schema与数据类型优化-高性能mysql
总结作为开发人员重点注意的内容!这是一篇有关高性能MYSQL第四章schema相关的笔记。
0.前言
在项目中,数据库表列有两个text字段,用来存储大文本,在数据规模达到40万后,如果查询没命中索引,发现耗时会达到5s以上,在表中删除这两个大字段后,就算全表扫描,耗时也不过0.6s左右。
解决方案:
- 将这类不常参加查询的大字段放入详情表中,但对现有程序影响过大(懒)。
- 查询字段统统加上索引。
1.选择合适的数据类型
- 选择合适的数据范围,能用 tinyint 不用 int。
- 字段越简单越好。存储时间使用datetime而不是字符串,存储ip用整数而不用字符串。
- 尽量避免null。null 会使索引更加复杂,null改为not null性能提升较小,但设计时,逻辑上不可能为null的值,最好加上not null限制。
datetime 和 timestamp 比较
相同点: 都能存储日期、时间,精确到秒。
不同点: timestamp 只占 datetime 一半存储空间,具备时区功能,同时允许的时间范围小得多。
1.1.1 整数类型
类型及存储空间
- tinyint(1字节)
- smallint(2字节)
- mediumint(3字节)
- int(4字节)
- bigint(8节字)
int(11) 其中11只是指定显示宽带,对存储空间无任何影响。
可以指定类型为unsinged,但java不支持unsinged, 使用相同类型可能会有麻烦。
1.1.2 实数类型
精确类型:decimal, 不精确类型: double, float。
decimal 支持存储和计算的精确。计算性能比浮点类型差一点。
decimal(11,4)表示支持4位精确小数,整数部分最多只能有7位数字。
decimal类型4个字节存储9个数字,decimal(18,9)占用9个字节,前面9位整数占4个字节,小数点1个字节,后面小数占4个字节。
mysql5.0版本及以上,decimal 最多存储65个数字。
浮点类型在表示同样范围,通常比decimal使用更少的空间。
在数据量比较大的情况下,可以用bigint代替decimal, 将小数的位数乘以相应的倍数转为bigint,可避免不精确的问题。
1.1.3字符串类型
varchar 和char
varchar存储可变长的字符串,使用额外的1个或两个字节额外存储空间,表示字符串的长度。
varchar在table指定row_format=fixed情况下,也是定长的,这会导致空间的浪费。
varchar(256)使用一个字节存储字符字符数。varchar(1000)使用两个字节存储字符数。
update varchar字段可能会导致列变得更长,innodb存储引擎会导致出现分裂页的情况出现,myisam将行拆分成不同的段存储。
varchar适用场景:最长字符串比平均字符串长度长很多。
char是定长的,不容易产生碎片,适用于存储密码或md5值, 或表示性别,F/M, varchar(1)需要两个字节,char(1)需要一个字节。
char 会截断末尾的空格。
varchar(5)和varchar(100)都能存储5个字符,但varchar(100)性能会比varchar(5)糟糕,所以最好选择合适的长度。
text与blob类型
text存储大文本,blob存储二进制数据。
大文本有关的类型: tinytext, smalltext, text, mediumtext, longtext。
二进制有关的类型: tinyblob, smallbolob, blob, mediumblob, longblob。
当text,blob太大时,会作为一个对象单独存储,行中使用指针指向数据位置。
个人建议少用或不用这种类型,或拆除到详情表,减少对查询带来影响
enum类型
字段定义:animal enum("dog", "fish", "cat")
enum 实际存储为整数,并在.frm文件中保存字符串-整数对应关系。
看个列子更容易明白:
create table enum_test(
id int auto_increment,
animal enum("dog", "fish", "cat"),
primary key(id)
);
insert into enum_test(animal)
values
("dog"),
("cat"),
("dog"),
("fish")
;
对该表进行查询:
select animal+0, animal
from enum_test
order by animal
;
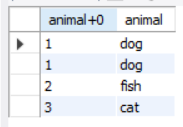
