Flink组件及特性
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。就框架本身与应用场景来说,Flink 更相似与 Storm。
1、Flink组件栈
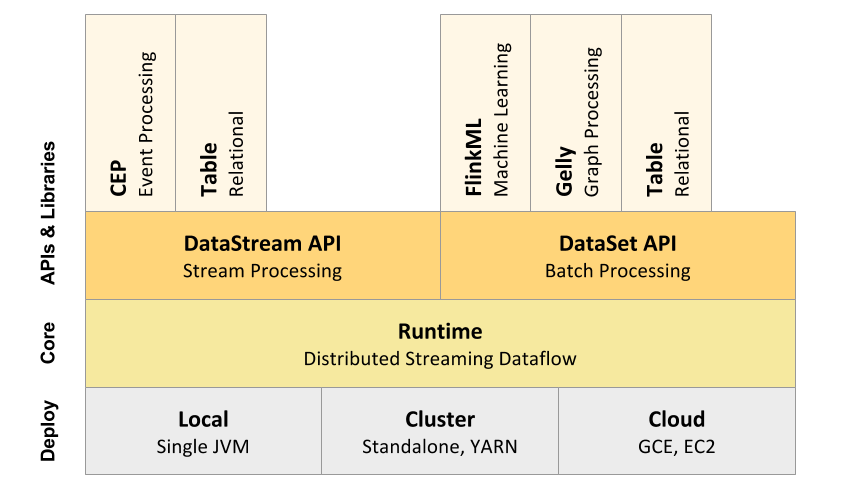
- 部署模式
Flink能部署在云上或者局域网中,提供了所中部署方案(Local、Cluster、Cloud),能在独立集群或者在被YARN或Mesos管理的集群上运行。
- 运行期
Flink的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理,这跟批次处理有很大不同。这个保证了上面说的那些Flink弹性和高性能的特性。
- API
DataStream API和DataSet API都会使用单独编译的处理方式(Separate compilation process)生成JobGraph。DataSet API使用Optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
- 代码库
Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,事件处理的CEP
2、Flink特性
- 流处理特性
ü 支持高吞吐、低延迟、高性能的流处理
ü 支持带有事件时间的窗口(Window)操作
ü 支持有状态计算的Exactly-once语义
ü 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
ü 支持具有Backpressure功能的持续流模型
ü 支持基于轻量级分布式快照(Snapshot)实现的容错
ü 一个运行时同时支持Batch on Streaming处理和Streaming处理
ü Flink在JVM内部实现了自己的内存管理
ü 支持迭代计算
ü 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
- API支持
ü 对Streaming数据类应用,提供DataStream API
ü 对批处理类应用,提供DataSet API(支持Java/Scala)
- Libraries支持
ü 支持机器学习(FlinkML)
ü 支持图分析(Gelly)
ü 支持关系数据处理(Table)
ü 支持复杂事件处理(CEP)
- 整合支持
ü 支持Flink on YARN
ü 支持HDFS
ü 支持来自Kafka的输入数据
ü 支持Apache HBase
ü 支持Hadoop程序
ü 支持Tachyon
ü 支持ElasticSearch
ü 支持RabbitMQ
ü 支持Apache Storm
ü 支持S3
ü 支持XtreemFS
Flink组件及特性的更多相关文章
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- 从flink-example分析flink组件(1)WordCount batch实战及源码分析
上一章<windows下flink示例程序的执行> 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar),那么我们为什么要使用fli ...
- 【分布式架构】--- 基于Redis组件的特性,实现一个分布式限流
分布式---基于Redis进行接口IP限流 场景 为了防止我们的接口被人恶意访问,比如有人通过JMeter工具频繁访问我们的接口,导致接口响应变慢甚至崩溃,所以我们需要对一些特定的接口进行IP限流,即 ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Flink知识点
1. Flink.Storm.Sparkstreaming对比 Storm只支持流处理任务,数据是一条一条的源源不断地处理,而MapReduce.spark只支持批处理任务,spark-streami ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
随机推荐
- hier - 文件系统描述
DESCRIPTION 描述 一个典型的Linux系统具有以下几个目录: / 根目录,是所有目录树开始的地方. /bin 此目录下包括了单用户方式及系统启动或修复所用到的所有执行程序. /boot 包 ...
- :OpenCV人脸识别Fisherface算法源码分析
https://blog.csdn.net/loveliuzz/article/details/73875904
- [转载]一个支持Verilog的Vim插件——自动插入always块
原文地址:一个支持Verilog的Vim插件--自动插入always块作者:hover 插件支持always块的自动插入,如果用户要插入时序always块,需要在端口声明中标志时钟和异步复位信号(仅支 ...
- 五种I/O模型
文档地址:https://www.cse.huji.ac.il/course/2004/com1/Exercises/Ex4/I.O.models.pdf 五种I/O模型: 1. blocking ...
- Java并发编程实战 第10章 避免活跃性危险
死锁 经典的死锁:哲学家进餐问题.5个哲学家 5个筷子 如果没有哲学家都占了一个筷子 互相等待筷子 陷入死锁 数据库设计系统中一般有死锁检测,通过在表示等待关系的有向图中搜索循环来实现. JVM没有死 ...
- 流式布局和viewport
流式布局 百分比布局,非固定宽度,内容向两边填充,流动的布局. viewport(视口) PC端的网页在手机端的浏览器显示是不会出现网页的,这是因为移动端的网页不是直接放在移动端的浏览器中,而是放在移 ...
- strtok的使用
/* strtok函数的使用 */ #include <stdio.h> #include <stdlib.h> #include <string.h> // 函数 ...
- Linux系统中的硬件问题如何排查?(6)
Linux系统中的硬件问题如何排查?(6) 2013-03-27 10:32 核子可乐译 51CTO.com 字号:T | T 在Linux系统中,对于硬件故障问题的排查可能是计算机管理领域最棘手的工 ...
- java 责任链接模式
- 【NOIP2016提高A组模拟10.15】打膈膜
题目 分析 贪心, 先将怪物按生命值从小到大排序(显然按这个顺序打是最优的) 枚举可以发对少次群体攻击, 首先将所有的群体攻击发出去, 然后一个一个怪物打,当当前怪物生命值大于2,如果还有魔法值就放重 ...