数据可视化实例(十五):有序条形图(matplotlib,pandas)
偏差 (Deviation)
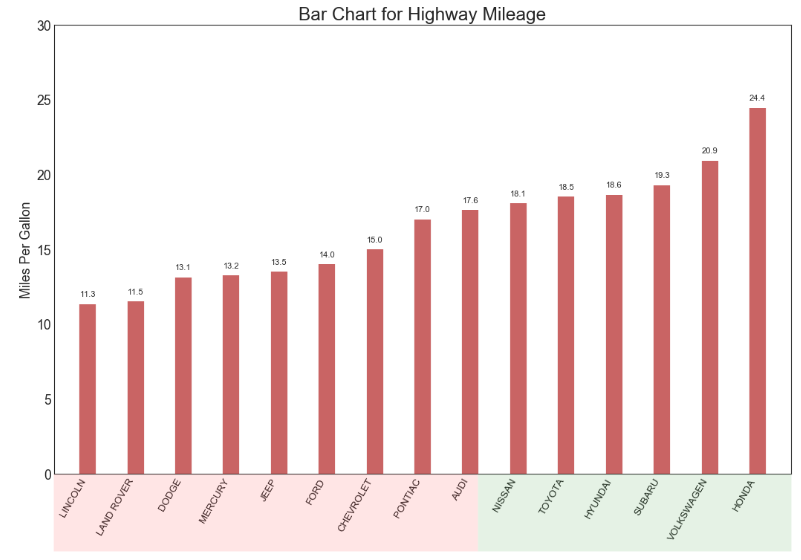
有序条形图 (Ordered Bar Chart)
有序条形图有效地传达了项目的排名顺序。 但是,在图表上方添加度量标准的值,用户可以从图表本身获取精确信息。
https://datawhalechina.github.io/pms50/#/chapter15/chapter15
导入所需要的库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
import matplotlib as mpl # 导入matplotlib库
import matplotlib.pyplot as plt
import seaborn as sns # 导入seaborn库
设定图像各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, # 设置子图上的标题字体
'legend.fontsize': med, # 设置图例的字体
'figure.figsize': (16, 10), # 设置图像的画布
'axes.labelsize': med, # 设置标签的字体
'xtick.labelsize': med, # 设置x轴上的标尺的字体
'ytick.labelsize': med, # 设置整个画布的标题字体
'figure.titlesize': large}
plt.rcParams.update(params) # 更新默认属性
plt.style.use('seaborn-whitegrid') # 设定整体风格
sns.set_style("white") # 设定整体背景风格
程序代码
# step1:导入数据
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x:x.mean())
df.sort_values('cty', inplace = True)
df.reset_index(inplace = True) # step2:绘制有序条形图
# 创建画布对象以及子图对象
fig,ax = plt.subplots(figsize = (16, 10), # 画布尺寸
facecolor = 'white', # 画布颜色
dpi = 80) # 分辨率
# 绘制柱状图
ax.vlines(x = df.index, # 横坐标
ymin = 0, # 柱状图在y轴的起点
ymax = df.cty, # 柱状图在y轴的终点
color = 'firebrick', # 柱状图的颜色
alpha = 0.7, # 柱状图的透明度
linewidth = 20) # 柱状图的线宽 # step3:添加文本
# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,
for i, cty, in enumerate(df.cty):
ax.text(i, # 文本的横坐标位置
cty+0.5, # 文本的纵坐标位置
round(cty, 1), # 对文本中数据保留一位小数
horizontalalignment = 'center') # 相对于xy轴,水平对齐 # step4:装饰
ax.set_title('Bar Chart for Highway Mileage', # 子图标题名称
fontdict = {'size': 22}) # 标题字体尺寸
ax.set(ylabel = 'Miles Per Gallon', # 纵坐标的标题名称
ylim = (0,30)) # 纵坐标的取值范围
# 横坐标的刻度标尺
plt.xticks(df.index, # 横坐标的刻度位置
df.manufacturer.str.upper(), # 刻度标尺的内容(先转化为字符串,再转换为大写)
rotation = 60, # 旋转角度
horizontalalignment = 'right', # 相对于刻度标尺右移
fontsize = 12) # 字体尺寸 # step5:添加补丁
# 添加绿色的补丁
p1 = patches.Rectangle((0.57, -0.005), # 矩形左下角坐标
width = 0.33, # 矩形的宽度
height = 0.13, # 矩形的高度
alpha = 0.1, # 矩阵的透明度
facecolor = 'green', # 是否填充矩阵(设置为绿色)
transform = fig.transFigure) # 保持矩形显示在图像最上方
# 添加红色的补丁
p2 = patches.Rectangle((0.124, -0.005), # 矩形左下角坐标
width = 0.446, # 矩形的宽度
height = 0.13, # 矩形的高度
alpha = 0.1, # 矩阵的透明度
facecolor = 'red', # 是否填充矩阵(设置为红色)
transform = fig.transFigure) # 保持矩形显示在图像最上方
# 将补丁添加至画布
fig.add_artist(p1) # 将p1添加至画布上
fig.add_artist(p2) # 将p2添加至画布上
plt.show() # 显示图像
matplotlib.pyplot.vlines
matplotlib.pyplot.vlines(x, ymin, ymax, colors='k', linestyles='solid', label='', *, data=None, **kwargs)[源代码]
绘制垂直线。
在每个位置绘制垂直线 x 从 ymin 到 ymax .
| 参数: |
|
|---|---|
| 返回: |
|
| 其他参数: |
|
数据可视化实例(十五):有序条形图(matplotlib,pandas)的更多相关文章
- 数据可视化实例(五): 气泡图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter2/chapter2 关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也 ...
