Linux graphics stack
2D图形架构
早期Linux图形系统的显示全部依赖X Server,X Client调用Xlib提供的借口向 X Server发送渲染命令,X Server根据 X Client的命令请求向硬件设备绘制图形,X Client与X Server之间通过X11协议通讯。通过这种方式,X Server屏蔽了所有的硬件差异,保证同一个X程序能够在不同的硬件设备上运行。
X Server需要与多种多样的硬件打交道,每个硬件提供自己的DDX驱动程序,X Server最后调用DDX的接口将图形发送给硬件设备。

3D图形架构
通过3D硬件执行3D加速能够大大提高绘制效率,根据不同的模式有两种架构:
Indirect Rendering
这种模式下,仅仅X Server能够访问3D硬件设备,X Client需要绘图时通过X11扩展协议将3D命令发送给X Server,然后由X Server控制3D硬件设备执行,这种模式称为“非直接渲染”。
这种模式与2D模式类似。
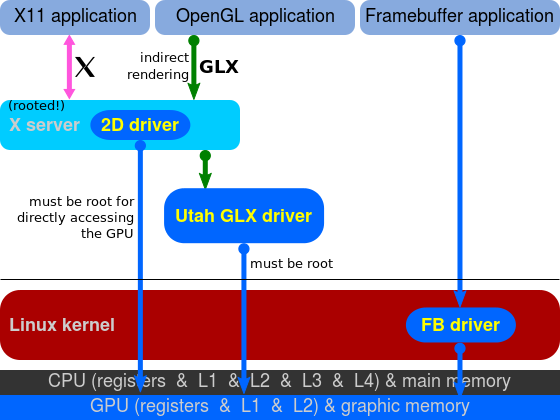
但是这种模式无法发挥出3D硬件的效率
Direct Rendering
DRI(Direct Rendering Infrastructure)架构允许X Client直接控制3D硬件设备,所以这种模式下要求X Client与X Server必须位于同一个设备上。
DRM(Direct Rendering Manager)是DRI架构下的Kernel实现,DRM负责:hardware locking, access synchronization, video memory and more.
DRM also provides userspace with an API that it can use to submit commands and data in a format that is adequate for modern GPUs, which effectively allows userspace to communicate with the graphics hardware.
Notice that many of these things have to be done specifically for the target hardware so there are different DRM drivers for each GPU.
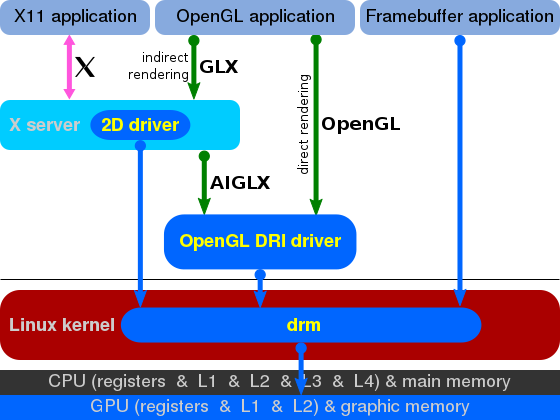
DRI/DRM provide the building blocks that enable userspace applications to access the graphics hardware directly in an efficient and safe manner, but in order to use OpenGL we need another piece of software that, using the infrastructure provided by DRI/DRM, implements the OpenGL API while respecting the X server requirements.
Mesa
Mesa is a free software implementation of the OpenGL specification, and as such, it provides a libGL.so, which OpenGL based programs can use to output 3D graphics in Linux. Mesa can provide accelerated 3D graphics by taking advantage of the DRI architecture to gain direct access to the underlying graphics hardware in its implementation of the OpenGL API.
When our 3D application runs in an X11 environment it will output its graphics to a surface (window) allocated by the X server. Notice, however, that with DRI this will happen without intervention of the X server, so naturally there is some synchronization to do between the two, since the X server still owns the window Mesa is rendering to and is the one in charge of displaying its contents on the screen. This synchronization between the OpenGL application and the X server is part of DRI. Mesa’s implementation of GLX (the extension of the OpenGL specification that addresses the X11 platform) uses DRI to talk to the X server and accomplish this.
Mesa also has to use DRM for many things. Communication with the graphics hardware happens by sending commands (for example “draw a triangle”) and data (for example the vertex coordinates of the triangle, their color attributes, normals, etc). This process usually involves allocating a bunch of buffers in the graphics hardware where all these commands and data are copied so that the GPU can access them and do its work. This is enabled by the DRM driver, which is the one piece that takes care of managing video memory and which offers APIs to userspace (Mesa in this case) to do this for the specific target hardware. DRM is also required whenever we need to allocate and manage video memory in Mesa, so things like creating textures, uploading data to textures, allocating color, depth or stencil buffers, etc all require to use the DRM APIs for the target hardware.
