从零到千万用户,我是如何一步步优化MySQL数据库的?
写在前面
很多小伙伴留言说让我写一些工作过程中的真实案例,写些啥呢?想来想去,写一篇我在以前公司从零开始到用户超千万的数据库架构升级演变的过程吧。
本文记录了我之前初到一家创业公司,从零开始到用户超千万,系统压力暴增的情况下是如何一步步优化MySQL数据库的,以及数据库架构升级的演变过程。升级的过程极具技术挑战性,也从中收获不少。希望能够为小伙伴们带来实质性的帮助。
业务背景
我之前呆过一家创业工作,是做商城业务的,商城这种业务,表面上看起来涉及的业务简单,包括:用户、商品、库存、订单、购物车、支付、物流等业务。但是,细分下来,还是比较复杂的。这其中往往会牵扯到很多提升用户体验的潜在需求。例如:为用户推荐商品,这就涉及到用户的行为分析和大数据的精准推荐。如果说具体的技术的话,那肯定就包含了:用户行为日志埋点、采集、上报,大数据实时统计分析,用户画像,商品推荐等大数据技术。
公司的业务增长迅速,仅仅2年半不到的时间用户就从零积累到千万级别,每天的访问量几亿次,高峰QPS高达上万次每秒。数据的写压力来源于用户下单,支付等操作,尤其是赶上双十一大促期间,系统的写压力会成倍增长。然而,读业务的压力会远远大于写压力,据不完全统计,读业务的请求量是写业务的请求量的50倍左右。
接下来,我们就一起来看看数据库是如何升级的。
最初的技术选型
作为创业公司,最重要的一点是敏捷,快速实现产品,对外提供服务,于是我们选择了公有云服务,保证快速实施和可扩展性,节省了自建机房等时间。整体后台采用的是Java语言进行开发,数据库使用的MySQL。整体如下图所示。
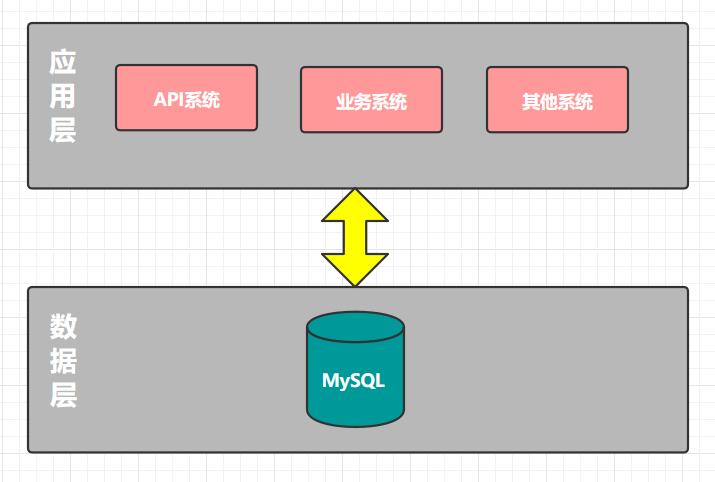
读写分离
随着业务的发展,访问量的极速增长,上述的方案很快不能满足性能需求。每次请求的响应时间越来越长,比如用户在H5页面上不断刷新商品,响应时间从最初的500毫秒增加到了2秒以上。业务高峰期,系统甚至出现过宕机。在这生死存亡的关键时刻,通过监控,我们发现高期峰MySQL CPU使用率已接近80%,磁盘IO使用率接近90%,slow query(慢查询)从每天1百条上升到1万条,而且一天比一天严重。数据库俨然已成为瓶颈,我们必须得快速做架构升级。
当Web应用服务出现性能瓶颈的时候,由于服务本身无状态,我们可以通过加机器的水平扩展方式来解决。 而数据库显然无法通过简单的添加机器来实现扩展,因此我们采取了MySQL主从同步和应用服务端读写分离的方案。
MySQL支持主从同步,实时将主库的数据增量复制到从库,而且一个主库可以连接多个从库同步。利用此特性,我们在应用服务端对每次请求做读写判断,若是写请求,则把这次请求内的所有DB操作发向主库;若是读请求,则把这次请求内的所有DB操作发向从库,如下图所示。
