,里面有个tesseract的应用程序. cmd进入目录下,执行命令:tesseract eurotext. ...
- tesseract系列(1) -- tesseract用vs编译成库
1.下载teseract 下载地址github: https://github.com/tesseract-ocr/tesseract/releases/ 2.编译源码 源码的编译有两种方式 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
随机推荐
- Java连载69-接受输入、用数组模拟栈
一.编写一个酒店管理系统 1.直接上代码 package com.bjpowernode.java_learning; public class D69_1_ { //编写一个程序模拟酒店的管理系 ...
- Golang---BASE64编码原理
BASE64编码概念 Base64 是一种基于64个可打印字符来表示二进制数据的表示方法.在 Base64中可打印字符包括字母 A-Z, a-z, 数字 0-9,这样共有 62 个字符,另外两个可打印 ...
- XML--XML Schema Definition(二)
参考 http://www.w3school.com.cn/schema/index.asp XSD 简易元素 XML Schema 可定义 XML 文件的元素. 简易元素指那些只包含文本的元素.它不 ...
- 进度3_家庭记账本App_Fragment使用SQLite实现简单存储及查询
AddFragment.java: package com.example.familybooks; import android.content.ContentValues; import andr ...
- Python说文解字_Python之多任务_01
Python 之 多任务: Python之多任务是现在多任务编程运用Python语言为载体的一种体现.其中涵盖:进程.线程.并发等方面的内容,以及包括近些年在大数据运算.人工智能领域运用强大的GPU运 ...
- (转)绝对路径${pageContext.request.contextPath}用法及其与web.xml中Servlet的url-pattern匹配过程
以系统的一个“添加商品”的功能为例加以说明,系统页面为add.jsp,如图一所示: 图一 添加商品界面 系统的代码目录结构及add.jsp代码如图二所示: 图二 系统的代码目录结构及add.js ...
- 吴裕雄--天生自然 JAVASCRIPT开发学习:Date(日期) 对象
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- ELK简单配置
input { file { path => ["/usr/local/kencery/tomcat/logs/catalina.out"] type => " ...
- h5-携程页面小案例-伸缩盒子
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ubuntu虚拟机的日常使用
一.下载地址 1.ubuntu 16.04 镜像下载 二.上网 1.IP地址设置 1)参考网址1:ubuntu修改IP地址和网关的方法 2)参考网址2:ubuntu如何修改IP地址.和apt源 2)参 ...