Flink组件及特性
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。就框架本身与应用场景来说,Flink 更相似与 Storm。
1、Flink组件栈
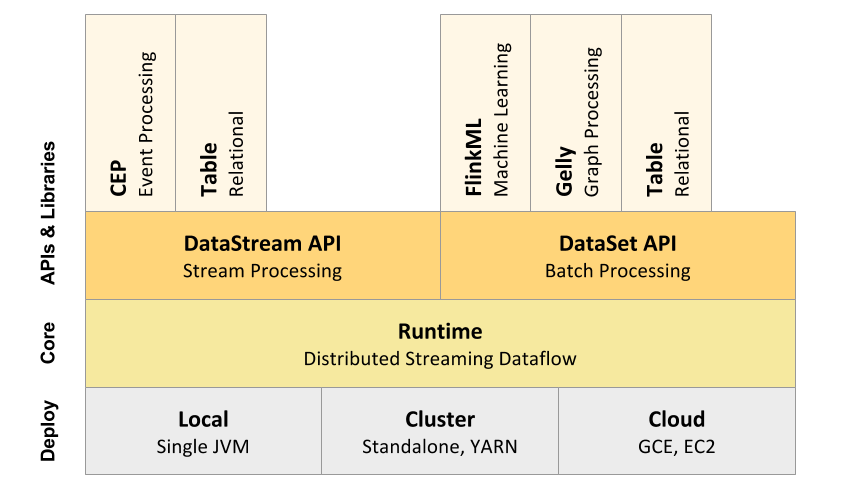
- 部署模式
Flink能部署在云上或者局域网中,提供了所中部署方案(Local、Cluster、Cloud),能在独立集群或者在被YARN或Mesos管理的集群上运行。
- 运行期
Flink的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理,这跟批次处理有很大不同。这个保证了上面说的那些Flink弹性和高性能的特性。
- API
DataStream API和DataSet API都会使用单独编译的处理方式(Separate compilation process)生成JobGraph。DataSet API使用Optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
- 代码库
Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,事件处理的CEP
2、Flink特性
- 流处理特性
ü 支持高吞吐、低延迟、高性能的流处理
ü 支持带有事件时间的窗口(Window)操作
ü 支持有状态计算的Exactly-once语义
ü 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
ü 支持具有Backpressure功能的持续流模型
ü 支持基于轻量级分布式快照(Snapshot)实现的容错
ü 一个运行时同时支持Batch on Streaming处理和Streaming处理
ü Flink在JVM内部实现了自己的内存管理
ü 支持迭代计算
ü 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
- API支持
ü 对Streaming数据类应用,提供DataStream API
ü 对批处理类应用,提供DataSet API(支持Java/Scala)
- Libraries支持
ü 支持机器学习(FlinkML)
ü 支持图分析(Gelly)
ü 支持关系数据处理(Table)
ü 支持复杂事件处理(CEP)
- 整合支持
ü 支持Flink on YARN
ü 支持HDFS
ü 支持来自Kafka的输入数据
ü 支持Apache HBase
ü 支持Hadoop程序
ü 支持Tachyon
ü 支持ElasticSearch
ü 支持RabbitMQ
ü 支持Apache Storm
ü 支持S3
ü 支持XtreemFS
Flink组件及特性的更多相关文章
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- 从flink-example分析flink组件(1)WordCount batch实战及源码分析
上一章<windows下flink示例程序的执行> 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar),那么我们为什么要使用fli ...
- 【分布式架构】--- 基于Redis组件的特性,实现一个分布式限流
分布式---基于Redis进行接口IP限流 场景 为了防止我们的接口被人恶意访问,比如有人通过JMeter工具频繁访问我们的接口,导致接口响应变慢甚至崩溃,所以我们需要对一些特定的接口进行IP限流,即 ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Flink知识点
1. Flink.Storm.Sparkstreaming对比 Storm只支持流处理任务,数据是一条一条的源源不断地处理,而MapReduce.spark只支持批处理任务,spark-streami ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
随机推荐
- cve-2019-1609,Harbor任意管理员注册漏洞复现
一.Harbor介绍 以Docker为代表的容器技术的出现,改变了传统的交付方式.通过把业务及其依赖的环境打包进Docker镜像,解决了开发环境和生产环境的差异问题,提升了业务交付的效率.如何高效地管 ...
- rsync+inotify实时数据同步多目录实战
rsync+inotify实时数据同步多目录实战 inotify配置是建立在rsync服务基础上的配置过程 操作系统 主机名 网卡eth0 默认网关 用途 root@58server1 1 ...
- python实例31[列出目录下所有的文件到txt]
代码: (使用os.listdir) import os def ListFilesToTxt(dir,file,wildcard,recursion): exts = wildcard.sp ...
- 签发的用户认证token超时刷新策略
https://segmentfault.com/a/1190000014545422
- 树莓派开机自动启动Chomium浏览器并打开指定网页
树莓派开机自动启动Chomium浏览器并打开指定网页 cd /home/pi/.config mkdir autostart cd autostart vi my.desktop [Desktop E ...
- git的clone和github的fork
git的clone是从github上下载下来,clone到项目里面,fork是在本地修改后再提交到github上,在github上用request来进行提交,经作者确认后可以合同到mast分支上
- LeetCode - LRU怎么将书架上的旧书完美淘汰呢
你有一排书架,有空时会拿些书来看,经常性会买些新书.无奈书架容量有限,当新买的书放不下时,需要一个策略将旧书淘汰. LRU(最近最少使用)缓存淘汰机制正合适. 1)新买的书放在最左侧. 2)最近常看的 ...
- 全方面了解和学习PHP框架PHP培训教程
PHP成为最流行的脚本语言有许多原因:灵活性,易用性等等.对于项目开发来说,我们通常需要一个PHP框架来代替程序员完成那些重复的部分.本文,兄弟连PHP培训 将对PHP框架进行全面解析. PHP框架是 ...
- 苹果手机上input的button按钮颜色显示问题
在苹果手机上的input按钮自带效果,需要加上outline:0px; -webkit-appearance:none; 清除原有样式,同时苹果手机上的input按钮自带圆角需要按需要去掉 input ...
- Oracle生成ASH报告
1.ASH (Active SessionHistory) ASH以V$SESSION为基础,每秒采样一次,记录活动会话等待的事件.不活动的会话不会采样,采样工作由新引入的后台进程MMNL来完成. v ...