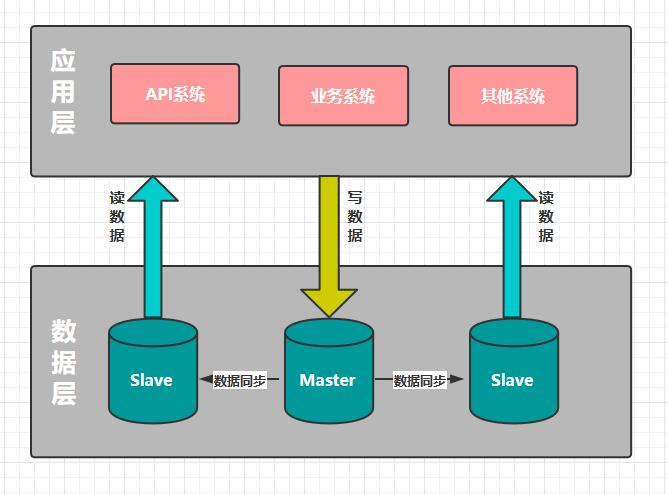
实现读写分离后,数据库的压力减少了许多,CPU使用率和IO使用率都降到了5%以内,Slow Query(慢查询)也趋近于0。主从同步、读写分离给我们主要带来如下两个好处:
减轻了主库(写)压力:商城业务主要来源于读操作,做读写分离后,读压力转移到了从库,主库的压力减小了数十倍。
从库(读)可水平扩展(加从库机器):因系统压力主要是读请求,而从库又可水平扩展,当从库压力太时,可直接添加从库机器,缓解读请求压力。
当然,没有一个方案是万能的。读写分离,暂时解决了MySQL压力问题,同时也带来了新的挑战。业务高峰期,用户提交完订单,在我的订单列表中却看不到自己提交的订单信息(典型的read after write问题);系统内部偶尔也会出现一些查询不到数据的异常。通过监控,我们发现,业务高峰期MySQL可能会出现主从复制延迟,极端情况,主从延迟高达数秒。这极大的影响了用户体验。
那如何监控主从同步状态?在从库机器上,执行show slave status,查看Seconds_Behind_Master值,代表主从同步从库落后主库的时间,单位为秒,若主从同步无延迟,这个值为0。MySQL主从延迟一个重要的原因之一是主从复制是单线程串行执行(高版本MySQL支持并行复制)。
那如何避免或解决主从延迟?我们做了如下一些优化:
- 优化MySQL参数,比如增大innodb_buffer_pool_size,让更多操作在MySQL内存中完成,减少磁盘操作。
- 使用高性能CPU主机。
- 数据库使用物理主机,避免使用虚拟云主机,提升IO性能。
- 使用SSD磁盘,提升IO性能。SSD的随机IO性能约是SATA硬盘的10倍甚至更高。
- 业务代码优化,将实时性要求高的某些操作,强制使用主库做读操作。
- 升级高版本MySQL,支持并行主从复制。
垂直分库
读写分离很好的解决了读压力问题,每次读压力增加,可以通过加从库的方式水平扩展。但是写操作的压力随着业务爆发式的增长没有得到有效的缓解,比如用户提交订单越来越慢。通过监控MySQL数据库,我们发现,数据库写操作越来越慢,一次普通的insert操作,甚至可能会执行1秒以上。
另一方面,业务越来越复杂,多个应用系统使用同一个数据库,其中一个很小的非核心功能出现延迟,常常影响主库上的其它核心业务功能。这时,主库成为了性能瓶颈,我们意识到,必需得再一次做架构升级,将主库做拆分,一方面以提升性能,另一方面减少系统间的相互影响,以提升系统稳定性。这一次,我们将系统按业务进行了垂直拆分。如下图所示,将最初庞大的数据库按业务拆分成不同的业务数据库,每个系统仅访问对应业务的数据库,尽量避免或减少跨库访问。
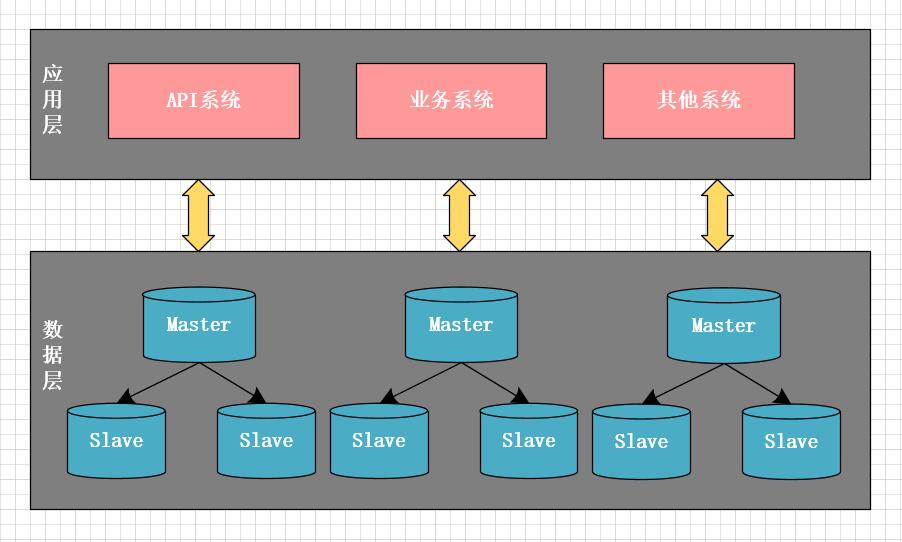