可以看到排序是按照整数排序的,即定义的顺序进行排序,而不是字符串序。
解决方案:定义时按照字符串序定义。
自定义顺序排序使用field函数,但这样将无法使用索引:
select animal+0, animal
from enum_test
order by field(animal, "cat", "fish", "dog");
字段join效率比较: enum join enum > varchar join varchar > enum join varchar = varchar join enum。
使用alter talbe 在枚举类型中添加字符串时,会重建整个表,除非总是在末尾添加值。
坏处:当枚举值为数字时,很容易发生困惑,尽量避免这种情况。
1.1.4 时间类型
datetime类型:
- 存储范围大: (1001年-9999年)精度为秒,将值存储为 YYYYMMDDHHMMSS的大整数中,占用八字节。
timestamp:
- 存储范围小:(1970年-2038年),精度为秒,存储从1970-1-1年以来的秒数,占用4字节。
- unix_timestamp()支持日期->秒数, from_unixtime()支持秒数->日期。
- 具备时区概念,在mysql服务器,操作系统,连接串都可以指定时区,推荐在连接串指定时区:(jdbc)serverTimezone=Asia/Shanghai
- 插入时没有指定会使用当前时间作为默认值
不推荐自己使用整数值来存储时间,这和内部存储没什么差别,没带来什么好处却多了额外的处理逻辑。
书中推荐使用timestamp, 个人推荐使用datetime,timestamp花活太多。
1.1.5 位数据类型
bit类型
bit列可以存储多个true/false值,bit(17)可以存储17个true/false值,myisam 使用一个比特来存储一个单独的true/false值,innodb使用最小的整数值来存储bit列的值。
myisam: bit(17)使用17个比特存储。
innodb: tinyint 即可存储。
高性能mysql认为应该慎用这个类型,所以就不深究了。
set 类型
好处: 存储使用打包的位存储,占用空间少。
坏处: 无法通过索引查找,修改列定义代价较高:需要alter table。
权限控制使用例子:
create table acl_test(
id int not null auto_increment,
perms set('can_read', 'can_write', 'can_delete'),
primary key(id)
);
insert into acl_test(perms)
values
('can_read,can_write'),
('can_read,can_delete')
;
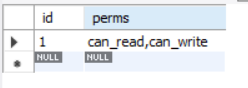
select *
from acl_test
where find_in_set('can_write', perms)
;
查询结果:
1.1.6 主键及其他
主键最好选择自增id为主键,对数据性能比较好,同时相对应orm也支持,可能存在某些orm层框架不支持联合主键的情况。
ip与int转换函数: inet_aton(), inet_ntoa()。
1.2 schema错误设计
- 列太多(几千个列)
- join 太多,mysql 限制最多可以join 61张表,实际为了性能考虑,最好一次查询join不超过12张表
- 错误使用枚举, 如一个枚举字段存储国家,枚举值有几十上百个, 更好的解决办法是使用关联表去存储国家信息,用整数去映射。
schema与数据类型优化-高性能mysql的更多相关文章
- mysql笔记01 MySQL架构与历史、Schema与数据类型优化
MySQL架构与历史 1. MySQL架构推荐参考:http://www.cnblogs.com/baochuan/archive/2012/03/15/2397536.html 2. MySQL会解 ...
- MySQL Schema与数据类型优化
Schema与数据类型优化 选择优化的数据类型 1.更小的通常更好 更小的数据类型通常更快,因为它们占用更少的磁盘,内存和CPU缓存 2.简单就好 简单数据类型的操作通常需要更少的CPU周期.例如:整 ...
- Schema 与数据类型优化
这是<高性能 MySQL(第三版)>第四章<Schema 与数据类型优化>的读书笔记. 1. 选择优化的数据类型 数据类型的选择原则: 越小越好:选择满足需求的最小类型.注意, ...