- 【Matplotlib】数据可视化实例分析
数据可视化实例分析 作者:白宁超 2017年7月19日09:09:07 摘要:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息.但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令 ...
- 数据可视化实例(十六):有序条形图(matplotlib,pandas)
排序 (Ranking) 棒棒糖图 (Lollipop Chart) 棒棒糖图表以一种视觉上令人愉悦的方式提供与有序条形图类似的目的. https://datawhalechina.github.io ...
- 数据可视化实例(十二): 发散型条形图 (matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter10/chapter10 如果您想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么散型条 ...
- 数据可视化实例(十三): 发散型文本 (matplotlib,pandas)
偏差 (Deviation) https://datawhalechina.github.io/pms50/#/chapter11/chapter11 发散型文本 (Diverging Texts) ...
- 数据可视化基础专题(四):Pandas基础(三) mysql导入与导出
转载(有添加.修改)作者:但盼风雨来_jc链接:https://www.jianshu.com/p/238a13995b2b來源:简书著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处 ...
- 数据可视化基础专题(八):Pandas基础(七) 数据清洗与预处理相关
1.数据概览 第一步当然是把缺失的数据找出来, Pandas 找缺失数据可以使用 info() 这个方法(这里选用的数据源还是前面一篇文章所使用的 Excel ,小编这里简单的随机删除掉几个数据) i ...
- 数据可视化实例(十四):带标记的发散型棒棒糖图 (matplotlib,pandas)
偏差 (Deviation) 带标记的发散型棒棒糖图 (Diverging Lollipop Chart with Markers) 带标记的棒棒糖图通过强调您想要引起注意的任何重要数据点并在图表中适 ...
- 数据可视化实例(十四):面积图 (matplotlib,pandas)
偏差 (Deviation) 面积图 (Area Chart) 通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间. 高点持续时间越长,线下面积越大. https:/ ...
随机推荐
- 不知道这些,你以为你还能devops?
一.什么是devops 在DevOps之前,从业人员使用瀑布模型或敏捷开发模型进行软件项目开发:瀑布模型或顺序模型是软件开发生命周期(SDLC)中的一种开创性方法,在这个模型中,软件开发成为一个线性过 ...
- numpy中数组(矩阵)的乘法
我们知道在处理数据的时候,使用矩阵间的运算将会是方便直观的.matlab有先天的优势,算矩阵是它的专长.当然我们用python,经常要用到的可能是numpy这个强大的库. 矩阵有两种乘法,点乘和对应项 ...
- Linux 虚拟机详细安装MySQL
准备工作 下载MySQL 去官网下载MySQL:点我直达 百度云盘地址:链接: https://pan.baidu.com/s/1qBN4r6t8gvq-I4CFfQQ-EA 密码: hei3 检查L ...
- show and hide. xp扩展名
reg add "HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\Advanced" /v HideFileExt ...
- snprintf和sprintf区别分析
目录[-] snprintf函数的返回值 snprintf函数的字符串缓冲 今天在项目中使用snprintf时遇到一个比较迷惑的问题,追根溯源了一下,在此对sprintf和snprintf进行一下对比 ...
- linux网络编程-socket(37)
在编程的时候需要加上对应pthread开头的头文件,gcc编译的时候需要加了-lpthread选项 第三个参数是线程的入口参数,函数的参数是void*,返回值是void*,第四个参数传递给线程函数的参 ...
- 1.尚硅谷_MyBatis_简介.avi
hibernate旨在消除mysql语句.程序员不写sql语言,要实现复杂的功能需要学习hibernate的hql语句 mybatis把编写sql语言交给程序员,程序员自己在xml控制sql语句的编写 ...
- ATM项目分析
ATM项目分析 项目源代码下载 其实本项目的需求分析乍一看比较复杂,但是细细拆分出来实际实现还是比较容易的.基本用上前面所学的所有知识点. 1.额度 15000或自定义 2.实现购物商场,买东西加入购 ...
- Nginx深入学习(一篇搞定)
我们的口号是:人生不设限! 一.nginx简介 1.什么是nginx Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,特点是占有内存少,并发能力强,事实上nginx的并发 ...
- Day12-微信小程序实战-交友小程序-搭建服务器与上传文件到后端
要搞一个小型的cms内容发布系统 因为小程序上线之后,直接对数据库进行操作的话,慧出问题的,所以一般都会做一个管理系统,让工作人员通过这个管理系统来对这个数据库进行增删改查 微信小程序其实给我们提供了 ...