垂直分库过程,我们也遇到不少挑战,最大的挑战是:不能跨库join,同时需要对现有代码重构。单库时,可以简单的使用join关联表查询;拆库后,拆分后的数据库在不同的实例上,就不能跨库使用join了。
例如,通过商家名查询某个商家的所有订单,在垂直分库前,可以join商家和订单表做查询,也可以直接使用子查询,如下如示:
select * from tb_order where supplier_id in (select id from supplier where name=’商家名称’);
分库后,则要重构代码,先通过商家名查询商家id,再通过商家id查询订单表,如下所示:
select id from supplier where name=’商家名称’
select * from tb_order where supplier_id in (supplier_ids )
垂直分库过程中的经验教训,使我们制定了SQL最佳实践,其中一条便是程序中禁用或少用join,而应该在程序中组装数据,让SQL更简单。一方面为以后进一步垂直拆分业务做准备,另一方面也避免了MySQL中join的性能低下的问题。
经过近十天加班加点的底层架构调整,以及业务代码重构,终于完成了数据库的垂直拆分。拆分之后,每个应用程序只访问对应的数据库,一方面将单点数据库拆分成了多个,分摊了主库写压力;另一方面,拆分后的数据库各自独立,实现了业务隔离,不再互相影响。
水平分库
读写分离,通过从库水平扩展,解决了读压力;垂直分库通过按业务拆分主库,缓存了写压力,但系统依然存在以下隐患:
- 单表数据量越来越大。如订单表,单表记录数很快就过亿,超出MySQL的极限,影响读写性能。
- 核心业务库的写压力越来越大,已不能再进一次垂直拆分,此时的系统架构中,MySQL 主库不具备水平扩展的能力。
此时,我们需要对MySQL进一步进行水平拆分。
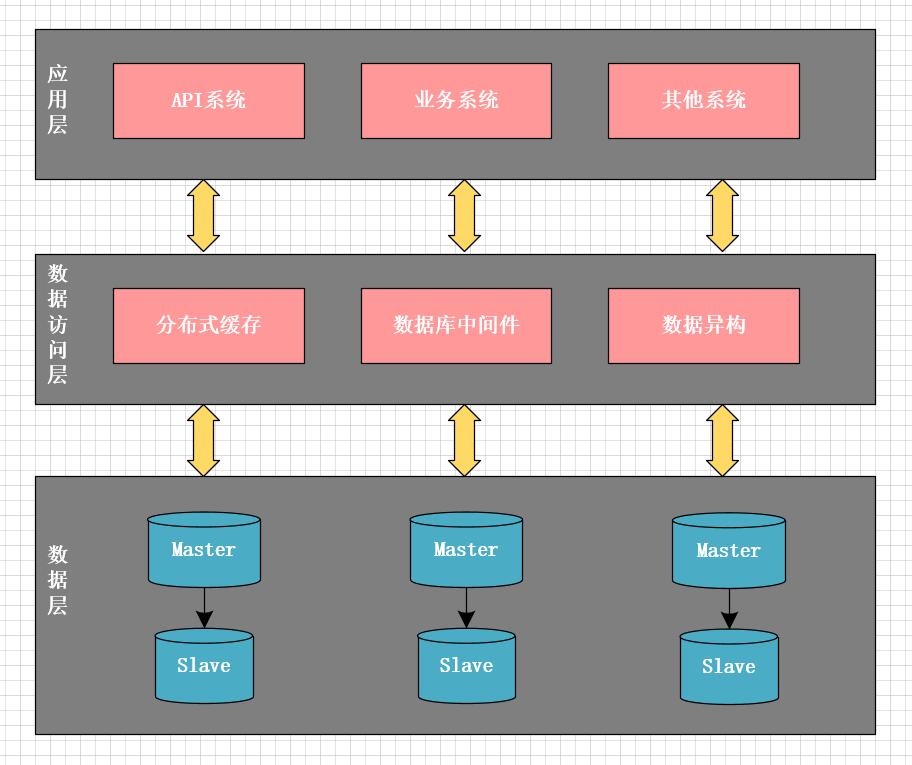
水平分库面临的第一个问题是,按什么逻辑进行拆分。一种方案是按城市拆分,一个城市的所有数据在一个数据库中;另一种方案是按订单ID平均拆分数据。按城市拆分的优点是数据聚合度比较高,做聚合查询比较简单,实现也相对简单,缺点是数据分布不均匀,某些城市的数据量极大,产生热点,而这些热点以后可能还要被迫再次拆分。按订单ID拆分则正相反,优点是数据分布均匀,不会出现一个数据库数据极大或极小的情况,缺点是数据太分散,不利于做聚合查询。比如,按订单ID拆分后,一个商家的订单可能分布在不同的数据库中,查询一个商家的所有订单,可能需要查询多个数据库。针对这种情况,一种解决方案是将需要聚合查询的数据做冗余表,冗余的表不做拆分,同时在业务开发过程中,减少聚合查询。