- 深入学习MySQL 03 Schema与数据类型优化
Schema是什么鬼 schema就是数据库对象的集合,这个集合包含了各种对象如:表.视图.存储过程.索引等.为了区分不同的集合,就需要给不同的集合起不同的名字,默认情况下一个用户对应一个集合,用户的 ...
- MySQL设计之Schema与数据类型优化
一.数据类型优化 1.更小通常更好 应该尽量使用可以正确存储数据的最小数据类型,更小的数据类型通常更快,因为它们占用更少的磁盘.内存和CPU缓存,并且处理时需要的CPU周期更少,但是要确保没有低估需要 ...
- 高性能MySQL笔记 第4章 Schema与数据类型优化
4.1 选择优化的数据类型 通用原则 更小的通常更好 前提是要确保没有低估需要存储的值范围:因为它占用更少的磁盘.内存.CPU缓存,并且处理时需要的CPU周期也更少. 简单就好 简 ...
- Mysql高性能笔记(一):Schema与数据类型优化
1.数据类型 1.1.几个参考优化原则 a. 更小的通常更好 i.更小的数据类型,占用更少磁盘.内存和CPU缓存,需要的CPU周期更少 ii.如果无法确定哪个数据类型是最好的,就选择不会超过范围的最 ...
- 高性能mysql 第4章 Schema与数据类型优化
基本原则: 更小的通常更好:占用更少的磁盘 内存和cpu缓存.如varchar(2)和varchar(100). 简单就好:比如整形比字符型代价更低.使用日期型来存储日期而不是字符串.使用整形存储ip ...
- 高性能mysql读书笔记(一):Schema与数据类型优化
4.5 加快ALTER TABLE 操作的速度 原理: MySQL 的ALTER TABLE 操作的性能对大表来说是个大问题. MySQL 执行大部分修改表结构操作的方法是用新的结构创建一个空表,从旧 ...
随机推荐
- Vmware Tools is currently being installed on your system
问题描述: 使用虚拟机安装Ubuntu过程中一直停留在"PLEASE WAIT! Vmware Tools is currently being installed on your syst ...
- Angualr 内置工具-SelectionModel
SelectionModel: 被用来控制选中一个和多个item时候的逻辑.例如下拉菜单,复选框选中等,非常方便. 引入:import{SelectionModel}from'@angular/cdk ...
- Python_爬虫笔记_2018.3.19
Python_爬虫_笔记 1.前言 1.1爬虫用途: 网站采集.接口采集(地图(jis 热力学 屋里端口/协议).微信.知乎.) 1.2基本流程:网页下载(requests)+网页解析+爬虫调度 网页 ...
- conda / cuda / screen 常用命令总结
记录一些常用的 conda / cuda / screen 相关的命令,这些在跑深度学习代码时经常用到. conda 下面的命令在 Ubuntu 下的 4.8.3 版本 conda 均正确工作. 查看 ...
- tp5获取当前域名
//头部引入 use think\Request; //获取当前域名 $request = Request::instance(); $domain = $request->domain();
- QQ账号测试用例
- laradock使用问题汇总
laradock简介 一套完整的基于Docker的PHP开发环境.包含了预先打包的Docker镜像,所有预先配置都是为了提供一个完美的PHP开发环境(中文文档).PS: 不是最新版的 windows1 ...
- C语言讲义——指针函数和函数指针
指针函数 返回值是指针的函数,如void* malloc(...) #include<stdio.h> #include<stdlib.h> #include<strin ...
- B 站今日黑白页是怎么实现的?
今天是2020年4月4日哀悼活动,不少相关站点都将网站全部变为灰色,以表示哀悼.以下为CSS代码.直接在*.css文件最前面加入. <!-- 置为灰色 --> <style type ...
- 图解连接阿里云(一)创建阿里云物联网平台产品和设备,使用MQTT.fx快速体验
1. 打开 https://www.aliyun.com/ 注册账号 2.注册账号登录后点击控制台 3. 在下图1处输入物联网平台,会弹出2处所示物联网平台的入口,点击红色箭头所示处,进入物联网平 ...