[Udemy] Recommender Systems and Deep Learning in Python
1. Welcome
主要讲四部分内容:
non-personized systems
popularity: 基于流行度或者最大利益化的推荐。 缺点也明显:你可能在特殊地方有些特殊需求, 或者你本来就是大多数人不一样
Association: 找出订单里一起下单的物品的相关性,一般有Aproiri, FP 等算法
collaborative filtering
matrix factorization (and its variant like probablistic matrix factorization), also known as SVD
Deep learning

2. Simple recommentation systems
基于popularity 的推荐要考虑时效性,比如一则新闻虽然曾经是爆炸性的阅读量很多,但是不合适出现新闻的推荐中,这就需要在popularity 和 age(时间老化) 之间做平衡.
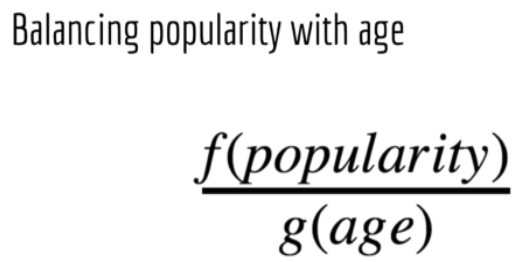
具体地,Hacker News 网站用的公式为:也叫 rank formula
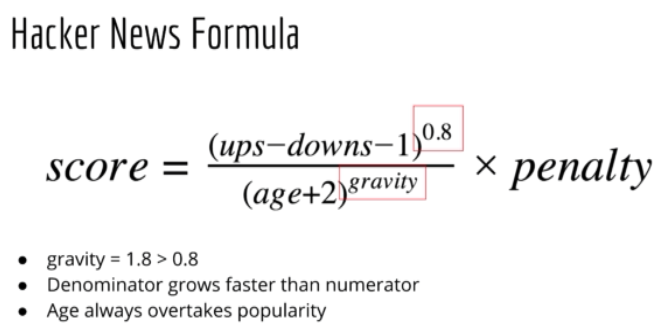
另一个具体的例子是Reddit:

如果平均值一样,那么需要考虑rating 个数,可以参考下面公式:

google 的 PageRank 算法是基于 Markov 模型的. Markov 模型就是NLP里面的unigram, bigram 的概念,基于前面的条件算出后面结果出现的概率.

怎么评估 Rank 结果

3. Collaborative Filtering
user-user CF - based on user-user similarity
item-item CF - based on item-item similarity
参考资料[2] 里面有具体的代码,不过不是矩阵实现,最好看我翻译的另一篇文章 Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统, 这里有矩阵实现, 更快而且我觉得更明白.
4. Matrix Factorization & Deep Leanring
4.1 Matrix Factorization

1. 先来个最basic 版的matrix factorization 的公式,就是把矩阵X分解成 X=WU. metric 用 Sum Squere Error.

2. 再考虑 bias, user bias 和 item bias


3. formulas: with regularization


4. MF with SVD, 确定是不能有missing data (MF 和SVD 很相似,MF有两个矩阵U和V, SVD 有3个 U,S,V)

5. Probabilistic Matrix Factorization, 没看懂,只能拷些图片在这里了



6. Bayesian Matrix Factorization, 也没看懂,讲者说是optional 就不看了
7. matrix factorization in Keres
# keras model
u = Input(shape=(1,))
m = Input(shape=(1,))
u_embedding = Embedding(N, K, embeddings_regularizer=l2(reg))(u) # (N, 1, K)
m_embedding = Embedding(M, K, embeddings_regularizer=l2(reg))(m) # (N, 1, K) # subsubmodel = Model([u, m], [u_embedding, m_embedding])
# user_ids = df_train.userId.values[0:5]
# movie_ids = df_train.movie_idx.values[0:5]
# print("user_ids.shape", user_ids.shape)
# p = subsubmodel.predict([user_ids, movie_ids])
# print("p[0].shape:", p[0].shape)
# print("p[1].shape:", p[1].shape)
# exit() u_bias = Embedding(N, 1, embeddings_regularizer=l2(reg))(u) # (N, 1, 1)
m_bias = Embedding(M, 1, embeddings_regularizer=l2(reg))(m) # (N, 1, 1)
x = Dot(axes=2)([u_embedding, m_embedding]) # (N, 1, 1) # submodel = Model([u, m], x)
# user_ids = df_train.userId.values[0:5]
# movie_ids = df_train.movie_idx.values[0:5]
# p = submodel.predict([user_ids, movie_ids])
# print("p.shape:", p.shape)
# exit() x = Add()([x, u_bias, m_bias])
x = Flatten()(x) # (N, 1)
model = Model(inputs=[u, m], outputs=x)
model.compile(
loss='mse',
# optimizer='adam',
# optimizer=Adam(lr=0.01),
optimizer=SGD(lr=0.08, momentum=0.9),
metrics=['mse'],
)
4. 2 Deep Learning
1. 在matrix factorization 上加了deep network, 形成的 deep learning. 前面讲的 matrix factorization 只是linear model, deep learning 会提供 non-linear 能力,所以理论上比只有前面棕色部分(matrix factorization部分)好
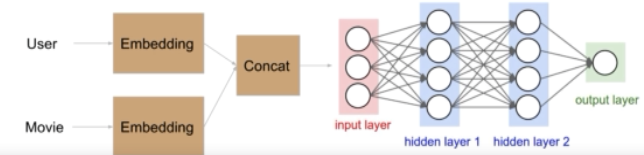
2. 还可以先分支网络,然后再合并,课程里叫 residual, 我觉得不是computer vision里面的 resnet 的概念.