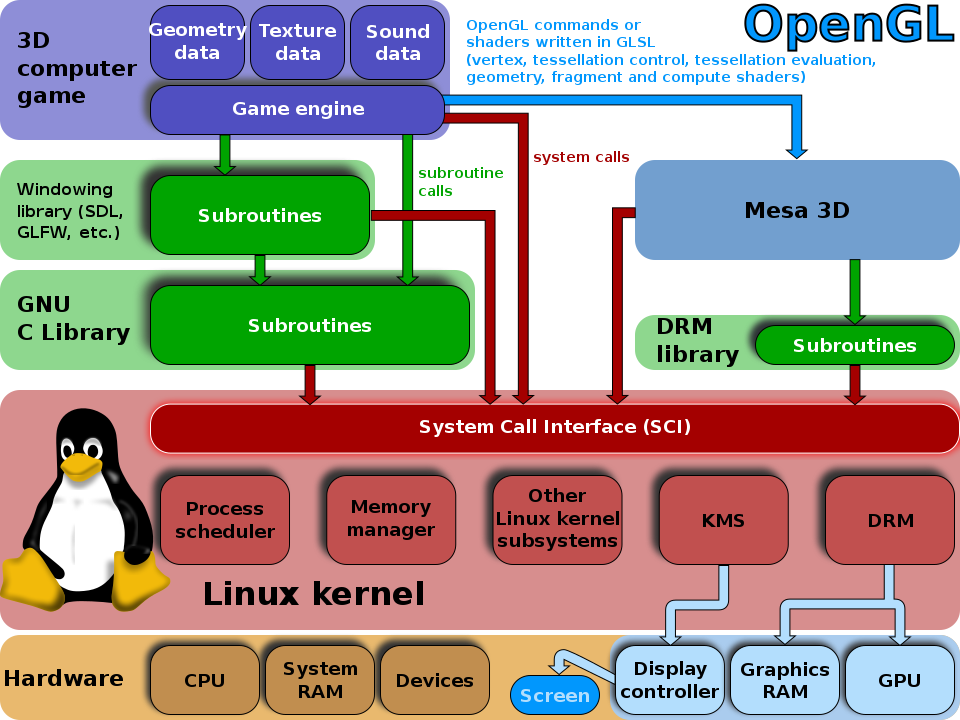
引用原文:https://blogs.igalia.com/itoral/2014/07/29/a-brief-introduction-to-the-linux-graphics-stack/
Linux graphics stack的更多相关文章
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
http://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/ ...
- Queueing in the Linux Network Stack !!!!!!!!!!!!!!!
https://www.coverfire.com/articles/queueing-in-the-linux-network-stack/ Queueing in the Linux Networ ...
- Linux Storage Stack Diagram存储堆栈图
这是一个描述非常好的存储栈,版本为:Linux Storage Stack Diagram v4.10,我在这里转载下图片,可以提升大家对存储栈的理解. https://www.thomas-kren ...
- Linux Kernel Stack
整理一些杂乱的内容.以下x86架构. Linux 内核栈大小 内核栈大小是固定的,默认为8k,曾经有选项可以设置为4k栈.由于大小固定,申请过大的栈内存,或者函数调用层次过深,都可能导致栈溢出. 关注 ...
- 《Monitoring and Tuning the Linux Networking Stack: Receiving Data》翻译
Overview 从宏观的角度来看,一个packet从网卡到socket接收缓冲区的路径如下所示: 驱动加载并初始化 packet到达网卡 packet通过DMA被拷贝到内核中的一个ring buff ...
- The Linux Storage Stack Diagram
相关文章: 如何提高Linux下块设备IO的整体性能?
- linux io stack
- The Linux Storage Stack Diagram 内核 4.0 版的 I/O 栈
- Linux Storage Stack Diagram 4.0
https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
随机推荐
- linux虚拟摄像头vivid配置
总述 最近在看摄像头驱动,需要配置虚拟摄像头的驱动,但是教程里面是linux2.6内核的,实际电脑的是Ubuntu16,内核是linux4.15版本,从2.6到4.15内核好多文件发生了变化,所 ...
- jRating五星评级
<!DOCTYPE html> <html> <head> <title>jrating使用示例</title> <meta char ...
- 2020牛客暑期多校训练营(第四场)BCFH
BCFH B. Basic God Problem 题意 给出c和n,求fc(n). 题解 递归到最后 fc 函数肯定等于1,那么就变成了求c被乘了几次,只要找到 x 最多能被分解成多少个数相乘就好了 ...
- Codeforces Round #686 (Div. 3) E. Number of Simple Paths (思维,图,bfs)
题意:有一个\(n\)个点,\(n\)条边的图,问你长度至少为\(1\)的简单路径有多少条. 题解:根据树的性质,我们知道这颗树一定存在一个环,假如一棵树没有环,那么它的所有长度不小于\(1\)的简单 ...
- Codeforces #6241 div2 C. Orac and LCM (数学)
题意:给你一个数列,求所有子序列对的\(lcm\),然后求这些所有\(lcm\)的\(gcd\). 题解:我们对所有数分解质因数,这里我们首先要知道一个定理: 对于\(n\)个数,假如某个质数\( ...
- 在Ubuntu虚拟机上搭建青岛OJ
源码地址为:https://github.com/QingdaoU/OnlineJudge 可参考的文档为:https://github.com/QingdaoU/OnlineJudgeDeploy/ ...
- Docker文件挂载总结
Docker容器启动的时候,如果要挂载宿主机的一个目录,可以用-v参数指定. 譬如我要启动一个centos容器,宿主机的/test目录挂载到容器的/soft目录,可通过以下方式指定: # docker ...
- spring再学习之AOP准备
一.aop思想: 横向重复,纵向抽取 1.乱码 2.事务管理 3,action 二.spring能够为容器中管理的对象生成代理对象 1.spring能帮我们生成代理对象 2.spring实现aop的原 ...
- CS144学习(1)Lab 0: networking warmup
CS144的实验就是要实现一个用户态TCP协议,对于提升C++的水平以及更加深入学习计算机网络还是有很大帮助的. 第一个Lab是环境配置和热身,环境按照文档里的配置就行了,前面两个小实验就是按照步骤来 ...
- SPOJ REPEATS Repeats (后缀数组 + RMQ:子串的最大循环节)题解
题意: 给定一个串\(s\),\(s\)必有一个最大循环节的连续子串\(ss\),问最大循环次数是多少 思路: 我们可以知道,如果一个长度为\(L\)的子串连续出现了两次及以上,那么必然会存在\(s[ ...