经过反复思考,我们最后决定按订单ID做水平分库。从架构上,将系统分为三层:
- 应用层:即各类业务应用系统
- 数据访问层:统一的数据访问接口,对上层应用层屏蔽读写分库、分表、缓存等技术细节。
- 数据层:对DB数据进行分片,并可动态的添加shard分片。
水平分库的技术关键点在于数据访问层的设计,数据访问层主要包含三部分:
- 分布式缓存
- 数据库中间件
- 数据异构中间件
而数据库中间件需要包含如下重要的功能:
- ID生成器:生成每张表的主键
- 数据源路由:将每次DB操作路由到不同的分片数据源上
ID生成器
ID生成器是整个水平分库的核心,它决定了如何拆分数据,以及查询存储-检索数据。ID需要跨库全局唯一,否则会引发业务层的冲突。此外,ID必须是数字且升序,这主要是考虑到升序的ID能保证MySQL的性能(若是UUID等随机字符串,在高并发和大数据量情况下,性能极差)。同时,ID生成器必须非常稳定,因为任何故障都会影响所有的数据库操作。
我们系统中ID生成器的设计如下所示。

- 整个ID的二进制长度为64位
- 前36位使用时间戳,以保证ID是升序增加
- 中间13位是分库标识,用来标识当前这个ID对应的记录在哪个数据库中
- 后15位为自增序列,以保证在同一秒内并发时,ID不会重复。每个分片库都有一个自增序列表,生成自增序列时,从自增序列表中获取当前自增序列值,并加1,做为当前ID的后15位
- 下一秒时,后15位的自增序列再次从1开始。
水平分库是一个极具挑战的项目,我们整个团队也在不断的迎接挑战中快速成长。
为了适应公司业务的不断发展,除了在MySQL数据库上进行相应的架构升级外,我们还搭建了一套完整的大数据实时分析统计平台,在系统中对用户的行为进行实时分析。
关于如何搭建大数据实时分析统计平台,对用户的行为进行实时分析,我们后面再详细介绍。
好了,今天就到这儿吧,我是冰河,我们下期见!!
重磅福利
微信搜一搜【冰河技术】微信公众号,关注这个有深度的程序员,每天阅读超硬核技术干货,公众号内回复【PDF】有我准备的一线大厂面试资料和我原创的超硬核PDF技术文档,以及我为大家精心准备的多套简历模板(不断更新中),希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
另外,我开源的各个PDF,后续我都会持续更新和维护,感谢大家长期以来对冰河的支持!!
从零到千万用户,我是如何一步步优化MySQL数据库的?的更多相关文章
- 如何设置FreePBX的数据库用户可以通过远程来连接Mysql数据库?
要满足mysql允许通过除了本机外的主机进行使用客户端连接的方法: 要设置root用户允许通过外网用户进行连接访问的操作方法: 1.首先先改mysql的配置文件 将绑定的#bind-address = ...