3. 还可以用 AutoEncoder (AutoRec), 这个算法本来是用来复原图片的. model.fit(X, X) not model.fix(X, Y).

AutoRec 比deep learning 快,原因如下

AutoRec 算法要注意一个问题,因为这个算法是用来反推输入X的,输出就是预测的输入,所有网络可能会直接copy back, 有欺骗性。因此,我们不能直接用 test_set 来预测 test_set 的输出,而是用train_set 来预测test_set, 看下面代码


5. Retricted Boltzmann Machines (RBMs) for Collaborative Filtering
受限波兹曼机(RBMs)是波兹曼机的简化版,不是全部连接,只需要 visible nodes 和 hidden nodes 连接就行.
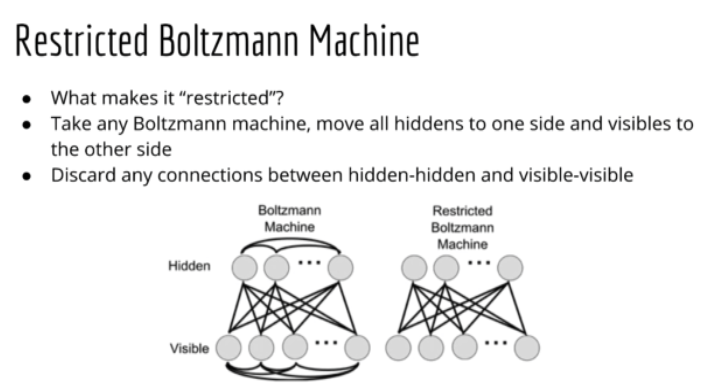
确实有点点难懂...
Others:
Explore-Exploit dilemma 概念: 比如,你在youtube上看视屏学炒鸡蛋,你看了很多视屏学会了炒鸡蛋,结果因为看的视屏多,在你学会了炒鸡蛋过后youtube还是老是给你推荐炒鸡蛋视屏,这就是explore-exploit dilemma, 数据越多结果越差.
Ref:
- [Udemy] Recommender Sytem and Deep Learning in Python
- https://github.com/mashuai191/machine_learning_examples/tree/master/recommenders
- 谷歌PageRank算法简单解释
[Udemy] Recommender Systems and Deep Learning in Python的更多相关文章
- Machine and Deep Learning with Python
Machine and Deep Learning with Python Education Tutorials and courses Supervised learning superstiti ...
- Conclusions about Deep Learning with Python
Conclusions about Deep Learning with Python Last night, I start to learn the python for deep learn ...
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
- Deep learning with Python 学习笔记(8)
Keras 函数式编程 利用 Keras 函数式 API,你可以构建类图(graph-like)模型.在不同的输入之间共享某一层,并且还可以像使用 Python 函数一样使用 Keras 模型.Ker ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化 循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息. ...
- Deep learning with Python 学习笔记(5)
本节讲深度学习用于文本和序列 用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet) 与其他所有神经网络一 ...
随机推荐
- [常用类]String 类
String 字符串是常量,一旦被赋值,就不能被更改. String str = “abc”: // "abc" 可以堪称是一个字符串对象 str = “def“: // 当把 & ...
- 洛谷 - P3649 - 回文串 - 回文自动机
https://www.luogu.org/problem/P3649 #include <bits/stdc++.h> using namespace std; typedef long ...
- Java解析XML介绍
开发十年,就只剩下这套架构体系了! >>> XML解析器提供了访问或修改用来表示数据的xml文件的能力.Java中提供了多种方式来解析xml文件. 主要分为两类,包括解析XML文 ...
- Python2/3 安装各类包的教程
1.pycryptodome(pyCrypto) pyCrypto包已经失效了,需要替换为pycryptodome 有SSR直接 pip install pycryptodome 国内用 pip in ...
- jQuery——复选框操作
学习jQuer对表单.表格操作的过程中,按照书上的例子发现一个问题: <!DOCTYPE html> <html> <head> <title>复选框应 ...
- window.onload和document.ready的区别
window.onload和document.ready虽然两个方法的运行效果都一样,但他们之间是存在着区别的: 一.从执行的时间 window.onload在dom文档结构加载完毕以后就可以执行,不 ...
- 关于print的一点秀操作
我们在玩 Python 的时候 常常会使用到 print 这个函数 主要用它来打印一些输出 这样我们可以更加方便的知道 程序的运行情况 我们常常这样操作 不过不是很骚 有时候我们想更加直观的看到我 ...
- Python3安装教程
目录 1. 推荐阅读 2. 安装包下载 3. 安装步骤 1. 推荐阅读 Python基础入门一文通 | Python2 与Python3及VSCode下载和安装.PyCharm破解与安装.Python ...
- Asp.Net 保存Session的三种方式
一.默认方式,保存在IIS进程中保存在IIS进程中是指把Session数据保存在IIS的运行的进程中,也就是inetinfo.exe这个进程中,这也是默认的Session的存方式,也是最常用的. 这种 ...
- Oracle 数字转为字符串 to_char()
格式:TO_CHAR(number,'format_model') 9 -->Represents a number 0 --> Forces a zero to be displayed ...