- Serv-u Mysql数据库用户
Serv-u 关联Mysql数据库用户需要用到ODBC数据源,windows不自带支持MySQL.所以要网上下载自己安装 官网下载地址:http://dev.mysql.com/downloads/c ...
- 第二百七十六节,MySQL数据库,【显示、创建、选定、删除数据库】,【用户管理、对用户增删改查以及授权】
MySQL数据库,[显示.创建.选定.删除数据库],[用户管理.对用户增删改查以及授权] 1.显示数据库 SHOW DATABASES;显示数据库 SHOW DATABASES; mysql - 用户 ...
- Mysql数据库用户及用户权限管理,Navicat设置用户权限
Mysql数据库用户及用户权限管理,Navicat设置用户权限 一.Mysql数据库的权限 1.1 mysql数据库用户权限级别 1.2 mysql数据库用户权限 1.3 存放用户权限表的说明 二.用 ...
- SHA-1退休:数千万用户通向加密网站之路被阻
Facebook和Cloudflare警告道:上千万用户将无法访问只使用SHA-2签名证书的HTTPS网站.2016年-2017年是SHA-1算法的缓冲期.2017年开始CA机构将不能颁发含有sh ...
- 深喉起底APP线下预装市场,如何一夜间拥有千万用户
注:预装对于中国的移动互联网创业者有多重要?i黑马知道这样一个内幕,某商务告诉我他们公司的前2000万用户就是靠预装打下来的,总部在北京,直接派驻商务长期扎根在深圳搞定手机厂商.而这家公司初期发展得益 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- SQL注入—我是如何一步步攻破一家互联网公司的
最近在研究Web安全相关的知识,特别是SQL注入类的相关知识.接触了一些与SQL注入相关的工具.周末在家闲着无聊,想把平时学的东东结合起来攻击一下身边某个小伙伴去的公司,看看能不能得逞.不试不知道,一 ...
随机推荐
- 【题解】[USACO12JAN]Video Game G
第一道\(AC\)自动机\(+DP.\) 首先,一个自动机上\(DP\)的套路是设\(dp[i][j]\)表示长度为\(i\)匹配到\(j\)节点的最优得分. 那么,由于我们已经建好了\(Trie\) ...
- 2020武汉dotNET俱乐部分享交流活动正式启动
去年9月去上海参加了2019 .NET开发者峰会,感触良多.回来后便一直想着在武汉也组织一场这样的活动,推动一下武汉.NET的发展.由于疫情的影响,这个想法一直被搁浅,好在疫情总算是控制住了,所以我们 ...
- 题解:SDOI2017 新生舞会
题解:SDOI2017 新生舞会 Description 学校组织了一次新生舞会,Cathy 作为经验丰富的老学姐,负责为同学们安排舞伴. 有 \(n\) 个男生和 \(n\) 个女生参加舞会.一个男 ...
- java怎么产生随机数
随机数的产生在一些代码中很常用,也是我们必须要掌握的.而java中产生随机数的方法主要有三种: 第一种:new Random() 需要借助java.util.Random类来产生一个随机数发生器,也是 ...
- pytest使用小结
一.pytest简洁和好处 自动发现测试用例 testloader 断言方便 ,自定义错误提示 assert 正则匹配 灵活运行指定的测试用例,指定模块,制定测试类,测试用例 -k 标签化,回归 正向 ...
- kafka生产者 消费者
publisher.php <?php $rk = new RdKafka\Producer(); $rk->addBrokers("192.168.33.50"); ...
- docker系统化学习图文教程
1.背景 在实际开发中我们经常遇到这样的情况: 1.开发的时候测试好的程序已发布到线上就出问题: 2.线上的集群环境需要扩容时非常麻烦,比如说要装jdk.mysql.redis等,如果扩容100台服务 ...
- linux(centos8):firewalld使用ipset管理ip地址的集合
一,firewalld中ipset的用途: 1,用途 ipset是ip地址的集合, firewalld使用ipset可以在一条规则中处理多个ip地址, 执行效果更高 对ip地址集合的管理也更方便 2 ...
- 第三十三章 linux常规练习题(二)
一.练习题一 1.删除用户基本组shanghai03.发现无法正常删除,怎样才能将其删除掉,不能删除用户.2.打开多个xshell窗口连接登录同一虚拟机,使用不同的用户登录多次,分别使用w和who命令 ...
- MVC注册
前言 最近没什么写的,写个MVC注册巩固一下 HTML @{ Layout = null; } <!DOCTYPE html> <html> <head> < ...